Материал: Огурцов А. Н. Методы бииоинформационного анализа
интересующей нас последовательности с очень длинной последователь- |
Оказывается не нужно, поскольку выбор оптимального пути из |
ностью, длина которой равна всей базе данных. |
точки "А" в конец не зависит от выбора пути из начала в "А". |
Схема, содержащая все возможные выравнивания, может быть |
Если мы определяем оптимальный из 6 путей, ведущих от |
построена в виде матрицы, подобной той, которая используется для |
начальной точки в точку "А", а также оптимальный из путей от "А" к |
изображения точечной матрицы сходства. Элементы одной последова- |
концу, то оптимальный путь от начала к концу, проходящий через "А", |
тельности (нуклеотиды или аминокислоты) индексируют строки, а |
будет определяться как оптимальный путь от начала к "А" и следующий |
элементы другой последовательности – столбцы. Любой путь по матрице, |
за ним оптимальный путь от "А" к конечной точке. |
начинающийся в левом верхнем углу и заканчивающийся в правом |
В этом случае нужно рассматривать уже не более 12 путей, |
нижнем, соответствует одному выравниванию (см. рисунок 11). Задача |
проходящих через точку "А" – 6 путей от точки (0,0) до "А", |
состоит в том, чтобы найти путь наименьшего веса, и трудность состоит в |
продолжающихся самым оптимальным из путей от "А" до конца; плюс |
том, что таких путей нужно рассмотреть очень много. |
ещё 6 путей от "А" до конца, продолжающих единственный оптимальный |
Для понимания основной идеи динамического программирования |
путь от начала к "А". |
рассмотрим элементарный пример "перемещения" по графу 5×5 из |
В этом и заключается преимущество метода динамического |
начальной точки (0,0) в конечную точку (4,4) (рисунок 14(а)). |
программирования – задача систематически разделяется на всё более |
|
мелкие части (рисунок 15). И тем самым сокращается объём необходимых |
|
вычислений. |
а |
б |
|
Рисунок 14 – Модельный граф: а – схема; б – пути из точки (0,0) в точку А |
|
|
Существует 6 путей из начальной точки (0,0) в точку "А" (рису- |
|
|
нок 14(б)). Исходя из симметрии, |
существует также и 6 путей из точки |
|
"А" в конечную точку (4,4), а общее число путей из начала в конец, |
|
|
проходящих через точку "А", равно 36. |
|
|
Пусть, далее, мы присвоили цены отдельным этапам. Вопрос |
|
|
заключается в том, нужно ли нам проверять все 36 путей для нахождения |
|
|
оптимального, который проходит из начала в конец через точку "А"? |
Рисунок 15 – Разбиение задачи оптимального выравнивания на подпрограммы |
|
|
60 |
61 |
Алгоритм глобального выравнивания двух биологических последовательностей методом динамического программирования был впервые предложен C.Б. Нидлманом и К.Д. Вуншем (S.B. Needleman & C.D. Wunsch). Для идентификации локального совпадения подобный алгоритм был впервые использован Т. Смитом и М. Уотерманом (T. Smith & M. Waterman).
3.2. АЛГОРИТМ ГЛОБАЛЬНОГО ВЫРАВНИВАНИЯ
Алгоритм глобального выравнивания Нидлмена-Вунша методом динамического программирования заключается в построении на данном этапе оптимального выравнивания, используя полученные на предыдущих этапах оптимальные выравнивания начальных фрагментов исходных последовательностей.
Для двух выравниваемых последовательностей x и y с элементами xi (0 <i < n ) и y j (0 < j < m ) мы строим матрицу F . Элемент F(i, j) этой матрицы содержит вес (счёт, score) наилучшего выравнивания начальных фрагментов x1…i (длиной i ) и y1…j (длиной j ) последовательностей x и y , соответственно. Матрицу F мы строим рекурсивно. Начинаем с того, что присваиваем начальной точке нулевой вес F(0,0) =0 . Далее мы заполняем матрицу в порядке возрастания обоих индексов, то есть с верхнего левого угла к нижнему правому. Если уже известны
F(i −1, j −1) , F(i −1, j) и F(i, j −1) , то можно вычислить F(i, j) .
Возможны три варианта получения веса F(i, j) в соответствии с тремя возможными вариантами выравнивания, представленными на рисунке 16.
Элемент xi одной последовательности может быть выровнен с элементом y j второй последовательности (рисунок 16(а)), и тогда к значению веса F(i −1, j −1) добавляем очки за выравнивание s(xi , y j ) (например, из матрицы BLOSUM)
F(i, j) = F(i −1, j −1) + s(xi , y j ) .
62
I G A |
xi |
A I G A |
xi |
G A xi - - |
L G V |
y j |
G V y j - |
- |
S L G V y j |
а |
б |
в |
Рисунок |
16 – Три способа продолжения выравнивания |
до точки (i, j) : |
а – элемент xi выровнен с y j ; б – элементу xi сопоставлен пропуск (gap); в – элементу y j сопоставлен пропуск
Если же элементу xi одной последовательности сопоставлен пропуск (gap) "–" во второй последовательности (рисунок 16(б)), то за это "начисляется" штраф d
F(i, j) = F(i −1, j) −d .
В случае, когда элементу y j сопоставлен пропуск в последовательности x (рисунок 16(в)), также "начисляется" штраф
F(i, j) = F(i, j −1) −d .
Наибольший вес выравнивания двух фрагментов последовательностей x1…i (длиной i ) и y1…j (длиной j ) определяется как максимум этих
трёх вариантов
F(i −1, j −1) + s(xi , y j ), F(i, j) = max F(i −1, j) −d,
F(i, j −1) −d.
Такую рекурсивную процедуру повторяем, последовательно увеличивая номер строки i (а внутри строки – последовательно увеличивая номер столбца j ), до тех пор, пока не будет заполнена вся матрица F(i, j) .
Рассмотрим "квадрат", состоящий из четырёх соседних ячеек матрицы (рисунок 17).
63

Рисунок 17 – Три варианта получения веса F(i, j)
Каждое последующее значение F(i, j) в правом нижнем углу каждого такого "квадрата" из четырёх ячеек определяется из одной из оставшихся трёх ячеек (показано стрелками на рисунке 17).
При заполнении матрицы F одновременно с вычислением значений F(i, j) необходимо запоминать, по какому из трёх "путей" (из какой клетки на рисунке 17) было получено это конкретное значение F(i, j) . Такое запоминание впоследствии, после заполнения всей матрицы, нужно для восстановления "маршрута" выборов.
Прежде чем закончить описание алгоритма необходимо определить граничные условия – процедуру заполнения ячеек верхней строки ( j =0) и левой колонки (i =0) .
Поскольку вдоль верхней строки, где ( j =0) , получение значений F(i,0) при движении слева направо (горизонтальная стрелка на рисунке 17) соответствует вставкам пропусков в последовательность y , то устанавливаем
F(i,0) = −d .
Аналогично вдоль левой колонки с (i =0)
F(0, j) = −d .
64
Значение правой нижней ячейки матрицы F(n,m) по определению является наилучшим весом выравнивания двух последовательностей x1…i и y1…j . Для построения самого выравнивания необходимо восстановить последовательность выборов, которая и привела от начальной точки (0,0) к финальной точке (n,m).
Процедура восстановления выборов называется процедурой обратного прохода (traceback procedure). Она осуществляется построением выравнивания с конца, от правой нижней ячейки матрицы с координатами (n,m) следуя тем указателям шагов, которые были получены при построении матрицы.
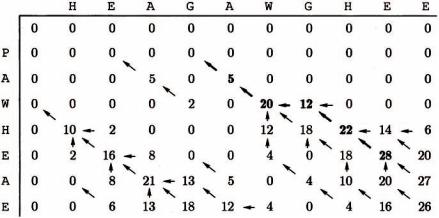
На рисунке 18 представлена таблица динамического программирования глобального выравнивания двух последовательностей
x= HEAGAWGHEE y = PAWHEAE,
рассчитанная на основе матрицы замен BLOSUM50 и значения величины штрафа d =8 .
Рисунок 18 – Глобальное выравнивание методом Нидлмена-Вунша
65

Стрелками на рисунке 18 показаны указатели для процедуры обратного прохода. Значения, соответствующие оптимальному выравниванию выделены жирным шрифтом. Оптимальное выравнивание этих двух последовательностей с весом 1, построенное с помощью процедуры обратного прохода имеет вид
x : HEAGAWGHE-E y : --P-AW-HEAE.
На каждом шаге процедуры обратного прохода мы движемся от текущей ячейки (i, j) "обратно" к одной из ячеек (i −1, j −1) , (i −1, j) , (i, j −1) из которых и было вычислено значение веса F(i, j) .
При этом мы добавляем слева к текущему выравниванию пару символов
• |
xi |
– если вес был получен из ячейки (i −1, j −1) |
|
y j |
|
|
(диагональная стрелка); |
|
•x−i – если вес был получен из ячейки (i −1, j)
(горизонтальная стрелка);
• |
− |
– если вес был получен из ячейки (i, j −1) |
y j |
(вертикальная стрелка).
В конце выравнивания мы достигаем левого верхнего угла матрицы (0,0).
3.3. АЛГОРИТМ ЛОКАЛЬНОГО ВЫРАВНИВАНИЯ
Алгоритм Смита-Уотермана используют в случае, когда необходимо найти оптимальное выравнивание подпоследовательностей (subsequences) исходных последовательностей x и y , например, когда производится поиск общих доменов у белков.
66
Локальное выравнивание также является эффективным способом обнаружения сходства при сравнении сильно дивергировавших последовательностей.
Наилучшим локальным выравниванием называется выравнивание подпоследовательностей x и y с самым большим весом.
В целом алгоритм локального выравнивания подобен алгоритму глобального выравнивания, но в нём существуют два отличия.
Первое отличие – для получения значения веса для каждого элемента матрицы динамического программирования добавлена возмож-
ность присвоения нулевого веса F(i, j) =0 в случае, если все остальные варианты выбора дают отрицательные значения
0,
F(i, j) = max F(i −1, j −1) + s(xi , y j ),
F(i −1, j) −d,F(i, j −1) −d.
Если наилучшее выравнивание на данном этапе имеет отрицательный вес, то лучше начать новое выравнивание, чем продолжать старое. Всякий раз, когда наилучший вес в ячейке матрицы оказывается отрицательным, в ячейку записывается 0 и ставится метка, что отсюда дальше пути нет, и что начинается новое выравнивание.
Вследствие добавления нового "нулевого" выбора, элементы верхней строки и левого столбца в данном алгоритме также приравниваются нулю, а не −id и − jd , как при глобальном выравнивании.
В результате любая подпоследовательность может "скользить" вдоль другой перед началом выравнивания без прибавления штрафов за вставки пропусков (делеции) оставленные позади.
Второе отличие – выравнивание может закончится в любом месте таблицы, а не только в правом нижнем углу, как в случае глобального выравнивания. Таким образом, вместо F(n,m) наилучшим весом при
67
локальном выравнивании может быть наибольшее значение F(i, j) в матрице, и процедуру обратного прохода нужно начинать именно с этого места.
На рисунке 19 показан пример нахождения локального выравни-
вания
AWGHE
AW-HE
тех же последовательностей, для которых на рисунке 18 было найдено глобальное выравнивание. В данном случае локальное выравнивание оказалось подмножеством глобального выравнивания. Однако это не всегда так.
Рисунок 19 – Локальное выравнивание методом Смита-Уотермана
В настоящее время в программах осуществляющих поиск локальных совпадения используют модифицированные алгоритмы СмитаУотермана, в которых используются аффинные функции штрафов за разрывы.
68
3.4.ПРИБЛИЖЁННЫЕ МЕТОДЫ ДЛЯ БЫСТРОГО ПОИСКА
ВБАЗАХ ДАННЫХ
По общепринятой практике гены из нового генома сравниваются со всеми последовательностями из базы данных.
Сначала обычно используют приближённые методы, которые могут работать хорошо и быстро для поиска похожих последовательностей, однако при поиске очень отдалённых связей они могут работать хуже, чем точные методы.
На практике приближённые методы дают удовлетворительный результат во многих случаях, когда последовательность запроса достаточно похожа на одну или несколько последовательностей в базе данных, и поэтому имеет смысл пробовать их первыми.
Типичный приближённый подход выбирает некое малое целое значение k и находит все подстроки длиной k символов в последовательности запроса, которые появляется также в какой-либо последовательности в базе данных.
Такая короткая идентичная последовательность называется "слово" или "k-кортеж" ("k-tuple").
В математике кортежем называют последовательность конечного числа элементов. В некоторых языках программирования кортеж является особым типом структуры данных. В языке Python кортеж (англ. tuple) отличается от списка тем, что кортеж нельзя изменять.
Само слово "tuple" – это своеобразный обобщающий "суффикс" в
перечислении слов всё большей длины: single, double, triple, quadruple, quintuple, sextuple, septuple, octuple, ..., n-tuple, ...
Последовательность-кандидат – это последовательность в базе данных, содержащая большое число подходящих k-кортежей.
Затем для отобранного набора последовательностей-кандидатов производятся вычисления приближённого оптимального выравнивания с временным и пространственным ограничением, которое предусматривали проходы по матрице в пределах диагоналей, содержащих многочисленные совпадающие наборы k-кортежей.
69