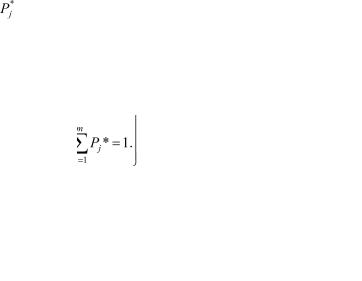4.Желательно, чтобы оценка была прочной (робастной) или свободной (не зависящей от распределения).
Часто до проведения исследований закон распределения случайной величины X неизвестен. Поэтому не ясно, какую
оценку принять для параметра x. Целесообразно в этом случае воспользоваться оценкой, эффективность которой при некоторых распределениях может быть меньше единицы, но вид
еене меняется с изменением закона распределения.
5.Размерность оценки должна совпадать с размерностью оцениваемого параметра.
На практике получить оценку, удовлетворяющую всем перечисленным требованиям, удается не всегда. Поэтому необходимо анализировать те последствия, к которым приводят отступления от того или иного требования.
Оценки, удовлетворяющие указанным требованиям, могут быть получены различными методами. Поскольку в дальнейшем будут использоваться уже полученные оценки параметров, то здесь эти методы не рассматриваются. Они достаточно полно изложены в литературе по математической статистике.
12.3.Оцениваниезаконовраспределенияслучайныхвеличин
Как было отмечено в п. 11.1, одной из задач статистической обработки результатов испытаний является установление вида закона распределения случайной величины. На первом этапе решения этой задачи по результатам проведенных испытаний строят статистические функцию и плотность распределения. Анализ полученных графиков и природы исследуемой случайной величины обычно позволяет выдвинуть гипотезу о виде закона ее распределения. Затем по результатам испытаний проверяют справедливость выдвинутой гипотезы.
В данном пункте рассмотрим только первый этап решения указанной задачи.
Значения, принятые случайной величиной X при испытаниях, удобно представить в виде табл. 12.1, называемой прос-
той статистической совокупностью [5].

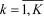 . Вариационный ряд, представленный в форме табл. 12. ,
. Вариационный ряд, представленный в форме табл. 12. ,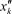 , по формуле в которой суммирование распространяется на значения
, по формуле в которой суммирование распространяется на значения 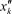 , меньшие
, меньшие 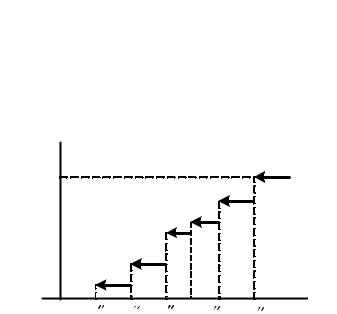

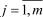 , включая его левую границу.
, включая его левую границу.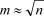 [15]. При этом желательно, чтобы выполнялось условие
[15]. При этом желательно, чтобы выполнялось условие