Материал: bikkulov_as_chugunov_av_setevoi_podkhod_v_sotsialnoi_informa
Разработка программы и используемые алгоритмы.
Программа была разработана по инициативе полиции Лос-Анджелеса группой исследователей63, включавших двух математиков, антрополога и криминолога. Для тестирования в г. Санта-Крус в программу были загружены данные за 8 лет, при этом данные о времени, типе и месте зарегистрированных преступлений накладывали на карту города, разделенную на квадраты 150х150 м. Новые данные добавляют в систему каждый день в режиме реального времени.
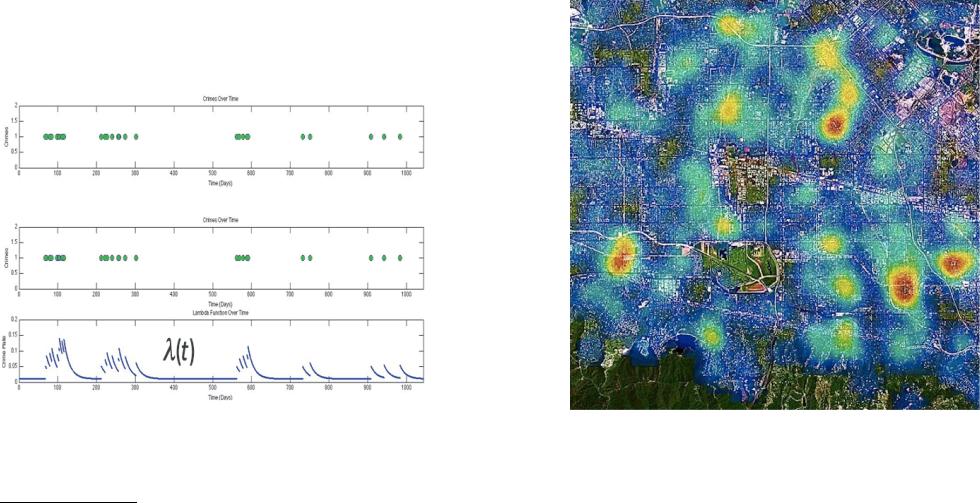
Используемая модель напоминает расчёт вероятности афтершоков — повторных сейсмических толчков меньшей интенсивности по сравнению с главным толчком. Как и в случае с землетрясениями, каждое преступление тоже рождает волны «афтершоков», т.е. повышает вероятность новых преступлений в том же месте в будущем. Для иллюстрации алгоритма авторы приводят несколько графиков (см. рис. 13, 14).
Рис. 13. Статистика гангстерских перестрелок в одном из районов Лос-Анджелеса
Рис. 14. Преобразование статистики преступлений в частотность по модели афтершоков с помощью лямбда-функции
Рис. 13 отображает статистику гангстерских перестрелок в одном из районов Лос-Анджелеса и служит для демонстрации того, что
63 PredPol. Predictive Policy. URL: http://www.predpol.com.
преступления некоторых типов склонны группироваться по времени и месту.
На базе статистики преступлений за последние несколько лет вычисляется лямбда-функция λ(t). На рис. 14 показано, как статистика преступлений преобразуется в частотность.
Аналогичный параметр (crime rate) программа вычисляет для каждого района города и вида преступления. Если составить тепловую карту, то получится тепловая карта города, приведенная на рис. 15.
Рис. 15. «Тепловая» карта вероятности преступлений в городе
Для каждого квадрата размером 150 на 150 м указывается вероятность совершения преступления в 24-часовой период, распределение этой вероятности по видам преступления: автомобильные, домашние, разбой, время начала двух самых опасных по вероятности часовых интервалов (см.
70 |
71 |
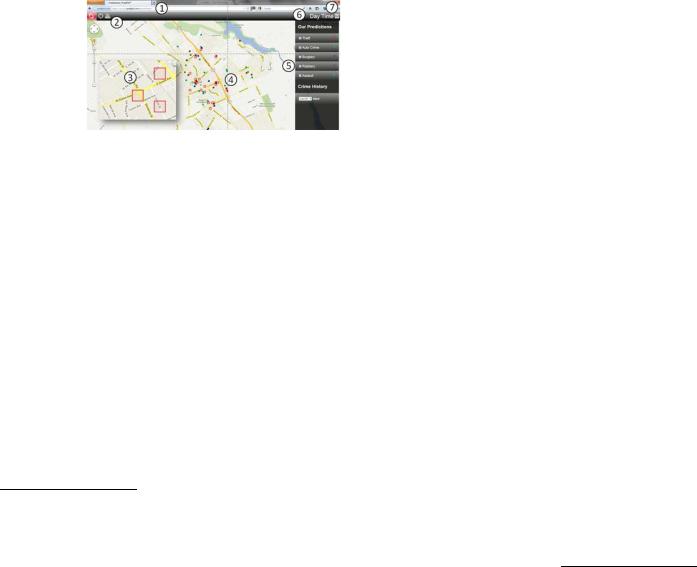
рис 16). Учитываются день недели, время суток, наличие/отсутствие футбольных матчей по ТВ и другие факторы.
Рис. 16. Скриншот интерфейса программы с картой, на которой отмечены наиболее вероятные преступления в этом районе на данную дату по видам64
С опорой на вышеприведенные данные программы составляется график движения патрульных машин по городу и рекомендуются проверочные действия патрульных.
Аналогичные попытки применения компьютерных алгоритмов вычисления наиболее вероятных времени и мест преступлений ведутся и в других городах США (например, в г. Чикаго также в 2011 г. было запущено аналогичное тестирование65), однако модель, применяемая в городе Санта-Крус, является одной из наиболее сложных и доказавшей свою эффективность.
6.2.Алгоритм прогнозирования местонахождения подозреваемых в подготовке преступлений на основе отслеживания мобильных телефонов
Исследователь Бирмингемского университета Мирко Мусолези (Mirco Musolesi)66 применил подход, который основан не на статистике, а на сетевых связях человека по мобильному телефону и их изменении во времени и пространстве. При этом важна оперативность данных сетей сотовой связи. Применив свой алгоритм, Мусолези выиграл конкурс Nokia Mobile Data, наиболее точно предсказав перемещения 25 добровольцев по
64PredPol. Predictive Policy. URL: http://www.predpol.com/.
65Sending the Police Before There’s a Crime/ The New York Times. August 16, 2011, P. A11, см. также Sending the Police Before There’s a Crime URL:
http://www.nytimes.com/2011/08/16/us/16police.html?_r=1.
66 Алгоритм предсказывает преступления, отслеживая мобильные телефоны/ URL: http://habrahabr.ru/post/149184/; Algorithm Aims To Predict Crime By Tracking Mobile Phones URL: http://www.forbes.com/sites/parmyolson/2012/08/06/algorithm-aims- to-predict-crime-by-tracking-mobile-phones/; Domenico M., Lima A., Musolesi M. Interdependence and Predictability of Human Mobility and Social Interactions. URL: http://www.cs.bham.ac.uk/~musolesm/papers/mdc12.pdf/.
сигналам их телефонов, истории звонков и текстовым сообщениям. Иногда алгоритм прогнозирует координаты пользователя с точностью до 20 м2.
Алгоритм работает эффективно только при условии, что одновременно отслеживается вся сеть друзей указанного пользователя. Если отслеживать мобильный телефон только самого человека, точность предсказания координат снижается до 1000 м2. При этом, даже если удавалось извлечь уточняющую информацию всего у одного друга, точность сразу резко увеличивалась.
Таким образом, алгоритм, например, способен вычислить место и время, где через 20—30 минут встретится группа потенциальных преступников. По словам Мусолези можно вычислить конкретную улицу, квартал, иногда даже дом — место потенциального преступления. Очевидно, что туда на всякий случай нужно направить патрульную машину.
Мусолези надеется, что его разработка будет использована правоохранительными органами. Исследователь уверен, что подобная система анализа данных не нарушает законодательство: «Наш алгоритм —
это способ извлечь новую информацию из данных, [которые у полиции уже есть]», — говорит он в интервью изданию Forbes. Кто-то назовёт такой метод сомнительным, ведь осуществляется слежка за людьми, которые ещё не совершили преступления, а только по каким-то критериям занесены в «группу риска» (например, граждане с криминальным прошлым или упомянувшие ключевое слово в разговоре по телефону или в SMS). С другой стороны, сам алгоритм работает с анонимными данными, так что такая «слежка» принципиально не отличается от какой-нибудь системы контекстной мобильной рекламы или системы мониторинга чатов по ключевым словам, что используется в чатах Facebook и других сервисах.
В принципе подобные алгоритмы может использовать не только полиция, но и обычные коммерческие компании с разрешения их клиентов, прогнозируя их появление в своих ресторанах/спа/офисах, и, возможно, резервируя сервис для VIP-клиентов без предварительного звонка и бронирования.
Мирко Мусолези с коллегами опубликовали результаты своей работы67; в ближайшее время они собираются провести дополнительные эксперименты на базе данных, предоставленной компанией Nokia.
67 Kwak H., Lee C., Park H., Moon S. What is Twitter, a Social Network or a News Media? Proceedings of the 19th International World Wide Web (WWW) Conference, April 26-30, 2010, Raleigh NC (USA). См. также URL: http://an.kaist.ac.kr/traces/ WWW2010.html.
72 |
73 |

6.3.Компьютерное прогнозирование актов терроризма и политических акций, сопровождающихся применением насилия. Компьютерное моделирование и симуляция поведения террористических групп
ВНациональной лаборатории Лос-Аламос (США), ученые из Международной группы по исследованиям и анализу (IAT-1) объединяют социальные, экономические, политические, культурные показатели и сообщения СМИ с новейшими исследованиями социальных наук и компьютерным моделированием, чтобы лучше прогнозировать вероятность терроризма и политических акций, сопровождающихся применением насилия68. Данные работы Международной группы по исследованиям и анализу проводятся при поддержке Министерства обороны США.
Одним из используемых методов является моделирование, основанное на агентном подходе. Такого рода моделирование основывается на построении симулятора социальной системы, построенной из взаимодействующих «агентов», которые могут играть в модели роль взаимодействующих индивидов или взаимодействующих групп индивидов. Исследователь собирает информацию о том, как реальные прототипы-индивиды или группы вели себя в определенных ситуациях, и кодирует основные тенденции в поведенческом алгоритме «агента» модели, а затем проводит симуляцию поведения «агентов» при разных ситуациях и факторах влияния.
6.4.Перспективные направления компьютерных исследований в социальных сетях
Сервисы рекомендаций — прогнозирование наиболее вероятных новых связей подписки/дружбы, использования сервисов соцсетей
Одним из примеров такого рода исследований является конкурс Facebook69, выложившей в качестве задачи анонимизированный социальный граф с числом тестируемых вершин 262 588, числом ребер в графе 9 437 519 и числом вершин в графе 1 862 220. Данный граф получен из реального графа (правда, оговорено, что это — не граф Facebook) путем удаления части ребер. Задача: для каждой из тестируемых вершин (т.е. тех самых 262 588), представить ранжированный список 10 других вершин, с
68 How people become terrorists. Modeling Pathways toward Radicalization. URL:
http://www.lanl.gov/science/NSS/issue3_2011/story2full.shtml.
69 Маленькие секреты больших графов. URL: http://habrahabr.ru/post/148162/ #habracut/; Facebook Recruiting Competition. URL: https://www.kaggle.com/c/ FacebookRecruiting/.
которыми у них с наибольшей вероятностью должна была быть (или будет) связь, т.е. фактически восстановить удаленные ребра и спрогнозировать возникновение новых. Наиболее успешных в этом конкурсе авторов компания собирается пригласить на работу.
Аналогичные по проблематике направления исследований активно развиваются и в других сервисах с элементами социальных сетей. Так, например, подобные рекомендации по возможным «друзьям» предлагаются на российском рекомендательном ресурсе Имхонет70, где в качестве базы данных для вычисления наиболее вероятных друзей («единомышленников») служит сходство оценок фильмов, книг и т.п., а не анализ графов дружбы. На основе этих оценок Имхонет формирует представление о вкусе пользователя и подбирает людей со схожими предпочтениями, на основе оценок которых строятся индивидуализированные рекомендации по фильмам, книгам, путешествиям и, как побочная линия, — знакомствам.
Автоматическое определение сообществ в социальных сетях
Актуальным, активно разрабатываемым и совершенствуемым направлением исследования и моделирования сетей является выявление сообществ (Community Detection) в социальных сетях71. В такого рода исследованиях сообществом считается совокупность пользователей, имеющих большую плотность связей внутри совокупности, по сравнению с плотностью внешних связей.
Иными словами, при изучении сложных сетей считается, что сеть имеет структуру сообщества, если узлы сети могут быть легко разделены на (возможно перекрывающиеся) наборы узлов так, что каждый набор узлов имеет сравнительно большую внутреннюю плотность. В частном случае определения неперекрывающихся сообществ это означает, что сеть делится на группы узлов с плотными внутренними связями и редкими связями между группами72.
70Рекомендательный сервис Imhonet. URL: http://imhonet.ru/.
71Разработка и проведение имитационных игр на базе компьютерных симуляторов. URL: http://www.ite.ane.ru/index.php/ru/technologies/65-simulation-games/;
Kwak H., Lee C., Park H., Moon S. What is Twitter, a Social Network or a News Media? Proceedings of the 19th International World Wide Web (WWW) Conference, April 26—30, 2010, Raleigh NC (USA). См. также URL: http://an.kaist.ac.kr/traces/WWW2010.html;
Porter M. A., Onnela J.-P., Mucha P. J. Communities in Networks // Not. Amer. Math. Soc. 2009. Vol. 56. P. 1082–1097, 1164—1166. См. также URL:
http://www.ams.org/notices/200909/rtx090901082p.pdf.
72 Kwak H., Lee C., Park H., Moon S. What is Twitter, a Social Network or a News Media? Proceedings of the 19th International World Wide Web (WWW) Conference, April 26-30, 2010, Raleigh NC (USA). См. также URL: http://an.kaist.ac.kr/traces/ WWW2010.html.
74 |
75 |

Основными алгоритмами определения сообществ в сетях являются73:
— Minimum-Cut Method ( пер. с англ. — метод отсечения минимальных связей) состоит в том, что сеть делится на заранее заданное число частей обычно примерно равного объема, определяемых таким образом, чтобы число связей между ними было минимальным. Метод имеет довольно существенные недостатки в применении к социальным сетям, так как находит сообщества, независимо от того, есть они в социальной сети или нет, причем именно то количество сообществ, которое задано вручную исследователем.
— Hierarchical clustering ( пер. с англ. — иерархическая кластеризация)
— в этом методе определяется количественная мера сходства некоторых (как правило, топологических) характеристик сходства между парами узлов. Часто используемые меры включают в себя косинус-подобие (cosine similarity), индекс Жаккара (Jaccard index) и расстояние Хемминга (Hamming distance) между строками матрицы смежности.
—Girvan-Newman algorithm clustering ( пер. с англ. — алгоритм Гирвана-Ньюмана), основанный на параметре промежуточности вершин, находит вершины, лежащие между сообществами и удаляет их, получая несвязанные сообщества. Дает достатоно хорошие результаты, но очень ресурсоемок с точки зрения вычислений.
—Modularity maximization ( пер. с англ. — максимизация модульности) — наиболее используемый метод. Определяет сообщества путем попытки разбиения на части с максимальной модульностью. Несмотря на широкое применение имеет ряд недостатков. Считается, что сегодня лучше работает следующий метод.
—Surprise maximization ( пер. с англ. — максимизация неожиданных отклонений) — определение сообществ основано на кумулятивном гипергеометрическом распределении.
—The Louvain method ( пер. с англ. — лувинский метод) —
подтвердил свою эффективность на ряде примеров и сейчас является одним из наиболее широко используемых методов. Метод реализован во многих программных пакетов сетевого анализа, в том числе в KXEN InfiniteInsight, NetworkX и Gephi. Проводится в два этапа: сначала выделяются локальные сообщества с максимальной модульностью, затем, используя эти локальные сообщества в качестве узлов, строится сеть следующего порядка, и в ней повторяется шаг 1. Эти шаги повторяются до достижения максимальной модульности.
73 Community structure / Статья свободной энциклопедии – Википедии. URL: http://en.wikipedia.org/wiki/Community_structure.
— Clique based methods ( пер. с англ. — метод, основанный на кликах)
— кликами считаются подграфы, в узлы соединены каждый с каждым в данной клике.
Исследования и разработки в этом направлении продолжают активно совершенствовать методы выделения сообществ.
Анализ тональности текста (сентимент-анализ)
Анализ тональности текста (сентимент-анализ, англ. sentiment analysis), активно развивающееся направление компьютерной лингвистики, класс методов контент-анализа, предназначенный для автоматизированного выявления в текстах эмоционально окрашенной лексики и эмоциональной оценки авторов по отношению к объектам, речь
окоторых идёт в тексте (анализ высказываний, англ. opinion mining)74.
Всовременных системах автоматического определения эмоциональной оценки текста чаще всего используется одномерное эмотивное пространство: позитив или негатив (хорошо или плохо), однако известны успешные случаи использования и многомерных пространств. Разработаны инструменты, которые с приемлемой степенью надежности работают на англоязычных текстах. Все эти инструменты для русского языка дают пока не вполне удовлетворительные результаты, так что адаптация и разработки в этом направлении также продолжают оставаться перспективным и актуальным направлением исследований.
Контрольные вопросы
1.Объясните, каким образом полиции Санта-Крус удается прибыть на место правонарушения раньше его начала и в ряде случаев предотвратить его? На каких принципах основаны алгоритмы обработки статистических данных о правонарушениях в Санта-Крус?
2.Назовите примеры моделирования и прогнозирования местоположения абонентов на основе логов звонков и сигналов мобильных телефонов. Какие условия должны быть соблюдены для корректности работы алгоритмов? Для каких задач могут применяться подобные технологии?
3.Каковы основные принципы и алгоритмы, положенные в основу проводимых в Национальной лаборатории Лос-Аламос (США) компьютерного прогнозирования актов терроризма и политических акций, сопровождающихся применением насилия, компьютерного моделирования и симуляции поведения террористических групп?
74 Анализ тональности текста / Статья свободной энциклопедии – Википедии. URL: http://ru.wikipedia.org/wiki/Анализ тональности текста.
76 |
77 |
4.Назовите существующие примеры применения и исследований прогнозирования совпадения интересов/дружбы между пользователями социальных сетей.
5.Опишите основные алгоритмы определения сообществ в социальных сетях, кластеризации.
6.Что такое «анализ тональности текста (сентимент-анализ)»?
Заключение
Вприведенном материале проведено обобщение теоретических основ сетевого подхода, проиллюстрированы области его практического применения. Рассмотрены вопросы моделирования социальных процессов на основе анализа социальных сетей.
Вкачестве примеров исследовательской практики использованы результаты работы научно-производственного веб-ориентированного центра по проведению исследований процессов социодинамики «Социодинамика», разработанного в НИУ ИТМО в 2012 г. в рамках выполнения НИР.
78 |
79 |