Материал: Введение в эконометрику10
Задание на самостоятельную работу*
Предприниматель намерен использовать множественный регрессионный анализ для оценки стоимости офисного здания в заданном районе, используя данные таблицы 12. Для этого предлагается выполнить следующую работу:
Определить уравнение регрессии и его характеристики.
Проанализировать значения коэффициентов детерминации (стандартного и адаптированного). Можно ли говорить о сильной зависимости между объясняющими переменными и стоимостью здания?
Проверить значимость уравнения регрессии по критерию Фишера при уровне значимости 0,05.
Построить доверительные интервалы для коэффициентов уравнения регрессии.
Проверить значимость коэффициентов уравнения регрессии при уровне значимости 0,05. Все ли факторы полезны при оценке стоимости здания?
Таблица 12. Данные по стоимости офисных зданий
№ |
Общая площадь (кв.м) X1 |
Количество офисов X2 |
Количество входов X3 |
Срок эксплуатации (год) X4 |
Стоимость (млн. у. е.), Y |
|
|
2 310 |
2 |
2 |
20 |
142 |
|
|
2 333 |
2 |
2 |
12 |
144 |
|
|
2 356 |
3 |
1,5** |
33 |
151 |
|
|
2 379 |
3 |
2 |
43 |
150 |
|
|
2 402 |
2 |
3 |
53 |
139 |
|
|
2 425 |
4 |
2 |
23 |
169 |
|
|
2 448 |
2 |
1,5** |
99 |
126 |
|
|
2 471 |
2 |
2 |
34 |
142,9 |
|
|
2 494 |
3 |
3 |
23 |
163 |
|
|
2 517 |
4 |
4 |
55 |
169 |
|
|
2 540 |
2 |
3 |
22 |
149 |
Практическая работа №4. Временные ряды в эконометрике
1. Теоретическая часть
1.1. Определение временного ряда. Составляющие временного ряда.
Временной (динамический) ряд – это последовательность наблюдений экономического признака – случайной величины Y – в последовательные моменты времени t. Отдельные наблюдения yt (t=1,2,…,n) называются уровнями ряда, через n обозначено число наблюдений (уровней).
Предполагается, что временной ряд может содержать следующие составляющие: тренд (T), циклическая компоненту (S), интервенцию (I), случайную компоненту (возмущение – E).
Тренд – это плавно меняющаяся компонента, отражающая долгосрочные (вековые) закономерности зависимости Y(t). Циклическая компонента обусловлена периодически повторяющимися закономерностями, такими как, например, сезонные или суточные изменения. Интервенция отражает резкое, скачкообразное изменение Y. Возмущение характеризует влияние не поддающихся учету и регистрации факторов.
Рассматриваются две модели временных рядов, не содержащих интервенции: аддитивная модель, для которой
Y=T+S+E, (40)
и мультипликативная, для которой
Y=TSE. (41)
1.2. Коэффициент автокорреляции временного ряда
Рассмотрим два момента времени t и t1, t1= t+t, временной сдвиг t в эконометрике принято называть лагом.
Коэффициентом автокорреляции ρ(t,τ) называется коэффициент корреляции случайных величин Y(t) и Y(t+τ). Напомним, что при |ρ(t,τ)|=1 Y(t) и Y(t+τ) линейно зависят друг от друга; если Y(t) и Y(t+τ) независимы, то ρ(t,τ)=0. Таким образом, ρ(t,τ) характеризует тесноту связи между Y(t) и Y(t+τ). Выборочный коэффициент автокорреляции обозначим r(t,τ) (см. Приложение).
График или диаграмма r(τ)=r(t=t*,τ) при фиксированном значении t=t* называется коррелограммой. Анализируя коррелограмму, можно вынести некоторые суждения о свойствах временного ряда в окрестности момента t=t*:
если величина |r(1)| значительна (по сравнению со значениями |r(τ)| при τ≠1), то ряд имеет линейный тренд;
если значение r(t*), t*>1, существенно превышает значение r для других лагов, то ряд содержит циклическую составляющую с периодом t*.
если ни одно значение r(t) не выделяется по величине, то либо ряд не содержит трендовой и циклической составляющих, либо тренд ряда является нелинейным.
Временной ряд называется стационарным в широком смысле слова, если математическое ожидание M[Y(t)] и коэффициент автокорреляции r(t,t) не зависят от t: M[Y(t)]= M[Y(t+t)], r(t, t) º r(t) для любых t.
1.3. Аналитическое определение тренда временного ряда
Рассмотрим одну простую модель временного ряда – аддитивную модель, учитывающую только тренд и возмущение: Y(t)=T(t)+E(t). Задача подбора аналитической зависимости T(t), лучше всего соответствующей наблюдениям Y(t), обычно решается в два этапа. На первом этапе выбирается параметрическое семейство зависимостей y=T(t,b), где b – параметр, обычно векторный. На втором этапе оценивается значение параметра b, как правило, по МНК.
Параметрическое семейство y=T(t,b) определяется либо из экономических соображений, либо по виду графика Y(t). Система Excel позволяет на точечную диаграмму Y(t) добавлять следующие тренды y=T(t,b):
линейный: y=b0+b1t;
полиномиальный: y=b0+b1t+b2t2+…+bmtm, 2≤m≤6;
логарифмический: y=b0+b1lnt;
экспоненциальный:
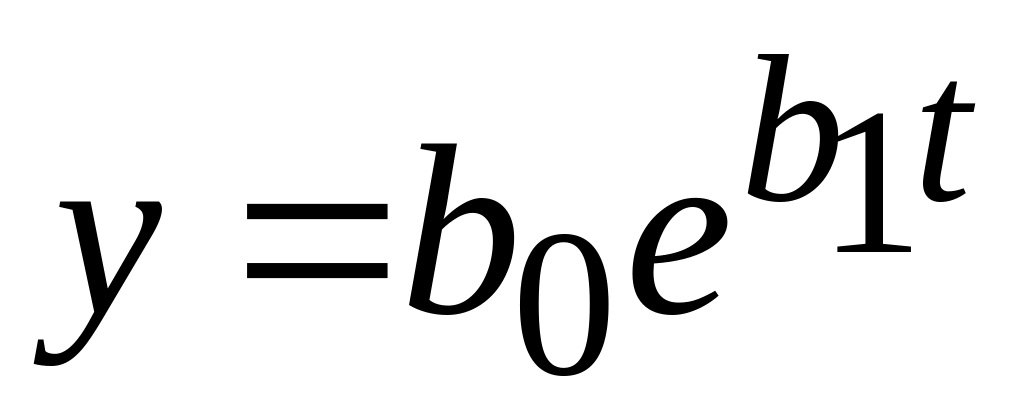 ;
;степенной:
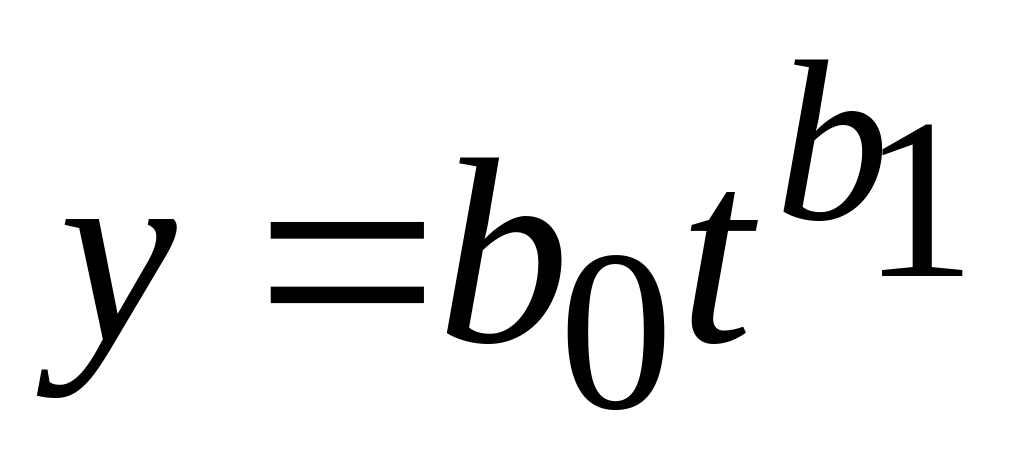 .
.
Для различных видов (моделей) трендов рассчитываются значения Qe, QR, R2, F, и в результате сравнения этих значений выбирается наилучшая модель. Значение коэффициента детерминации R2 среда Excel позволяет вывести непосредственно на диаграмму. Заметим, что полиномиальный тренд в эконометрике применяется весьма редко, так как его использование обычно приводит к большому риску существенной ошибки прогноза. Чаще всего рассматривается линейный тренд (см. практическую работу №3, §1.9).
1.4. Проверка гипотезы о некоррелированности остатков
Известно (см. §1.4 практической работы №1), что МНК-оценки параметров линейной регрессии в условиях классической нормальной линейной регрессионной модели являются эффективными в классе всех линейных оценок, состоятельными, несмещенными и обладают другими хорошими свойствами. Однако для временных рядов требование независимости возмущений не всегда выполняется. Поэтому после оценки тренда следует проверить гипотезу H0 об отсутствии автокорреляции остатков: если H0 отвергается, то качество тренда сомнительно.
В данном пособии рассматривается одно из самых популярных правил проверки гипотезы H0 – тест Дарбина-Уотсона. В соответствии с этим тестом вычисляется статистика:
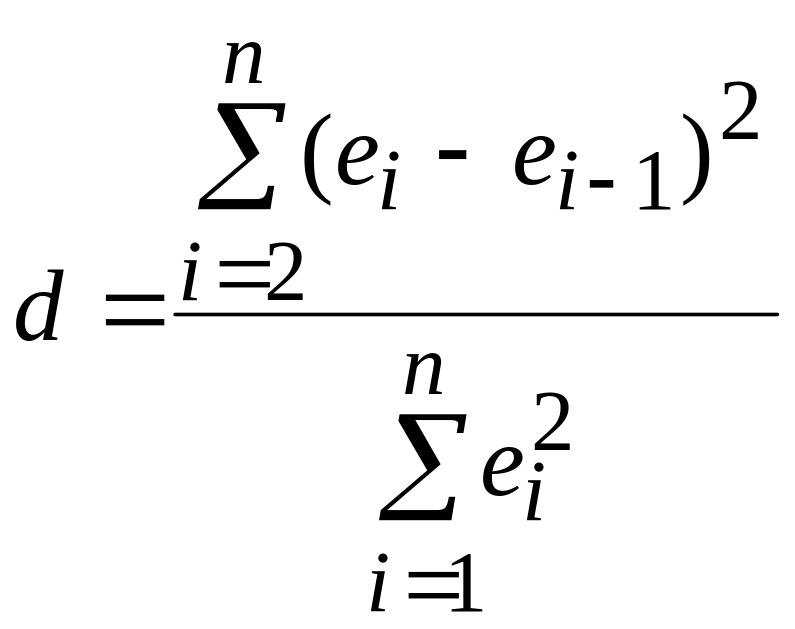 . (42)
. (42)
Можно доказать, что d=2(1-r), где r – выборочный коэффициент автокорреляции ряда (см. Приложение). Так как -1≤ r ≤1, то 0≤ d ≤4. Значение d=0 (r=1) соответствует случаю сильной положительной автокорреляции остатков, значение d=2 (r=0) – отсутствию автокорреляции, d=4 (r=-1) – сильной отрицательной автокорреляции.
В статистических таблицах (см., например, [5, 8]) для различных значений числа наблюдений n и уровня значимости приводятся пороговые значения статистики d: нижнее dн и верхнее dв, такие, что (см. рис. 5):
При 0≤ d≤ dн гипотеза H0 отвергается (случай положительной автокорреляции).
При 4-dн ≤ d≤4 H0 отвергается (случай отрицательной автокорреляции).
При dв ≤ d≤ 4-dв гипотеза H0 принимается.
П
 ри
остальных значениях d суждение о
справедливости H0 не выносится
(d попадает в одну из двух зон
неопределенности).
ри
остальных значениях d суждение о
справедливости H0 не выносится
(d попадает в одну из двух зон
неопределенности).
1.5. Метод скользящего среднего
Метод скользящего среднего (МСС) состоит в замене каждых k последовательных уровней ряда их средним значением. Величина k называется окном усреднения (сглаживания).
Если k нечетно (k=2l+1, где l-целое положительное число), то скользящее среднее ut задается формулой:
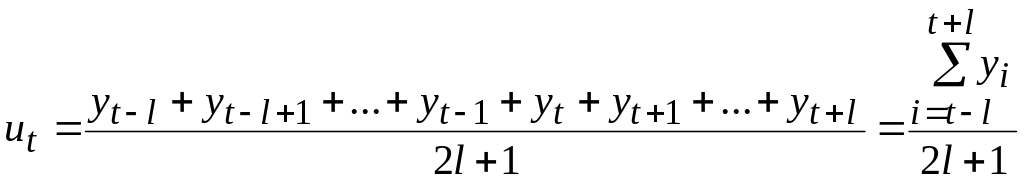 .
.
Таким образом, среднее, вычисленное по k уровням ряда, приписывается к срединному моменту времени окна сглаживания. В приведенной выше формуле t=l+1, …, n-l. Следовательно, скользящее среднее не определено для l начальных и l конечных моментов времени.
Переход от наблюдений Y к скользящему среднему позволяет «сгладить» ряд и получить значения, более близкие к тренду. Действительно, если разброс значений yt около тренда характеризуется дисперсией 2, то разброс среднего по k уровням ряда будет характеризоваться существенно меньшей дисперсией (2/k – при независимости случайных величин Y(t)). Если ряд содержит циклическую составляющую, то следует брать k равным ее периоду, чтобы отрицательные и положительные отклонения от тренда гасили друг друга.
Рассмотрим случай четного k (k=2l). Предположим, что вычислили среднее значение для 2l моментов времени, начиная с t0: t0, t0+1, …, t0+l-1, t0+l, …, t0+2l-1. Середина такого интервала находится между t0+l-1 и t0+l; поэтому непонятно, к какому моменту привязать значение скользящего среднего. Выход состоит в следующем: приписываем среднее любому из этих моментов, например, меньшему – t0+l-1, а затем полученный ряд еще раз сглаживаем с окном k1=2, так чтобы скользящее среднее было правильно привязано к центру окна. Эта процедура поясняется также на примере (см. §2.3.4).
Сравним два метода оценивания тренда: аналитический (см. §1.3) и МСС. Первое преимущество МСС состоит в том, что он не требует никаких предположений о характере зависимости T(t); вторым его достоинством является простота вычислений. Очевидный недостаток МСС состоит в отсутствии оценок тренда для первых и последних наблюдений. Кроме того, МСС дает только оценки тренда для моментов наблюдений, и не дает формулу зависимости T(t).
Если ряд имеет циклическую компоненту, то ее значения можно вычислить после определения тренда. Пренебрегая случайными возмущениями, для аддитивной модели ряда из формулы (40) получаем:
SY-T, (43)
для мультипликативной модели из формулы (41) получаем:
SY/T. (44)
Полученные приближенные значения циклической составляющей далее обрабатываются следующим образом:
усредняются по периодам (так как в идеале значения циклической составляющей от периода к периоду должны повторяться);
выравниваются таким образом, чтобы среднее значение за цикл для аддитивной модели было равно 0, а для мультипликативной модели – 1.
2. Решение типовых задач в среде Excel
2.1. Аналитическое определение тренда временного ряда
2.1.1. Задание
Для временного ряда, представленного таблицей 13 «Динамика выпуска продукции Финляндии»* выполнить следующие исследования:
С помощью мастера диаграмм получить уравнение, график и значение коэффициента детерминации R2 для следующих трендов: линейного, логарифмического, степенного, полиномиального третьей и шестой степени, экспоненциального.
Выбрать из полученных трендов наиболее соответствующий наблюдениям и логике задачи.
Исследовать показательный тренд с помощью функции ЛГРФПРИБЛ.
Таблица 13. Динамика выпуска продукции Финляндии
Год |
Выпуск продукции (млн.долл.) |
Год |
Выпуск продукции (млн.долл.) |
|
|
1054 |
|
11172 |
|
|
1104 |
|
14150 |
|
|
1149 |
|
14004 |
|
|
1291 |
|
13068 |
|
|
1427 |
|
12578 |
|
|
1505 |
|
13471 |
|
|
1513 |
|
13617 |
|
|
1635 |
|
16356 |
|
|
1987 |
|
20037 |
|
|
2306 |
|
21748 |
|
|
2367 |
|
23298 |
|
|
2913 |
|
26570 |
|
|
3837 |
|
23080 |
|
|
5490 |
|
23981 |
|
|
5502 |
|
23446 |
|
|
6302 |
|
29658 |
|
|
7665 |
|
39573 |
|
|
8570 |
|
38435 |