нако, связь между ними проявится не как функциональная, так как на ней отражаются еще и рассеивания слагаемых U и V. В результате этого при увеличении (уменьшении) одной из случайных величин X или Y другая будет увеличиваться (уменьшаться) лишь в среднем.
Чем в большей степени рассеивается общая составляющая Z по сравнению с составляющими U и V, тем теснее корреляционная связь между случайными величинами X и Y, и, наоборот, при отсутствии рассеивания Z эти случайные величины становятся чисто независимыми.
Если компоненты X и Y случайного вектора {X, Y} независимы, то они оказываются и некоррелированными. Обратное утверждение не всегда верно, поскольку некоррелированные случайные величины могут быть зависимыми. Это обусловлено тем, что распределение случайной величины является более полной ее вероятностной характеристикой, чем математическое ожидание. Такая особенность присуща, например, компонентам X и Y случайного вектора, рассмотренного в примерах 9.4 и 9.5. Как было показано, они стохастически независимы, но математические ожидания, соответствующие любому условному распределению каждой из них (см. рис. 9. 7), равны нулю, т. е. не зависят от того, какие значения принимает другая, так что корреляция между X и Y отсутствует. И момент связи Kx,y в условиях этих примеров оказывается равным нулю.
Наряду с моментом связи в качестве характеристики степени корреляции между случайными величинами используется коэффициент корреляции rx,y, который определяется соотношением
(9.111)
Эта характеристика обладает большей наглядностью относительно степени корреляции, чем момент связи, поскольку |rx,y| # 1. Если случайные величины X и Y некоррелированы, то rx,y = 0, а если они связаны линейной функциональной зависимостью, то |rx,y| = 1 (знак rx,y одинаков со знаком Kx,y).
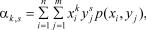

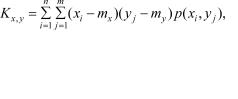
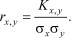

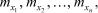 матрицей , элементами которой являются моменты связи всех возможных пар
матрицей , элементами которой являются моменты связи всех возможных пар