Материал: ТАУ Лекция ч2
© К.Ю. Поляков, 2009
Интеграл от f (x) на некотором интервале [x1; x2 ] определяет вероятность того, что случайная величина x при очередном испытании окажется в этом интервале, то есть выполнится неравенство x1 ≤ x ≤ x2 .
Чему же равна вероятность точного равенства x = x1 для некоторого заданного x1 ? Чтобы
x1
ее найти, нужно взять интеграл ∫ f (x) dx . Поскольку верхний и нижний пределы интегрирова-
x1
ния совпадают, для «обычных» функций такой интеграл равен нулю, то есть, в рассмотренном выше примере вероятность выбрать наугад резистор с сопротивлением 100 Ом равна нулю.
x1
Может ли интеграл ∫ f (x) dx быть ненулевым? Оказывается да, но для этого функция
x1
f (x) в точке x1 должна быть бесконечной. Этим свойством обладает, например, так называемая дельта-функция (или функция Дирака) δ(x) , которая определяется так:
0, |
x ≠ 0 |
∞ |
||
∫δ(x) dx =1. |
||||
δ(x) = |
∞, |
x = 0 |
||
|
−∞ |
|||
Дельта-функция равна нулю во всех точках, кроме x = 0 , где она обращается в бесконечность, причем интеграл от нее по всей оси равен 1.
Когда плотность вероятности может содержать дельта-функции? Предположим, что мы измеряем сигнал x на выходе цифрового устройства, который может принимать только два значения, например, 0 или 1. Такой сигнал, принимающий значения только из заранее заданного множества, называется дискретным.
Пусть вероятность появления нуля равна 0,4, а вероятность появления единицы – 0,6. Попытаемся построить плотность распределения этого сигнала, используя интуитивные соображения («здравый смысл»).
Во-первых, сигнал не может принимать другие значения, кроме 0 и 1, поэтому плотность вероятности равна нулю везде, за исключением этих двух точек. Во-вторых, вероятность того, что x = 0 ненулевая (равна 0,4), и вероятность того, что x =1 равна 0,6. Таким образом, имеем (при любом малом ε )
0∫+εf (x) dx = 0,4 |
и |
1+∫ε f (x) dx = 0,6 . |
0−ε |
|
1−ε |
Отсюда следует, что плотность распределения f (x) содержит
дельта-функции в точках x = 0 и x =1 (интегралы от которых равны соответственно 0,4 и 0,6) и равна нулю в остальных точках2. Иначе говоря,
f (x) = 0,4 δ(x) +0,6 δ(x −1) .
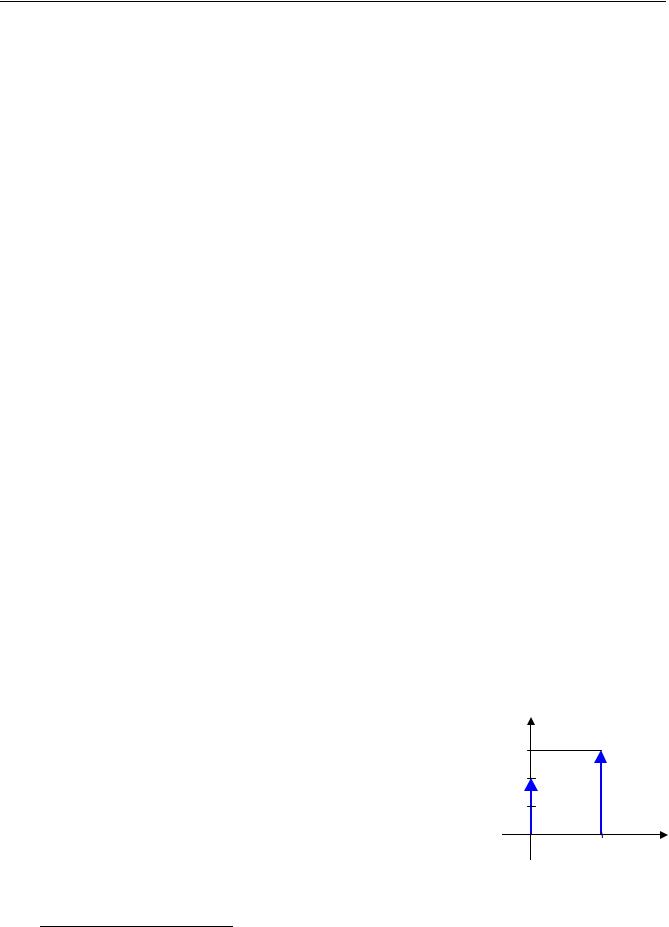
Дельта-функцию, имеющую бесконечное значение, на графике обозначают стрелкой, высота которой равна ее площади (см. рисунок справа).
f (x)
0,6
0,4
0,2
0 |
1 |
x |
2Может случиться и так, что плотность распределения представляет собой сумму «нормальной» функции и дель- та-функций. Например, мы знаем, что в коробке есть 20 резисторов, сопротивление которых точно равно 100 Ом, а сопротивление остальных может быть любым в пределах допуска, от 97 до 103 Ом.
6
|
|
|
|
|
|
|
|
|
© К.Ю. Поляков, 2009 |
|||
1.5. Средние значения |
|
|
|
|
|
|
|
|
|
|||
|
Плотность распределения вероятности дает полную |
n |
|
|
|
∆ |
|
|
||||
информацию о свойствах случайной величины. Напри- |
N |
|
|
|
|
|
|
|||||
мер, с помощью гистограммы несложно найти среднее |
|
|
|
|
|
|
|
|||||
значение. |
|
|
|
|
|
|
|
|
|
|
|
|
|
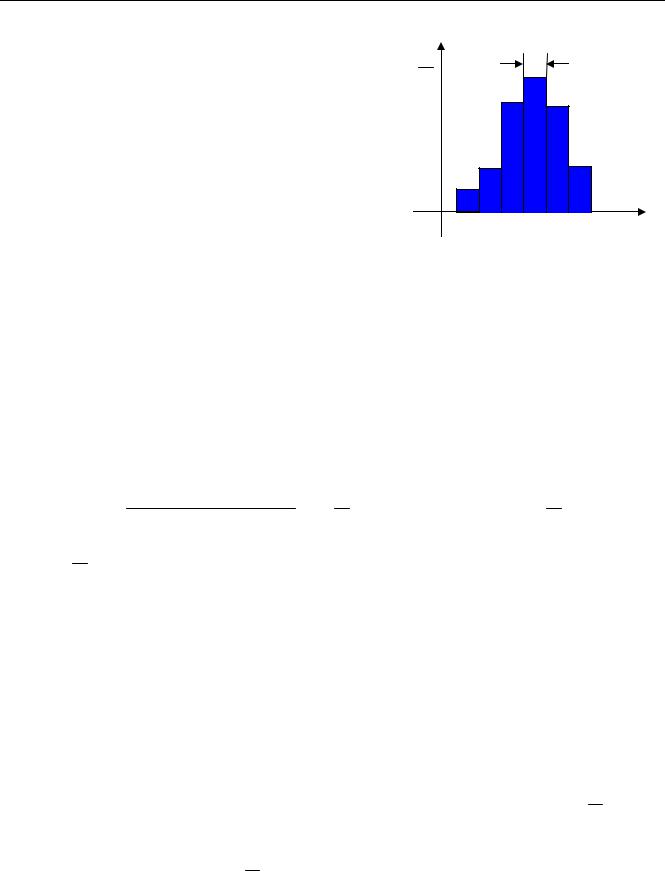
Вернемся к примеру с резисторами. Пусть у нас |
|
|
|
|
|
|
|
||||
есть гистограмма, построенная по результатам испыта- |
|
|
|
|
|
|
|
|||||
ний, где отложены доли резисторов, сопротивление |
ко- |
|
|
|
|
|
|
|
||||
торых оказалось в данном интервале (см. рисунок). Как |
|
97 |
98 |
99 100 101 102 103 |
x , Ом |
|
||||||
(приближенно) найти среднее значение сопротивления? |
|
|
||||||||||
|
|
|
|
|
|
|
||||||
Сложность в том, что мы не знаем сопротивлений отдельных резисторов и их количества. Тем |
||||||||||||
не менее, гистограмма дает всю необходимую информацию. |
|
|
|
|
|
|
||||||
|
Можно приближенно считать, что все резисторы, попавшие в интервал [97;98] (их коли- |
|||||||||||
чество равно n1 ), имеют сопротивление |
x1 = 97,5 Ом (середина интервала). Более точной ин- |
|||||||||||
формации все равно нет. Тогда общая сумма сопротивлений всех этих резисторов равна x1 n1 . |
||||||||||||
Повторяя те же рассуждения для остальных интервалов, получаем, что сумма сопротивлений |
||||||||||||
всех |
резисторов |
равна |
x1 n1 + x2 n2 +K+ xK nK , |
где |
K |
– |
количество |
интервалов, |
а |
|||
xi (i =1,K, K) – |
середина каждого из интервалов. Чтобы найти среднее значение, эту сумму |
|||||||||||
нужно разделить на общее количество резисторов N : |
|
|
|
|
|
|
|
|
||||
|
x = x1 n1 + x2 n2 +K+ xK nK |
= x1 n1 + x2 |
n2 |
|
|
nK |
K |
|
|
|
||
|
+K+ xK |
= ∑xi ni . |
|
|
||||||||
|
|
|
N |
N |
N |
|
|
N |
i=1 |
N |
|
|
Значения ni (i =1,K, K) |
– это доли от общего количества, то есть, высоты столбцов гистограм- |
|||||||||||
|
N |
|
|
|
|
|
|
|
|
|
|
|
мы. Таким образом, мы можем (приближенно) найти среднее значение по гистограмме, не зная |
||||||||||||
ни сопротивлений отдельных резисторов, ни даже их количества. |
|
|
|
|
|
|||||||
|
В теории вероятности среднее значение x называется математическим ожиданием слу- |
|||||||||||
чайной величины x и обозначается E{x}. Если известна плотность распределения f (x) , сумма |
||||||||||||
заменяется интегралом |
|
|
|
|
|
|
|
|
|
|
||
x = E{x} = ∞∫x f (x) dx .
−∞
Аналогично можно найти среднее значение любой функции, умножив ее на плотность распре-
деления и проинтегрировав произведение на всей оси. Например, средний квадрат x2 вычисляется так
x2 = E{x2} = ∞∫x2 f (x) dx .
−∞
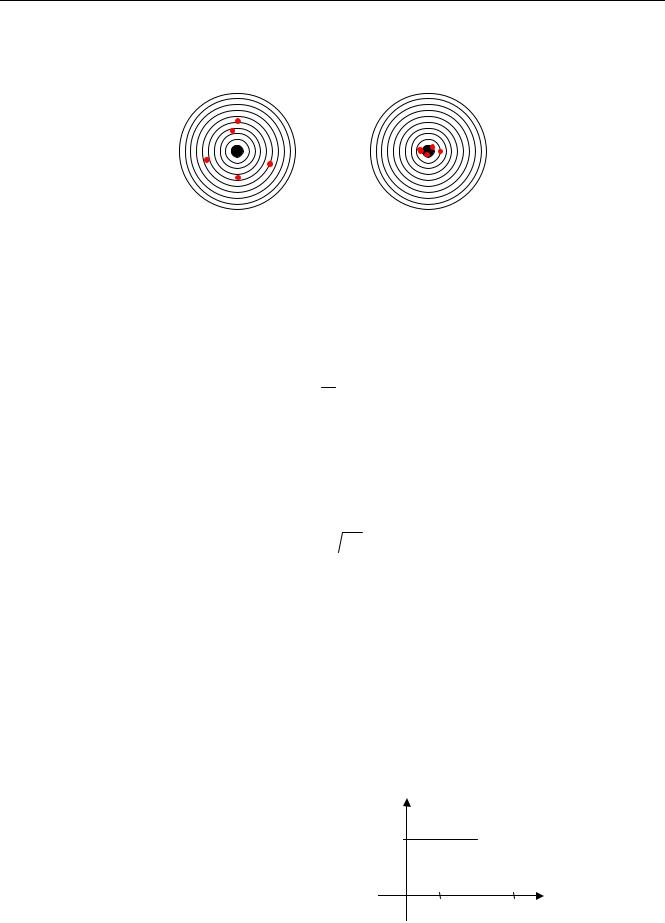
Среднее значение (математическое ожидание) не может полностью характеризовать случайную величину. На рисунках показаны мишени, пораженные двумя стрелками (каждый сде-
7
© К.Ю. Поляков, 2009
лал по 5 выстрелов). В обоих случаях математическое ожидание – это центр мишени, то есть «в среднем» они бьют по центру. Однако всем понятно, что второй явно стреляет лучше. Как выразить это в виде числа?
У первого стрелка больше разброс точек попадания относительно средней точки. на языке теории вероятности разброс называется дисперсией – эта величина равна среднему квадрату отклонения от среднего значения x . То есть, дисперсия вычисляется по формуле:
Dx = E{(x − x)2} = ∞∫(x − x)2 f (x) dx .
−∞
Раскрыв скобки в подынтегральном выражении, можно показать, что дисперсия равна разности среднего квадрата и квадрата математического ожидания:
Dx = x2 −(x)2 .
Если математическое ожидание равно нулю, дисперсия и средний квадрат совпадают.
Использовать дисперсию не очень удобно, поскольку ее единицы измерения не совпадают с единицами измерения исходной величины (если x измеряется в метрах, то дисперсия – в квадратных метрах). Поэтому на практике чаще применяют среднеквадратическое отклонение (СКВО)– квадратный корень из дисперсии:
σx =  Dx .
Dx .
Виностранной литературе эту величину называют стандартное отклонение.
1.6.Какие бывают распределения?
Существует бесчисленное множество разных распределений, но в технике применяются лишь некоторые из них.
1.6.1. Равномерное распределение
Самое простое – это равномерное распределение. Например, снег в безветренную погоду ложится на плоскую поверхность равномерно – ровным слоем, который имеет одинаковую толщину во всех точках. Обычно предполагается, что ошибка квантования непрерывных сигналов в цифровом компьютере имеет равномерное распределение. Равномерное распределение на интервале [a;b] описывается плотностью распределения
|
0, |
x < a |
f (x) |
|
|
|
|||
|
1 |
|
|
|
|
||||
|
1 |
|
|
|
|
|
|||
|
|
|
b −a |
|
|
|
|||
f (x) = |
|
, a ≤ x ≤ b |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
b −a |
x > b |
|
|
|
|
|
|
|
|
|
0, |
|
|
|
|
|
|
|
|
|
|
|
0 |
a |
b x |
||||
|
|
|
|||||||
Среднее значение такой случайной величины равно x = (a +b) / 2 , а дисперсия
8
© К.Ю. Поляков, 2009
|
b |
|
a +b 2 |
1 |
|
(b −a)2 |
|
||
Dx = |
∫a |
x − |
|
|
|
dx = |
|
. |
|
2 |
b −a |
12 |
|||||||
|
|
|
|
|
|||||
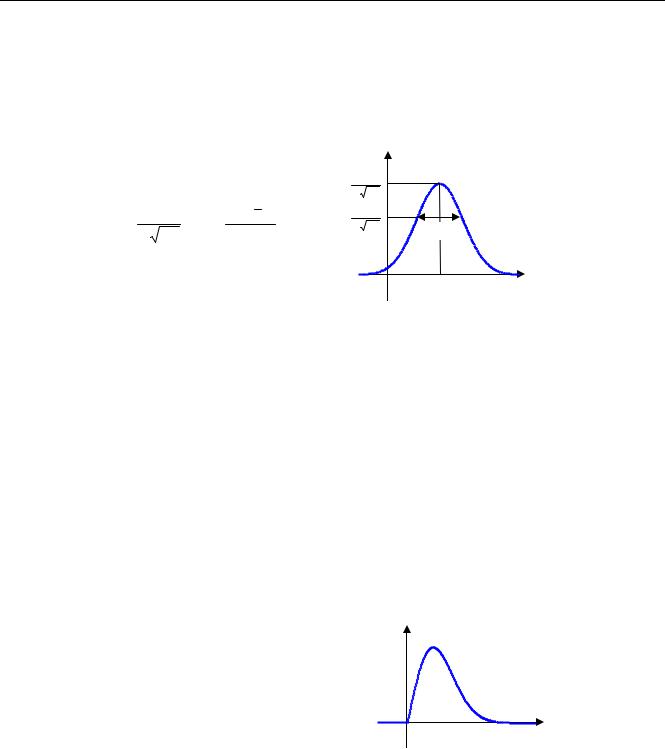
1.6.2. Нормальное распределение (распределение Гаусса)
Самое важное распределение в практических задачах – нормальное распределение (распределение Гаусса), для которого график плотности распределения имеет форму колокола:
f (x)
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
σ |
2π |
|
f (x) = |
1 |
|
(x − x) |
2 |
|
0,607 |
|
||
exp− |
|
|
σ |
2π |
2σ |
||||
σ |
2π |
|
2σ |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|||
0 |
x |
x |
Здесь x – среднее значение, а σ – среднеквадратическое отклонение случайной величины. Распределение Гаусса обладает несколькими замечательными свойствами:
1)сумма (и любая линейная комбинация) случайных величин с нормальными распределениями тоже имеет нормальное распределение;
2)если на величину действует множество независимых помех, ее плотность вероятности стремится к нормальному закону;
3)при прохождении случайного сигнала с нормальным распределением через линейную систему сигнал на выходе тоже имеет нормальное распределение.
Если нет никаких теоретических или экспериментальных данных о распределении случайной величины (например, шума измерений), чаще всего предполагают, что это распределение – нормальное.
1.6.3.Другие распределения
Вспециальных задачах применяют и другие распределения. Если случайная величина имеет равномерное распределение с центром в нуле, ее модуль распределен по закону Рэлея:
f (x)
|
x |
|
x2 |
|
|
|
|
|
|
|
|
exp− |
|
|
|
, |
x ≥ 0 |
|
2 |
|
2 |
|||||
f (x) = σ |
|
2σ |
|
|
|
|||
|
|
|
|
|
|
|||
|
|
|
0, |
|
|
|
|
x < 0 |
|
|
|
|
|
|
|
||
0 |
x |
Например, так распределяются высоты волн при морском волнении.
Для моделирования случайных события в компьютерных моделях используют датчики псевдослучайных чисел (они похожи на случайные, но каждое следующее вычисляется по некоторой формуле, использующей предыдущие значения). Большинство датчиков «выдают» равномерно распределенные значения, из которых с помощью математических операций можно получить другие распределения.
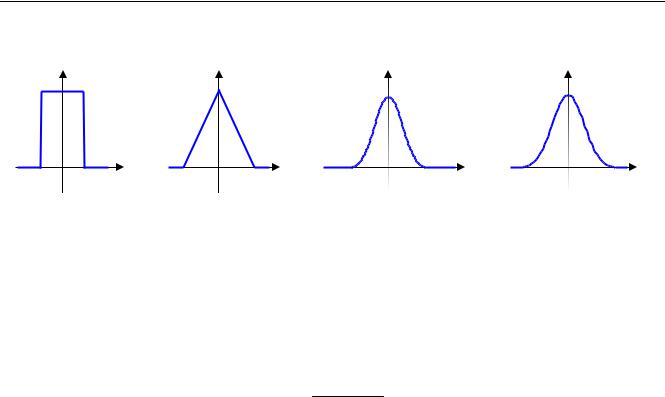
Например, рассмотрим сумму нескольких независимых случайных значений, равномерно распределенных на симметричном интервале [−a;a] . Можно показать, что для суммы двух чи-
сел получится треугольное распределение. Таким образом, складывая два случайных числа, по-
9
© К.Ю. Поляков, 2009
лученных со стандартного датчика с равномерным распределением, мы получим числа с тре-
угольным распределением. Для суммы трех чисел график |
f (x) |
состоит из кусочков парабол: |
||
f (x) |
f (x) |
f (x) |
N = 3 |
f (x) |
|
N =1 |
N = 2 |
N = 7 |
|
−a 0 a x |
−2a 0 |
2a x |
−3a 0 |
3a x |
0 |
x |
При увеличении N график плотности распределения вероятностей становится всё больше похож на «колокол» нормального распределения. Доказано, что при больших N распределение суммы N чисел действительно стремится к нормальному. Более того, это справедливо для суммы большого количества независимых случайных величин с любым распределением (не обязательно равномерным).
Можно показать, что дисперсия суммы независимых случайных величин равна сумме дисперсий отдельных величин. Поэтому если взять a = 0,5 , то дисперсия суммы 12 чисел, рав-
номерно распределенных на интервале [−a;a] , будет равна
Dz =12 (a −(−a))2 =1 . 12
Этот прием (сложение 12 чисел) используют для получения случайных величин с нормальным распределением и единичной дисперсией.
10