Материал: Сравнительный анализ методов кластерного анализа в решении задач группировки
Ежемесячные продажи составляют 21-46 тысяч рублей. МПН произвольного типа в радиусе 1000 метров отсутствуют. Количество торговых точек не ka-сетей в радиусе 1000 метров равняется 18-28. Торговых точек ka-сетей в радиусе 1000 метров - 2-3 штуки. Ж/д станций в радиусе 1000 метров нет.
Остановок наземного общественного транспорта в радиусе 1000 метров нет у большинства, у некоторых до 3.
Географические характеристики кластера: Далеко до ближайшего МПН произвольного типа, до ближайшей ж/д станции также далеко, как и до ближайшей остановки наземного общественного транспорта. Ближайшая торговая точка не ka-сети рядом. Расстояние до ближайшей торговой точки ka-сети низкое -недалеко (до 1 км).
· 14-й кластер - маленькие населенные пункты с самой низкой степенью торговой активности
Профиль кластера: Самые низкие показатели торговой активности, с минимальным набором магазинов. Средний уровень доходов населения.
Основные количественные и качественные характеристики кластера: Составляет 20% процентов от общего количества торговых точек страты. Данный кластер включает в себя 4188 торговых точек. Доход населения оценивается в 24-26 тысяч рублей, что значительно ниже аналогичных показателей других страт, но выше показателей 12-го и 13-го кластеров данной страты. Ежемесячные продажи составляют 21-38 тысяч рублей.
Полное отсутствие МПН произвольного типа в радиусе 1000 метров.
Количество торговых точек не ka-сетей в радиусе 1000 метров - от 1 до 4 штук, а торговых точек ka-сетей в радиусе 1000 метров нет. Отсутствие ж/д станций в радиусе 1000 метров. Нет остановок наземного общественного транспорта в радиусе 1000 метров.
Географические характеристики кластера: До ближайшего МПН произвольного типа далеко, как и до ближайшей ж/д станции и ближайшей остановки наземного общественного транспорта. Расстояние до ближайшей торговой точки не ka-сети: у половины до 400м, остальные далеко. Расстояние до ближайшей торговой точки ka-сети -далеко.
· 15-й кластер - экономически активные населенные пункты с численностью менее 100 тыс. человек.
Профиль кластера: Единственный кластер, где присутствуют признаки экономической активности в страте. Самые высокие показатели торговой активности.
Основные количественные и качественные характеристики кластера: Составляет 12% процентов от общего количества торговых точек страты. Данный кластер включает в себя 2585 торговых точек. Доход населения равен 25-28 тысячам рублей, что значительно ниже аналогичных показателей других страт, но выше показателей других кластеров данной страты. Ежемесячные продажи составляют 24-52 тысяч рублей, что является наивысшим показателем среди всех страт.
Находится 2-7 МПН произвольного типа в радиусе 1000 метров. Количество торговых точек не ka-сетей в радиусе 1000 метров - от 14 до 28 штук, торговых точек ka-сетей в радиусе 1000 метров от 1 до 4 штук. Ж/д станций в радиусе 1000 метров нет. Количество остановок наземного общественного транспорта в радиусе 1000 метров - нет у большинства, у некоторых до 7.
Географические характеристики кластера: До ближайшего МПН произвольного типа близко, а до ближайшей ж/д станции далеко, как и до ближайшей остановки наземного общественного транспорта. Расстояние до ближайшей торговой точки не ka-сети низкое - находятся рядом. Расстояние до ближайшей торговой точки ka-сети - у половины до 500м, у остальных - далеко.
3.7 Кластеризация ассортимента торговых точек
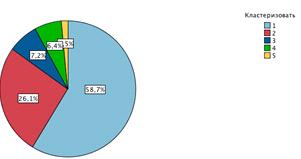
Рисунок 38 Количество ТТ со сгруппированным ассортиментом
Путем применения двухэтапного метода кластерного анализа ассортимент
торговых точек разделился на 5 кластеров. Силуэтная мера составляет 0,2, что
является средним качеством разделения на кластеры. Размеры каждого из них можно
увидеть на рисунке снизу. Самым большим кластером является первый, он составляет
почти 59% (17 622 торговые точки) от всех кластеров. Наименьший по размеру 5
кластер он составляет почти 2% - это 452 торговые точки. Отличия от
кластеризации торговых точек: Деление максимально не похожих друг на друга
товаров , а ТТ объединялись по принципу похожести между ними.
17 Доля каждого кластера
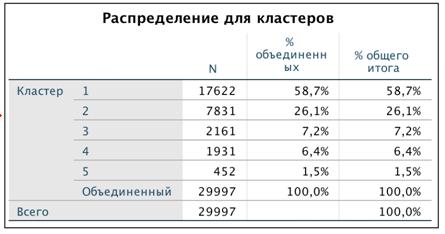
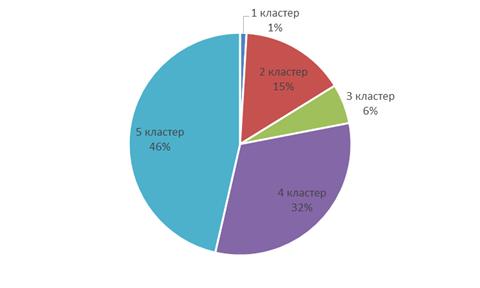
Рисунок 39 Широта ассортимента в каждом кластере
· Первый кластер - это группа ассортимента с самым маленьким выбором. Это конфеты или шоколадные плитки в маленьких упаковках. Такой товар скорее всего представлен на заправка или в маленьких палатках. Пять самых продаваемых товаров в данном кластере: шоколад Бабаевский горький 100 грамм, шоколад Аленка 15 грамм, шоколад Аленка 100 грамм, кондитерская плитка «Хорошая компания» с вафельной крошкой 80 грамм и шоколадная плитка «Хорошая компания» с арахисом 80 грамм.
· Второй кластер - такая группа товара со средним выбором ассортимента относится к магазинам в городах, с численностью населения более 250 тысяч человек. Пять самых продаваемых товаров в данном кластере: кондитерская плитка «Хорошая компания» с вафельной крошкой 80 грамм, шоколад Аленка 20 грамм, шоколад Аленка много молока 100 грамм, шоколадная плитка «Хорошая компания» с арахисом 80 грамм и шоколад молочный Аленка с разноцветным драже.
· Третий кластер - в данной группе представлен маленький выбор ассортимента. В основном это шоколадная продукция и вафельные торты. К такой категории товара можно отнести магазины в маленьких городах или поселках. Пять самых продаваемых товаров в данном кластере: шоколад Аленка 100 грамм, шоколад Аленка 15 грамм, шоколад Аленка 20 грамм, карамель «Москвичка» и шоколад Бабаевский горький 100 грамм
· Четвертый кластер - это кластеры с большим выбором ассортимента. Такая группа товаров относится к большим фирменным магазинам кондитерских изделий в крупных городах. Пять самых продаваемых товаров в данном кластере: шоколад Аленка 100 грамм, карамель «Москвичка», шоколад Бабаевский горький 100 грамм, вафли «Коровка» со вкусом топленого молока и конфеты «Ромашка».
· Пятый кластер - это кластеры с самым большим выбором ассортимента. Такая группа товаров относится к большим фирменным магазинам кондитерских изделий в городах-сателлитах. Пять самых продаваемых товаров в данном кластере: Конфеты Птичье молоко, карамель «Москвичка», шоколад Аленка 100 грамм, Бабаевский горький 100 грамм и вафли «Коровка» со вкусом топленого молока.
Можно сделать вывод, что самым популярным товаром является шоколад «Аленка».
Именно этот товар встречается в каждом кластере в лидерах.
Вывод к третьей главе
Проведенные методом кластерного анализа исследования помогли разделить торговые точки на страты по местоположению, затем каждая страта была разделена на кластеры. В итоге такой кластерный анализ помог снизить однородность на 1,77. Были проанализированы и выявлены взаимосвязи между социально-демографическими показателями (пол, возраст, доход) и потребительским поведением. Также была проведена кластеризация ассортимента торговых точек, что позволило выявить то, что в крупнейшем по количеству точек кластере представлен наименьший ассортимент.
Заключение
Большие данные - это не очередной ажиотаж на ИТ-рынке, это системный, качественный переход к составлению цепочек ценностей, основанных на знаниях. По эффекту его можно сравнить с появлением доступной компьютерной техники в конце прошлого века. В то время как недальновидные консерваторы будут применять глубоко устаревшие подходы, предприятия, уже сейчас использующие технологии Big Data, в будущем окажутся на лидирующих позициях и получат конкурентные преимущества на рынке. Нет никаких сомнений в том, что все крупные организации в ближайшие годы внедрят эту технологию, так как за ней как настоящее, так и будущее.
Данная дипломная работа представляет собой научный, систематизированный подход к выбору месторасположения торговых точек, причем способы получения и анализа информации, с получением конечного результата, являются весьма бюджетными, позволяющими провести такую процедуру даже индивидуальным предпринимателям с небольшим оборотом денежных средств.
Учитывая рост темпов накопления информации, появляется острая необходимость в технологиях анализа данных, которые, в этой связи, также стремительно развиваются. Развитие данных технологий в последние годы позволило перейти от сегментирования клиентов на группы с аналогичными предпочтениями к построению моделей в режиме реального времени, опираясь, в том числе, на его запросы в интернет и посещения тех или иных страниц. Становится реальным выводить конкретные предложения и рекламу на основе анализа интересов потребителя, делая эти предложения намного более целевыми. Также возможны корректировки и перенастройка модели в режиме реального времени.
Кластерный анализ поистине можно назвать удобнейшим и самым оптимальным инструментом выделения сегментов рынка. Использование данных методов стало особенно актуально в век высоких технологий, в который так актуально ускорить трудоемкие и длительные процессы при помощи технологий. Переменные, используемые в качестве основания для кластеризации, правильным будет выбирать, опираясь на опыт предыдущих исследований, теоретических предпосылок, различных проверенных гипотез, а еще исходя из пожеланий исследователя. Помимо этого, рекомендуется взять соответствующую меру сходства. Отличительной особенностью иерархической кластеризации является разработка иерархической структуры. Самым распространенным и эффективным дисперсионным методом является метод Барда. Неиерархические методы кластеризации часто называют методами k-средних. Выбор метода кластеризации и выбор меры расстояния взаимосвязаны. В иерархической кластеризации важным критерием принятия решения о числе кластеров являются расстояния, при которых происходит объединение кластеров. Размеры кластеров должны быть такими, чтобы был смысл сохранить данный кластер, а не объединить его с другими. Надежность и достоверность решений кластеризации оценивают разными способами.
Проведенные методом кластерного анализа исследования помогли разделить
торговые точки на страты по местоположению, затем каждая страта была разделена
на кластеры. В итоге такой кластерный анализ помог снизить однородность на
1,77. Были проанализированы и выявлены взаимосвязи между
социально-демографическими показателями (пол, возраст, доход) и потребительским
поведением. Также была проведена кластеризация ассортимента торговых точек, что
позволило выявить то, что в крупнейшем по количеству точек кластере представлен
наименьший ассортимент.
Список литературы
1. StatSoft - Электронные учебник по статистике
2. Мандель И.Д. Кластерный анализ., 1988 год
. Н.Паклин. «Кластеризация данных: масштабируемый алгоритм CLOPE».
. Олендерфер М. С., Блэшфилд Р. К. Кластерный анализ / Факторный, дискриминантный и кластерный анализ: пер. с англ.; Под. ред. И. С. Енюкова. - М.: Финансы и статистика, 1989-215 с.
. Дэниал Фасуло «Анализ последних работ по алгоритмам кластеризации».
. Н. Паклин «Алгоритмы кластеризации на службе Data Mining».
. Дюран Б., Оделл П. Кластерный анализ. М.: Статистика, 1977 год
. Жамбю М. Иерархический кластер-анализ и соответствия, 1988 год
. Хайдуков Д. С. Применение кластерного анализа в государственном управлении// Философия математики: актуальные проблемы. - М.: МАКС Пресс, 2009. - 287 с.
. Классификация и кластер. Под ред. Дж. Вэн Райзина. М.: Мир, 1980.
. Трион Р.C. Кластерный анализ- Лондон:, 1939. - 139 p.
. Бериков В. С., Лбов Г. С. Современные тенденции в кластерном анализе 2008. - 67 с.
. Вятченин Д. А. Нечёткие методы автоматической классификации. - Минск: Технопринт, 2004. - 320 с.
. И. А. Чубукова Data Mining. Учебное пособие. - М.: Интернет-Университет Информационных технологий;
. Н. Паклин. «Кластеризация категорийных данных: масштабируемый алгоритм CLOPE».
16. Sudipto Guha, Rajeev Rastogi, Kyuseok Shim « CURE: эффективный кластерный алгоритм для больших баз данных». Электронное издание.
17. Tian Zhang, Raghu Ramakrishnan, Miron Livny « BIRCH: эффективный метод кластеризации данных для очень больших баз данных ».
. Н. Паклин «Алгоритмы кластеризации на службе Data Mining».
. Ян Янсон «Моделирование ».
20. И. А. Чубукова Data Mining. Учебное пособие., 2006.
. «Доступная аналитика данных», Anil Maheshwari
. Кеннет Кекьер «Большие данные: революция, которая изменит нашу жизнь, работу и мысли»
. Кэти О'нейл и Рейчел Шутт “Наука о данных”