Материал: Сравнительный анализ методов кластерного анализа в решении задач группировки
Точность кластеризации будет выше если объекты внутри кластера максимально похожи, а кластеры максимально различаются.
· Классификация - это отнесение объектов (наблюдений, событий) к одному из заранее известных классов.
· Ассоциация - выявление закономерностей между связанными событиями. Примером такой закономерности служит правило, указывающее, что из события X следует событие Y. Такие правила называются ассоциативными.
Вывод к первой главе
Большие данные - это не очередной ажиотаж на ИТ-рынке, это системный, качественный переход к составлению цепочек ценностей, основанных на знаниях.
По эффекту его можно сравнить с появлением доступной компьютерной техники в конце прошлого века.
В то время как недальновидные консерваторы будут применять глубоко
устаревшие подходы, предприятия, уже сейчас использующие технологии Big Data, в
будущем окажутся на лидирующих позициях и получат конкурентные преимущества на
рынке. Нет никаких сомнений в том, что все крупные организации в ближайшие годы
внедрят эту технологию, так как за ней как настоящее, так и будущее.
Глава 2. Кластерный анализ для Big Data
Кластерный анализ представляет собой класс методов, которые используются для классификации объектов или событий в достаточной степени однородные группы, которые и будут называться кластерами.
Принципиальным будет то, что объекты в кластерах обязаны быть похожими между собой, но при этом обязательно отличаться от объектов, находящихся в других кластерах.
На рисунке 5 проиллюстрирована идеальная ситуация кластеризации, каждых
из кластеров четко отделены на основании различий двух переменных: ориентация
на качество (X), и чувствительность к цене (Y),
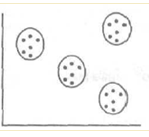
Рисунок 5 Идеальная ситуация кластеризации
Необходимо отметить, что абсолютно каждый потребитель попадает в какой-либо из кластеров, и перекрывающихся областей нет.
Однако, на иллюстрации снизу показана ситуация кластеризации, наиболее часто встречающаяся на практике.
В соответствии с данными рисунка 6 границы кластеров очерчены крайне
нечетко, и не совсем очевидно какие потребители в какой кластер отнесены, так
как солидную часть из них невозможно сгруппировать в тот или иной кластер.

Рисунок 6 Реальная ситуация кластеризации
В кластерном анализе группы, либо же кластеры выявляются при помощи собранных актуальных данных, а не заранее. Таким образом - нет абсолютно никакой необходимости в подготовке предварительной информации о кластерной принадлежности какого-либо из объектов.
• Сегментация рынка. К примеру, потребителей следует поделить на кластеры, основываясь на выгодах, ожидаемых ими от покупки данного товара. Кластер может содержать потребителей, ищущих схожие выгоды.. Такой метод и принято называть методом сегментаций преимуществ.
• Понимание поведения покупателей. Использование кластерного анализа в случае необходимости идентификации однородных категорий покупателей.
• Определение возможностей нового товара. Определение конкурентоспособных групп и наборов в рамках данного рынка также проводится посредством кластеризации торговых марок и товаров.
• Выбор тестовых рынков. Подборка подобных городов с целью проверки многочисленных маркетинговых стратегий выполняется посредством группировки городов в однородные кластеры.
• Сокращение размерности данных. Кластерный анализ также применяется в качестве основного инструмента уменьшения размерности данных при создании кластеров или подгрупп данных, в большей степени удобных для анализа, чем отдельные наблюдения. Далее проводимый многомерный анализ производится над кластерами, а не над отдельными наблюдениями.
2.1 Методы кластеризации
Существует два типа методов кластеризации: иерархические и неиерархические.
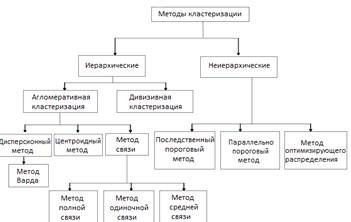
Рисунок 7 Методы кластерного анализа
.2 Иерархические методы
Иерархические методы делятся на два типа - агломеративные и дивизивные.
Агломеративная кластеризация берет начало с каждого объекта в отдельном кластере. Объекты группируются во все более крупные кластеры. Этот процесс будет идти до тех пор, пока все объекты не станут членами одного единственного кластера.
Также следует выделить дивизивную кластеризацию, которая берет начало со всех объектов, являющихся сгруппированными в единственном кластере. Кластеры будут делить пока каждый объект не окажется в отдельном кластере. Чаще всего для исследований берутся агломеративные методы, такие как методы связи, а также дисперсионные и центроидные.
Методы связи включают метод одиночной связи, метод полной связи и
метод средней связи. Методы связи - агломеративные методы иерархической
кластеризации, которые объединяют объекты в кластер, исходя из вычисленного
расстояния между ними.

Рисунок 8 Метод одиночной связи
![]()
![]()
В основе метода одиночной связи лежит минимальное расстояние, или правило ближайшего соседа (формула 1) .
При формировании кластера первыми объединяют два объекта, расстояние между которыми минимально. Далее определяют следующее по величине самое короткое расстояние, и в кластер с первыми двумя объектами вводят третий объект.
На каждой стадии расстояние между двумя кластерами представляет собой расстояние между их ближайшими точками. На любой стадии два кластера объединяют по единственному кратчайшему расстоянию между ними.
Этот процесс продолжают до тех пор, пока все объекты не будут объединены
в кластер. Если кластеры плохо определены, то метод одиночной связи работает
недостаточно хорошо.

Рисунок 9 Метод полной связи
![]()
В основе метода полной связи лежит максимальное расстояние между
объектами, или правило дальнего соседа. В методе полной связи расстояние между
двумя кластерами вычисляют как расстояние между двумя их самыми удаленными
точками.
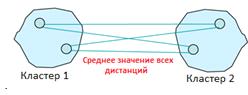
Рисунок 10 Метод средней связи
![]()
![]()
В методе средней связи расстояние между двумя кластерами определяется как среднее значение всех расстояний, измеренных между объектами двух кластеров, при этом в каждую пару входят объекты из разных кластеров. Метод средней связи использует информацию обо всех расстояния между парами, а не только минимальное или максимальное расстояние. По этой причине обычно предпочитают метод средней связи, а не методы одиночной или полной связи.
Дисперсионные методы формируют кластеры таким образом, чтобы минимизировать
внутрикластерную дисперсию.
Рисунок 11 Метод Варда
![]()
Широко известным дисперсионным методом, используемым для этой цели, является метод Варда, в котором кластеры формируют таким образом, чтобы минимизировать квадраты евклидовых расстояний до кластерных средних.
Для каждого кластера вычисляют средние всех переменных. Затем для каждого объекта вычисляют квадраты евклидовых расстояний до кластерных средних.
Эти квадраты расстояний суммируют для всех объектов. На каждой стадии
объединяют два кластера с наименьшим приростом в полной внутрикластерной
дисперсии.
Рисунок 12 Центроидный метод
![]()
В центроидных методах расстояние между двумя кластерами представляет собой расстояние между их центроидами (средними для всех переменных).
Центроидный метод - это дисперсионный метод иерархической кластеризации. Каждый раз объекты группируют и вычисляют новый центроид.
Метод Варда и средней связи показывают лучшие результаты из всех
иерархических методов.
2.3 Неиерархические методы
Иным типом процедур кластеризации являются неиерархические методы
кластеризации, зачастую называемые методом k-средних. Метод k-средних
(k-means clustering) - метод, определяющий центр кластера, а в следующую
очередь группирует все объекты в пределах заданного от центра порогового
значения. Эти методы включают последовательный пороговый метод, параллельный
пороговый метод и оптимизирующее распределение.
![]()
где k - число кластеров, ![]() _{i}} - полученные кластеры, i=1,2,…,k
_{i}} - полученные кластеры, i=1,2,…,k
![]() - центры масс векторов
- центры масс векторов ![]() .
.
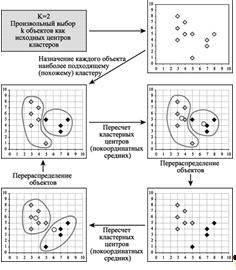
Рисунок 13 Пример работы алгоритма k-средних (k=2)
В последовательном пороговом методе группируются вместе объекты, которые находятся в пределах порогового значения с заданным центром.
Следующим этапом определяется новый кластерный центр, а данный процесс будет повторен для несгруппированных точек. После помещения объекта в кластер, имеющим новый центр, он уже не будет рассматриваться в качестве объекта для дальнейшей кластеризации.
По схожей схеме работает параллельный пороговый метод, но он имеет одно важное отличие - одновременно выбираются несколько кластерных центров и объекты, находящиеся в пределах порогового уровня группируются с ближайшим центром.
Метод оптимизирующего распределения будет иметь отличия от двух предыдущих пороговых методов в том, что объекты возможно впоследствии поставить в соответствие другим кластерам (перераспределить), в целях оптимизации суммарного критерия, которым является среднее внутри кластерное расстояние, установленное для данного числа кластеров.
Алгоритм BIRCH благодаря обобщенным представлениям кластеров, скорость кластеризации увеличивается, алгоритм при этом обладает большим масштабированием. В этом алгоритме реализован двухэтапный процесс кластеризации.
Первый этап заключается в формировании предварительного набора кластеров. Следующий этап заключается в применении к выявленным кластерам других алгоритмов кластеризации, которые были бы пригодны в работе с оперативной памятью.
Представим себе каждый элемент данных в качестве бусины, которая лежит на поверхности стола, то данные кластеры абсолютно реально "заменить" теннисными шариками и в дальнейшем перейти к изучению кластеров теннисных шариков более детально.
Количество бусин может быть достаточно большим, но диаметр теннисных шариков реально так подобрать, чтобы на втором этапе, применяя традиционные алгоритмы кластеризации, стало возможным определить действительную сложную форму кластеров.
Среди новых масштабируемых алгоритмов также можно отметить алгоритм CURE - алгоритм иерархической кластеризации, где понятие кластера формулируется с использованием концепции плотности. Над масштабируемыми методами сейчас активно работают многие исследователи, основная задача которых - преодолеть недостатки алгоритмов, существующих на сегодняшний день.
2.4 Сравнение видов кластеризации
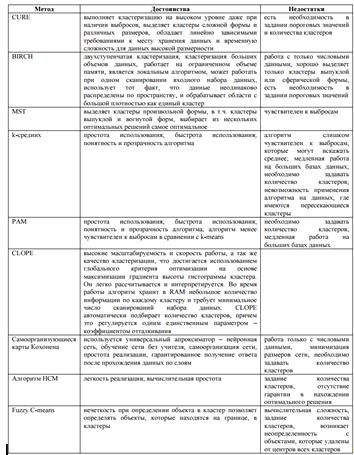
В таблице перечислены достоинства и недостатки таких методов, как:
Алгоритм CURE, BIRCH, MST, k-средних (k-means), PAM, CLOPE, Самоорганизующиеся карты Кохонена, HCM (Hard C - Means),
Fuzzy C-means.
2.5 Статистики, связанные с кластерным анализом
Следующие статистики и понятия связаны с кластерным анализом:
1. Кластерный центроид. Среднее значение переменных для всех случаев или объектов в конкретном кластере.
2. Кластерные центры. Исходные начальные точки в неиерархической кластеризации. Кластеры строят вокруг этих центров, или зерен кластеризации.
3. Принадлежность кластеру. Указывает кластер, которому принадлежит каждый случай или объект.
4. Древовидная диаграмма - графическое средство для показа результатов кластеризации. Вертикальные линии представляют объединяемые кластеры. Положение вертикальной линии на шкале расстояния показывает расстояния, при которых объединяли кластеры. Такую диаграмму читают слева направо.
5. Показатель вариации. Проверка качества кластеризации. Отношение
стандартного отклонения к среднему значению.
7. Сосульчатая диаграмма. Это графическое отображение результатов кластеризации.
8. Матрица сходства/матрица расстояний между объединяемыми объектами - это нижняя треугольная матрица, содержащая значения расстояния между парами объектов или случаев
Вывод ко второй главе
Кластерный анализ поистине можно назвать удобнейшим и самым оптимальным инструментом выделения сегментов рынка. Использование данных методов стало особенно актуально в век высоких технологий, в который так актуально ускорить трудоемкие и длительные процессы при помощи технологий. Переменные, используемые в качестве основания для кластеризации, правильным будет выбирать, опираясь на опыт предыдущих исследований, теоретических предпосылок, различных проверенных гипотез, а еще исходя из пожеланий исследователя. Помимо этого, рекомендуется взять соответствующую меру сходства. Отличительной особенностью иерархической кластеризации является разработка иерархической структуры. Существуют и используются два типа иерархических методов кластеризации - агломеративные и дивизивные.
Агломеративные методы включают в себя: метод одиночной, полной и средней
связи. Самым распространенным дисперсионным методом является метод Барда.
Неиерархические методы кластеризации часто называют методами k-means. Выбор метода кластеризации и выбор
меры расстояния взаимосвязаны. В иерархической кластеризации важным критерием
принятия решения о числе кластеров являются расстояния, при которых происходит
объединение кластеров. Относительные размеры кластеров должны быть такими,
чтобы имело смысл сохранить данный кластер, а не объединить его с другими.
Кластеры интерпретируют с точки зрения кластерных центроидов. Часто
интерпретировать кластеры помогает их профилирование через переменные, которые
не лежали в основе кластеризации. Надежность и достоверность решений
кластеризации оценивают разными способами.