Материал: 6251
x1(t0 )= x0 , x2 (t0 )= 0 ,
конечные условия для вектора p
p1(t f )= −b1 = 0, p2 (t f )= −b2 = −1. |
|
||||
Поскольку pɺ2 = 0, а p2 (t f |
)= −1, то |
|
p2 (t)= const = −1. Подставляя оп- |
||
тимальное управление в канонические уравнения, получим |
|
||||
xɺ |
= −ax + γM sign p |
, |
|
||
1 |
1 |
|
1 |
|
(4.3.10) |
pɺ |
= ap + 2x |
, |
|
||
|
|
||||
1 |
1 |
1 |
|
|
|
с граничными условиями x1(t0 )= x0 и p1(t f )= 0 .
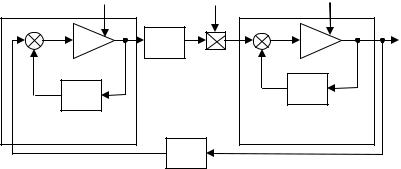
По сути, мы получили двухточечную краевую задачу. Решение нелинейных уравнений (4.3.10) при заданных граничных условиях даст уравнение линии переключения p1(t), и, в соответствии с (4.3.9) – оптимальное управление u . Процедура решения заключается в выборе наугад значения p1(t0 )= p0 и в определении, после некоторых проб и ошибок, функций x1(t) и p1(t), удовлетворяющих другому граничному условию p1(t f )= 0 . Моделирование уравнений (4.3.10) приведено на рис. 4.3.
Нужно отметить, что закон управления не может быть выражен в виде аналитической функции координат системы.
246
p0 |
M |
x0 |
p1 |
|
x1 |
s-1 |
sign |
s-1 |
a |
|
-a |
|
|
|
сопряженная система |
|
основная система |
|
|
|
|
2 |
|
Рис. 4.3. Моделирование оптимального управления
Сделаем некоторые выводы, касающиеся принципа максимума.
1.Разные задачи оптимального управления можно привести к обобщённой задаче оптимального управления по отношению к переменным состояния. При этом применяется процедура инвариантного увеличения размерности пространства состояний.
2.В общем случае метод максимума дает необходимые условия экстремума, однако, если процесс линейный, то этот метод дает ещё и достаточные условия.
3.Применение принципа максимума приводит к тем же трудностям, что и классическое вариационное исчисление, то есть к необходимости решения двухточечной краевой задачи.
4.Принцип максимума можно применять не только системам без ограничений; его применение предполагает наличие физических ограничений на управляемый процесс и на управляющие воздействия.
247
5.Несмотря на необходимость решения двухточечной краевой задачи, метод максимума позволяет определить характерные черты и общую структуру системы оптимального управления.
4.4. Динамическое программирование
Из вышеизложенного ясно, что проблемы оптимизации сводятся к решению двухточечной краевой задачи. Эффективным методом решения такого рода задач является разработанный Ричардом Беллманом и его сотрудниками метод, названный ими динамическим программированием. Идея этого метода является выражением концепции инвариантного вложения, согласно которой исходная проблема заменяется рядом более простых проблем.
4 . 4 . 1 . Мно гошаго вые про цессы упр авления
Пусть объект управления задан n-мерным вектором состояния x. Разделим весь процесс управления на N шагов. На первом шаге объект преобразованием x2 = g(x1,u1 ) переводится из состояния x1 в состояние x2 и
выигрыш от этой операции равен R1 = r(x1,u1 ). Задача состоит в определении управления u1, максимизирующего R1. Полученное решение можно назвать одношаговой стратегией оптимального управления. Ясно, что решение одношаговой проблемы элементарно. Максимальный выигрыш при этом даётся выражением
R1 (x1 )= max r(x1 ,u1 ),
u1
248
а решение, доставляющее максимум выигрыша, является оптимальным решением или оптимальной стратегией управления.
Перейдём ко второму шагу. Он преобразованием x3 = g(x2 ,u2 ) переводит достигнутое в результате первого шага состояние x2 в состояние x3. Два шага дают полный выигрыш R2 = r(x1,u1 )+ r(x2 ,u2 ). Теперь задача состоит в определении последовательности управлений u1, u2, доставляющих максимум суммарному выигрышу. Таким образом получаем двухшаговую стратегию. Максимальный выигрыш получим путём определения максимума уже по двум функциям, и равен он будет
R2 (x1 )= max[r(x1,u1 )+ r(x2 ,u2 )].
u1,u2
Понятно, что двухшаговая задача является более сложной, чем одношаговая.
Сложность стремительно возрастает с увеличением количества шагов. Для N-шагового процесса задача состоит в выборе N-шаговой стратегии u1,u2,...uN , доставляющей максимум общему выигрышу
RN = ∑N r(xk ,uk ). Максимальный выигрыш определится выражением
k=1
RN (x1 )= max∑N |
r(xk ,uk ), |
{uk } k=1 |
|
где максимум берётся по управлениям на всех N шагах.
Определение максимума на основе известных элементарных методов приводит к системе из N уравнений, которые получаются приравнивани-
ем нулю частных производных по uk от RN (x1 ) (k=1,2,…,N).
249
Очевидно, что в случае большого N решение проблемы оптимизации становится чрезвычайно громоздким и поэтому решение задачи «в лоб» нереально.
4 . 4 . 2 . Пр инцип о птим альности
Задача определения N-шаговой оптимальной стратегии может быть облегчена на основе применения фундаментального принципа динамического программирования – принципа оптимальности: оптимальная политика или оптимальная стратегия управления обладает свойством, что какое бы ни было начальное состояние или начальное решение, последующее решение должно быть оптимальной стратегией по отношению к состоянию, возникшему в результате первого решения.
Проиллюстрировать принцип оптимальности можно с применением понятия пространства состояний. Пусть имеется оптимальная траектория в пространстве состояний объекта, переводящая изображающую точку x(t0 ) в точку x(tf ) (рис. 4.4). Оптимальность траектории означает, что
некоторый критерий оптимальности R = t∫f r(x,u,t)dt принимает экстре-
t0
мальное (предположим для определённости максимальное) значение.
250