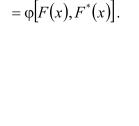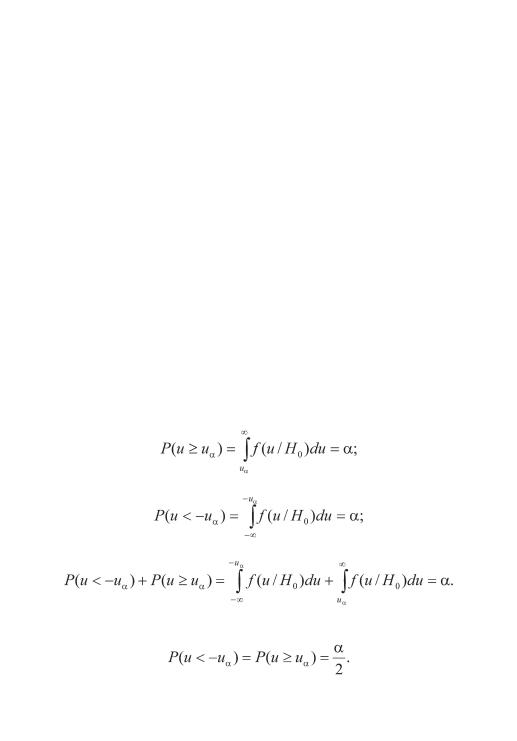1.Закон распределения ПС должен зависеть от нулевой и альтернативной гипотез.
2.Закон распределения должен быть известен полностью, включая и его параметры.
Наибольшее распространение получили ПС, распределенные по нормальному закону, законам хи-квадрат, Стьюдента, Фишера.
Следует отметить, что в литературе по математической статистике используют обозначение ПС различными буквами. Например, ПС, распределенный по нормальному закону, часто обозначают буквой Y или Z, по закону хи-квадрат — x2, по закону Стьюдента — T, по закону Фишера — F.
. Закон распределения ПС должен быть инвариантен к виду закона распределения исследуемой случайной переменной (не должен изменяться при смене закона распределения случайной переменной).
4.Закон распределения ПС должен быть критичен по отношению к проверяемой гипотезе. Это означает, что условные
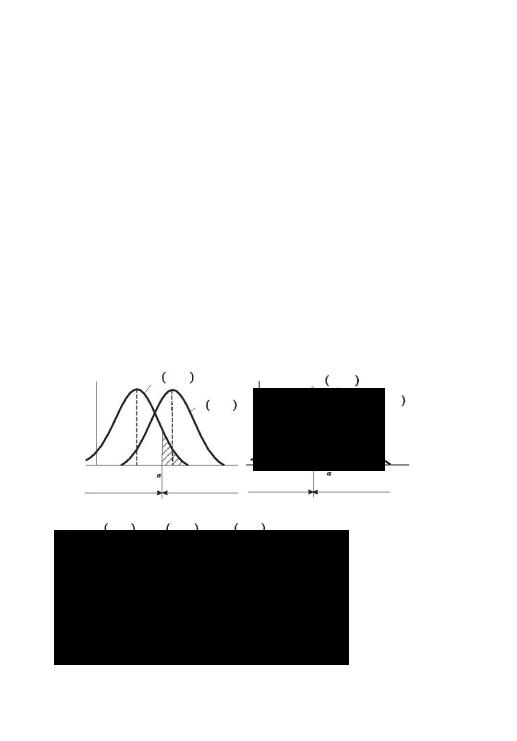
плотности распределения f (u/H0) и f (u/H1) должны существенно отличаться друг от друга.
Полученное по результатам испытаний значение ПС называют частным значением и обозначают u*.
Для проверки гипотезы необходимо задать правило, на основе которого множество возможных значений u* ПС разбива-
ется на два подмножества: подмножество u0, при попадании в которое принимается гипотеза H0, и подмножество u0, при попадании в которое гипотеза H0 отклоняется (принимается гипотеза H1). Область, соответствующую подмножеству u0, на-
зывают областью допустимых значений (областью принятия
гипотезы H0), а область, соответствующую подмножеству u1,
критической областью ПС.
Показатель согласованности представляет собой скалярную случайную величину. Поэтому допустимая и критическая области представляют интервалы возможных значений ПС и, следовательно, существует точка, которая их разделяет. Эту точку называют критической точкой (границей).