Материал: Сравнительный анализ методов кластерного анализа в решении задач группировки
Глава 3. Алгоритм разбиения торговых точек
В качестве исследуемого объекта взято торговое предприятие, имеющее 36 651 торговую точку, реализующую кондитерскую продукцию. В списке реализуемых предприятием товаров свыше 350 единиц продукции.
Целью данного исследования будет сравнительный анализ методов кластерного анализа в решении задач:
. Изучение профиля клиента и анализ соответствия взаимосвязей заданных признаков;
2. Разделение на кластеры - выделение однородных групп;
. Разбиение на однородные группы ассортимента торгового предприятия.
.1 Профиль клиента
По данным исследования Galileo, проведенного во втором полугодии 2016 года, было опрошено около 42 миллионов людей, употребляющих кондитерские изделия.
Из этого опроса следует, что основными потребителями кондитерских изделий являются женщины.
Это можно связать с тем, что женщины традиционно получают в качестве подарка шоколадные изделия, а также большая часть любителей кондитерских изделий - женщины. Это наглядно можно увидеть на рисунке 10.
Далее рассмотрим потребительские предпочтения аудитории в зависимости от возраста:
· до 16 лет - основные потребители шоколада в виде фигур;
· от 16 до 24 лет - основные потребители шоколадных батончиков;
· шоколад в плитке в большинстве случаев приобретается женщинами от 25 до 34 лет;
· люди от 25 до 45 лет - основные покупатели конфет в коробках;
· От 45 и старше предпочитают развесные конфеты.
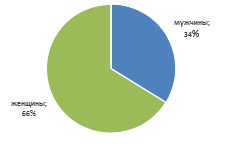
Рисунок 14 Потребление кондитерских изделий в зависимости от
пола
На рисунке 12 изображено распределение общего объема потребления на 3
группы, в зависимости от достатка: А-низкий, В-средний, С-высокий. Львиная доля
потребителей приходится на группу со средним достатком - 54%, затем следует
группа с низким достатком - 29%, наименьший вклад вносит группа с высоким
доходом - 17%.
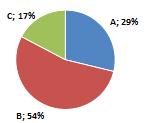
Рисунок 15 Потребление кондитерских изделий в зависимости от
дохода
Данный график иллюстрирует предпочтения аудитории в выборе места покупки, рассмотрим также распределение в зависимости от дохода. Очевидно, что наибольшее число покупок совершается в гипер и супермаркетах, что справедливо по отношению к каждой из доходных групп.
Доля покупок в супермаркетах составляет практически половину (46%) для группы С, исходя из чего можно сделать вывод о целесообразности расширения линейки товаров, популярных среди людей с высоким достатком.
На людей со средним достатком приходится 41% покупок в супермаркетах, а
на людей с низким достатком самая маленькая доля - 37%. Далее идет доля покупок
в небольших магазинах самообслуживания, покупки в таких магазинах совершают все
три группы в равных пропорциях. Наименьшая доля приходится на рынки и ларьки, там
основной вклад вносят представители группы А, которая включает в себя большое
количество пенсионеров, которые зачастую совершают покупки на рынке «по
привычке».
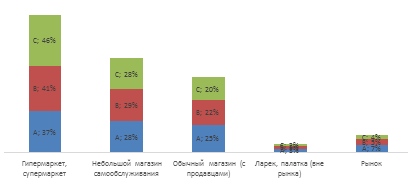
Рисунок 16 Места покупок кондитерских изделий в зависимости
от дохода
Следующий график наглядно иллюстрирует степень важности того или иного
признака товара для каждой из трех доходных групп. Для групп А и В наиболее
важным фактором является цена, а внешний вид упаковки и страна производства
товара имеет небольшое значение. Поведение представителей группы с высоким
доходом будет немного отличаться, там, помимо цены, важное значение имеет бренд
и внешний вид и страна производства товара.
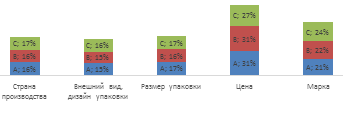
Рисунок 17 Приоритеты при выборе кондитерских изделий различных доходных групп
.2 Анализ соответствий
Анализ соответствий используется для визуализации таблиц. Этот метод позволяет выявить взаимосвязь между признаками в столбцах и строках таблицы.
Красный квадрат соответствует категориям, расположенным в столбцах таблицы, а синий в строках. Чем ближе точки друг другу, тем больше связаны между собой эти категории по рассматриваемым характеристикам.
Рассмотрим далее проведенный анализ соответствий потребления кондитерских изделий по полу и возрасту, проиллюстрированный на рисунке 7, а также рисунок 8, на котором показано потребление различных категорий продукции в зависимости от дохода потребителей.
Сперва рассмотрим предпочтения трех групп мужчин: в возрасте 16-19 лет,
20-24 и 25-34, так как их потребительские предпочтения можно охарактеризовать
как практически идентичные.
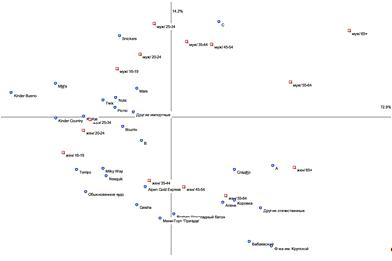
Рисунок 18 Анализ соответствий популярных конфет по возрасту
и полу
Мужчины этих возрастных групп предпочитают шоколадные батончики Snickers, Mars, Nuts, Twix, Picnic, Kinder bueno и конфеты M&m’s. Продукция такого типа относится к категории «Шоколадные батончики и другой шоколад в мелкой упаковке» и в наибольшей степени будут популярны среди лиц с низким доходом.
Далее следуют четыре оставшиеся возрастные группы мужчин: 35-44, 45-54,
55-64, 65-74. Для них также будет характерно примерно одинаковое
потребительское поведение и они являются крайне пассивными потребителями. Для
этих групп будет справедливо утверждение, что с ростом уровня дохода обратно
пропорционально будет изменяться уровень потребления, то есть среди мужчин в
возрасте 35-74, имеющих высокий доход, будет наиболее низкая потребительская
активность.
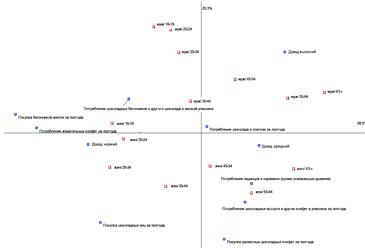
Рисунок 19 Потребление конфет по категориям
Очевидно, что ниша включающая в себя платежеспособных мужчин 35-74 является весьма перспективной и при этом незанятой, но существующий набор товаров не способен удовлетворить запросы этой категории потребителей. Исходя из вышесказанного, можно сделать ввод, что имеет смысл воздействовать на данную целевую аудиторию каким-то абсолютно новым продуктом, способным привлечь потребителей.
Следующим этапом будет описание групп женщин в возрасте 16-19, 20-24, 25-34, которые имеют схожее потребительское поведение. Упомянутые группы, как правило, предпочитают шоколадные батончики, часть из них будут аналогичны тем, что предпочитают мужчины такого же возраста - Picnic, Twix, Nuts и др., а также среди женщин высокую популярность имеют батончики Tempo, bounty, Kit Kat, Milky way, Kinder country, обыкновенное чудо.
Для этих групп также будет справедливо правило низкого дохода, по мере его увеличения популярность шоколадных батончиков будет снижаться. Далее следует группа женщин 35-44, для них самым популярным выбором является Alpen Gold, затем Geisha и мини-торт причуда, это утверждение справедливо для лиц с низким и средним доходом, в равной степени. По мере увеличения возраста предпочтительными становятся (группы 45-54, 55-64, 65-74): Аленка, Коровка, Сладко, конфеты группы “Крупской” и другие отечественные. Наиболее справедливо это по отношению к лицам со средним доходом. Оценивая потребление кондитерских изделий в целом, нужно отметить, что 2/3 всего потребления приходится на женскую долю населения.
.3 Основная идея кластерного анализа
Перед применением алгоритма кластеризации все торговые точки разбиваются на стратам. Алгоритм применяется отдельно к каждой из полученных страт. Полученные для отдельных групп кластеры затем объединяются в один итоговый набор кластеров.
Опишем детали алгоритма кластеризации. Обозначим количество торговых
точек, к которым применяется алгоритм, через ![]() , множество торговых точек через
, множество торговых точек через ![]() , евклидову метрику через
, евклидову метрику через ![]() , количество признаков через
, количество признаков через ![]() . Количество признаков и, как
следствие, их количество зависят от страты.
. Количество признаков и, как
следствие, их количество зависят от страты.
Прежде всего, значения всех признаков стандартизируются. Стандартизация - это преобразование признака путём вычитания его среднего значения и деления на его стандартное отклонение. Среднее значение и стандартное отклонение вычисляются один раз по данным, по которым делается кластеризации, и являются частью модели кластеризации.
В качестве алгоритма кластеризации мы используем алгоритм KMeans. Этот алгоритм требует задания количества
кластеров и количества инициализаций итерационного процесса кластеризации (или
начальных центроидов). Количество инициализаций зависит от имеющегося в нашем
распоряжении времени на кластеризацию. Для определения количества кластеров мы
применяем алгоритм KMeans с
количеством кластеров ![]() от 2 до 75. Обозначим получающиеся при этом модели
кластеризации через
от 2 до 75. Обозначим получающиеся при этом модели
кластеризации через ![]() , а центроиды через
, а центроиды через ![]() . Для каждого
. Для каждого ![]() мы определяем меру внутрикластерного
разброса
мы определяем меру внутрикластерного
разброса
![]()
Можно рассмотреть модель кластеризации для случая ![]() . В этом случае есть лишь один
центроид
. В этом случае есть лишь один
центроид ![]() , определяемый как поэлементное
среднее всех
, определяемый как поэлементное
среднее всех ![]() . Получающаяся в этом случае мера внутрикластерного разброса
. Получающаяся в этом случае мера внутрикластерного разброса ![]() называется мерой полного разброса
торговых точек:
называется мерой полного разброса
торговых точек:
![]()
Отношение
![]()
можно интерпретировать, как долю необъяснённых различий между торговыми
точками внутри кластеров. Это отношение убывает с ростом ![]() . Мы определяем оптимальное
количество кластеров
. Мы определяем оптимальное
количество кластеров ![]() как
как
![]()
Другими словами, мы выбираем такое минимально количество кластеров, чтобы доля необъяснённых различий составляла не более 20%.
Примечание. Вместо значения 0.2 можно взять любое значение от 0 до 1.
Выбор зависит от ограничений на количество кластеров, а также от вида графика
зависимости отношения ![]() от
от ![]() . Однако, если максимально допустимая доля необъяснённых
различий задана до начала кластеризации, то для поиска
. Однако, если максимально допустимая доля необъяснённых
различий задана до начала кластеризации, то для поиска ![]() не обязательно строить кластерные
модели для всех
не обязательно строить кластерные
модели для всех ![]() от 2 до 75. Можно применить метод бинарного поиска, что
существенно повышает скорость кластеризации.
от 2 до 75. Можно применить метод бинарного поиска, что
существенно повышает скорость кластеризации.
В результате выполнения кластеризации мы получаем следующие компоненты полной модели кластеризации:
· ![]() - средние значения признаков для
страты
- средние значения признаков для
страты ![]() и типа
и типа ![]() ;
;
· ![]() - стандартные отклонения признаков
для страты
- стандартные отклонения признаков
для страты ![]() и типа
и типа ![]() ;
;
· ![]() - оптимальное количество кластеров
для страты
- оптимальное количество кластеров
для страты ![]() и типа
и типа ![]() ;
;
· ![]() - модель кластеризации, полученная
при оптимальном количестве кластеров, для страты
- модель кластеризации, полученная
при оптимальном количестве кластеров, для страты ![]() и типа
и типа ![]() .
.
Алгоритм применения полной модели кластеризации состоит в следующем.
Пусть есть торговая точка типа ![]() , относящаяся к страте
, относящаяся к страте ![]() , заданная вектором признаков
, заданная вектором признаков ![]() . По вектору
. По вектору ![]() определяем вектор
определяем вектор ![]() с элементами
с элементами
![]()
К полученному вектору ![]() применяем модель кластеризации
применяем модель кластеризации ![]() . В результате получаем номер
кластера
. В результате получаем номер
кластера ![]() . Таким образом, «номер кластера» в
рамках полной модели кластеризации, состоит из трёх частей:
. Таким образом, «номер кластера» в
рамках полной модели кластеризации, состоит из трёх частей:
· страта;
· тип;
· номер кластера согласно модели кластеризации для страты и типа (всюду далее этот номер будет называться просто номером кластера).
3.4 Признаки для кластеризации
Для кластеризации необходимо составить список признаков, описывающих торговые точки. Для характеристики торговых точек использовались показатели:
· Расстояния до мест притяжения населения (далее МПН);
· Конкурентная среда. Расстояние до объектов транспортной инфраструктуры и других торговых точек KA-сетей и не KA-сетей (определяются расстояния до ближайшего объекта и количество объектов в радиусе 1000 метров);
· Платёжеспособность населения в окрестности торговой точки.
Формально, к признакам также относятся страта и тип торговой точки. Однако, кластеризация по этим признакам не проводится.
Список признаков для торговых точек:
) доход населения (income);
2) средняя стоимость 1 квадратного метра жилья (sqm_price;);
) средняя стоимость аренды однокомнатной квартиры (rent_price);
) количество МПН произвольного типа в радиусе 1000 метров (num_in_radius_mpn_all);
) количество торговых точек не KA-сетей в радиусе 1000 метров (num_in_radius_tt);
) количество торговых точек KA-сетей в радиусе 1000 метров (num_in_radius_ka);
) количество ж/д станций в радиусе 1000 метров (num_in_radius_railway_station);
) количество станций метро в радиусе 1000 метров (поле num_in_radius_subway_station);
) количество остановок наземного общественного транспорта в радиусе 1000 метров (num_in_radius_city);
) расстояние до ближайшего МПН произвольного типа (dist_to_closest_mpn);
) расстояние до ближайшей ж/д станции (pts_railway_station_d01_distance);