Материал: Огурцов А. Н. Методы бииоинформационного анализа
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ, МОЛОДЁЖИ И СПОРТА УКРАИНЫ
НАЦИОНАЛЬНЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ «Харьковский политехнический институт»
А. Н. Огурцов
МЕТОДЫ
БИОИНФОРМАЦИОННОГО
АНАЛИЗА
Учебное пособие по курсу «Биоинформатика и информационная биотехнология»
для студентов направления подготовки 051401 «Биотехнология», в том числе для иностранных студентов
Утверждено редакционно-издательским советом университета, протокол № 1 от 23.06.2011 г.
Харьков НТУ «ХПИ»
2011
ББК 28.071.3 О 39
УДК 577.3
Рецензенты:
В.А. Карачевцев, д-р физ.-мат. наук, зав. отд. молекулярной биофизики ФТИНТ им. Б.И. Веркина НАН Украины
В. В. Давыдов, д-р. мед. наук, проф., зав. лаб. возрастной эндокринологии
иобмена веществ ГП "Институт охраны здоровья детей
иподростков АМН Украины"
Навчальний посібник містить матеріали з основних питань другого розділу курсу «Біоіформатика та інформаційна біотехнологія» відповідно до програми підготовки студентів напряму «Біотехнологія».
Призначено для студентів спеціальностей біотехнологічного профілю всіх форм навчання.
Огурцов А. Н.
О 39 Методы биоинформационного анализа: учеб. пособие по курсу «Биоинформатика и информационная биотехнология» для студ. направл. подг. 051401 «Биотехнология», в т. ч. иностр. студ. / А. Н. Огурцов. – Харьков. : НТУ «ХПИ», 2011. – 114 с. – На рус. яз.
ISBN 978-966-593-931-3
Учебное пособие содержит материалы по основным вопросам второго раздела курса «Биоинформатика и информационная биотехнология» в соответствии с программой подготовки студентов направления «Биотехнология».
Предназначено для студентов специальностей биотехнологического профиля всех форм обучения.
Ил. 31. Табл. 10. Библиогр.: 26 назв.
ББК 28.071.3 УДК 577.3
ISBN 978-966-593-931-3 |
© А.Н. Огурцов, 2011 |
ВСТУПЛЕНИЕ
Предметом учебной дисциплины "Биоинформатика и информационная биотехнология" являются компьютерно-ориентированные методы решения информационных задач в области биотехнологии. Курс "Биоинформатика и информационная биотехнология" состоит из четырёх разделов: введение в биоинформатику, методы биоинформационного анализа, информационные принципы в биотехнологии, биоинформационные Интернет-ресурсы. Научную основу курса "Биоинформатика и информационная биотехнология" составляют молекулярная биофизика, молекулярная биология и генетика.
Методическими основами курса являются лекции, в которых излагаются основные положения каждого раздела, практические занятия и самостоятельная работа студентов, являющаяся основным способом усвоения материала в свободное от аудиторных занятий время.
Для самостоятельной работы выделяется больше половины общего объема времени, предназначенного для изучения данной дисциплины. Самостоятельная работа проводится по всем темам, входящим в дисциплину. В процессе самостоятельной работы студент учится самостоятельно приобретать знания, которые затем используются в ходе выполнения индивидуального задания, практических занятий, при подготовке к выполнению контрольных работ и к экзамену.
3
Настоящее пособие подготовлено на основе адаптированных работ [1–26], послуживших также источником иллюстраций, таким образом, чтобы максимально облегчить усвоение раздела "Методы биоинформационного анализа" курса "Биоинформатика и информационная биотехнология" студентам направления подготовки 051401 "Биотехнология". Перед работой с пособием следует внимательно изучить материал пособий [1–5], без которого невозможно понимание методов и алгоритмов, определяющих информационную составляющую биотехнологии.
1. АНАЛИЗ БИОЛОГИЧЕСКИХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
1.1. ВЫРАВНИВАНИЕ БИОЛОГИЧЕСКИХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
Выравниванием (allignment) последовательностей азотистых осно-
ваний в нуклеиновых кислотах или аминокислот в полипептидных цепях белков называют определение взаимного соответствия остатков (нукле-
иновых оснований или аминокислотных остатков, соответственно) в этих двух или нескольких последовательностях, при котором сохраняется исходный порядок остатков в последовательностях.
Выравнивание последовательностей – это основной инструмент биоинформатики, его проводят с целью установления структурных, функциональных и эволюционных отношений между последовательностями.
Биологические макромолекулы являются результатом молекулярной эволюции. Поэтому если две такие биомакромолекулы имеют некоторого общего предка, а значит и последовательности мономеров в таких макромолекулах общую предковую последовательность, то они, как правило, обнаруживают подобие в сочетаниях мономеров, в структурах и в биологических функциях.
Например, если открыта новая последовательность с неизвестной функцией, но при этом в базах данных могут быть найдены подобные ей последовательности с ранее установленными структурами и функциями,
4
то результаты выравнивания (сравнения) этой новой последовательности с уже исследованными последовательностями могут стать основанием для предсказания функции или структуры этой новой последовательности.
Одна из целей выравнивания последовательностей состоит в том, чтобы определить степень подобия двух последовательностей и, если она достаточно высока, сделать правдоподобное заключение об их гомологич-
ности.
При передаче генетической информации от предыдущего поколения следующему она несколько изменяется во время процесса копирования. Изменения, которые происходят в процессе расхождения от общего предка, могут быть трёх типов: замены, вставки и удаления (выпадения).
Эти изменения могут накапливаться от поколения к поколению. Через несколько тысяч поколений в последовательностях может наблюдаться значительное число расхождений. Сравнение двух предположительно гомологичных последовательностей показывает степень их расхождения, то есть силу эволюционных изменений.
Выравнивание последовательностей – это процедура сравнения двух
(попарное выравнивание) или нескольких (множественное выравнивание)
последовательностей путём поиска рядов отдельных элементов или характерных комбинаций элементов последовательностей, которые расположены в выравниваемых последовательностях в одинаковом порядке.
При выравнивании двух последовательностей их помещают в две строки друг над другом, записывая их с помощью букв алфавита.
Идентичные или подобные "буквы" (элементы) этих строк (последовательностей) сдвигают в пределах строки (не меняя исходного порядка следования "знаков") таким образом, чтобы они выстраивались друг под другом в соответствующих столбцах.
Неидентичные, или различные знаки либо помещают в одни и те же столбцы как несовпадения, либо вставляют напротив них во второй последовательности пропуски.
Рассмотрим для примера две строки:
1) abcde |
2) acdef |
5
Разумное выравнивание выглядит так:
abcde- a-cdef
Для того чтобы найти оптимальное (или наилучшее) выравнивание необходимо определить критерий качества выравнивания. Так, для последовательностей нуклеотидов gctgaacg и ctataatc возможны следующие выравнивания:
1. |
Неинформативное выравнивание |
--------gctgaacg |
|
|
ctataatc-------- |
2. |
Выравнивание без пропусков |
gctgaacg |
|
|
ctataatc |
3. |
Выравнивание с пропусками |
gctga-a--cg |
|
|
--ct-ataatc |
4. |
Ещё одно выравнивание |
gctg-aa-cg |
|
|
-ctataatc- |
Интуитивно кажется, что последнее выравнивание является лучшим, поскольку в нём получено максимальное число совпадений для нуклеотидов в двух последовательностях и использовано минимальное число вставок.
Чтобы решить, является ли оно лучшим из всех возможных, необходимо иметь способ систематической проверки всех возможных выравниваний, иметь количественный критерий ("вес" ("weihgt") или
счёт ("score")), по которому возможно сравнивать качество различных выравниваний и определить выравнивание с оптимальным весом (счётом).
При этом от того, какая именно система оценки выбрана для такого сравнения, может зависеть результат сравнения, и даже незначительные изменения в схеме оценки могут изменить рейтинг выравниваний, из-за чего лучшим станет другое выравнивание.
6
1.2. ТОЧЕЧНАЯ МАТРИЦА СХОДСТВА
Точечная матрица (dot plot) – это простейшее изображение, которое даёт представление о сходстве между двумя последовательностями.
Точечная матрица представляет собой таблицу или матрицу, в которой строки соответствуют элементам одной последовательности, а колонки – элементам другой последовательности. В простейшем варианте ячейки точечной матрицы оставляют пустыми, если сравниваемые элементы различны, и заполняются, если они совпадают. Совпадающие фрагменты последовательностей отображаются в виде диагоналей, идущих из верхнего левого угла в нижний правый.
Для примера построим точечную матрицу, показывающую совпадения между короткой строкой ПРОФЕССОРОГУРЦОВ и длинной
ПРОФЕССОРАЛЕКСАНДРНИКОЛАЕВИЧОГУРЦОВ (рисунок 1).
|
П Р О Ф Е С С О Р А Л Е К С А Н Д Р Н И К О Л А Е В И Ч О Г У Р Ц О В |
||||||||||||||||||||||||||||||||||
П |
П |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
Р |
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
О |
|
|
О |
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
О |
|
|
|
|
О |
|
Ф |
|
|
|
Ф |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
Е |
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
|
|
Е |
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
С |
С |
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
С |
|
|
|
|
|
С |
С |
|
|
|
|
|
|
С |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
О |
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
О |
|
|
|
|
О |
|
Р |
|
Р |
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
О |
|
|
О |
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
О |
|
|
|
|
О |
|
Г |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Г |
|
|
|
|
|
У |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У |
|
|
|
|
Р |
|
Р |
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
Р |
|
|
|
|
|
|
|
|
|
|
|
|
|
Р |
|
|
|
Ц |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ц |
|
|
О |
|
|
О |
|
|
|
|
О |
|
|
|
|
|
|
|
|
|
|
|
|
|
О |
|
|
|
|
|
|
О |
|
|
|
|
О |
|
В |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В |
|
|
|
|
|
|
|
|
В |
Рисунок 1 – Точечная матрица сходства двух строк
Буквы, соответствующие длинным совпадающим участкам выделены жирным шрифтом, а одиночные совпадения, не выделены жирным шрифтом. Очевидно, выравнивание в этом случае будет иметь вид
ПРОФЕССОРАЛЕКСАНДРНИКОЛАЕВИЧОГУРЦОВ |
|
ПРОФЕССОР------------------- |
ОГУРЦОВ |
|
7 |
На рисунке 2 представлена точечная матрица, показывающая как глобальные, так и локальные совпадения повторяющейся последовательности АБРАКАДАБРАКАДАБРА с самой собой.
А Б Р А К А Д А Б Р А К А Д А Б Р А
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
Б |
|
Б |
|
|
|
|
|
|
Б |
|
|
|
|
|
|
Б |
|
|
Р |
|
|
Р |
|
|
|
|
|
|
Р |
|
|
|
|
|
|
Р |
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
К |
|
|
|
|
К |
|
|
|
|
|
|
К |
|
|
|
|
|
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
Д |
|
|
|
|
|
|
Д |
|
|
|
|
|
|
Д |
|
|
|
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
Б |
|
Б |
|
|
|
|
|
|
Б |
|
|
|
|
|
|
Б |
|
|
Р |
|
|
Р |
|
|
|
|
|
|
Р |
|
|
|
|
|
|
Р |
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
К |
|
|
|
|
К |
|
|
|
|
|
|
К |
|
|
|
|
|
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
Д |
|
|
|
|
|
|
Д |
|
|
|
|
|
|
Д |
|
|
|
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
Б |
|
Б |
|
|
|
|
|
|
Б |
|
|
|
|
|
|
Б |
|
|
Р |
|
|
Р |
|
|
|
|
|
|
Р |
|
|
|
|
|
|
Р |
|
А |
А |
|
|
А |
|
А |
|
А |
|
|
А |
|
А |
|
А |
|
|
А |
Рисунок 2 – Точечная матрица совпадений в повторяющейся последователь-
ности
Вид точечной матрицы может наглядно показать наличие палиндромных последовательностей в анализируемой строке.
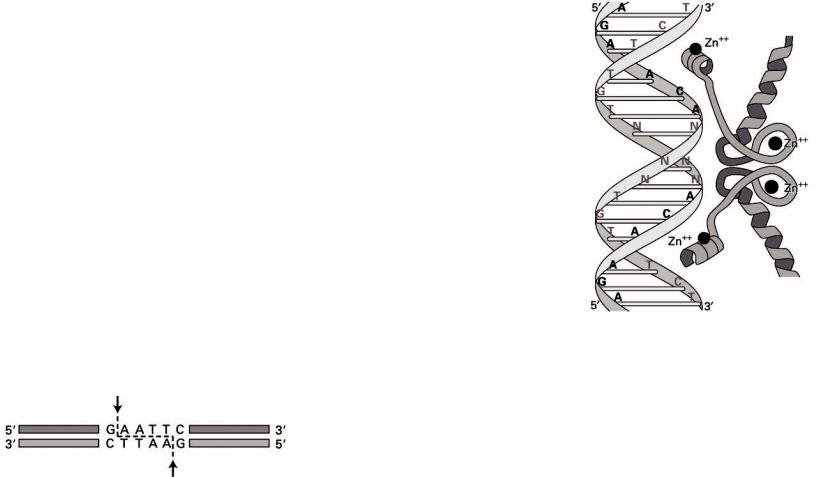
Так палиндромами являются сайты рестрикции в ДНК для рестрикционных ферментов (рисунок 3).
Рисунок 3 – Разрезание ДНК рестрикционным ферментом EcoRI
8
Иногда палиндромность ДНК-последовательности определяется тем, что с этим участком ДНК должен взаимодействовать димерный белок, одна субъединица которого взаимодействует с одним плечом палиндрома, а другая – с другим плечом на комплементарной цепи, как, например, в случае связи рецептора глюкокортикоидных гормонов с гормон-распознающим элементом (HRE) ДНК (рисунок 4).
Рисунок 4 – Палиндромный гормон-распознающий элемент (HRE) ДНК, связанный с димеризованными рецепторами стероидных гормонов
HRE является палиндромом, то есть участком ДНК, обе нуклеотидные нити которого одинаковы, если каждую из них читать в направлении 5′→3′. Для нашего примера HRE имеет вид
5′-AGAACANNNTGTTCT-3′
3′-TCTTGTNNNACAAGA-5′
9