Материал: Сравнительный анализ методов кластерного анализа в решении задач группировки
Сравнительный анализ методов кластерного анализа в решении задач группировки
Оглавление
Введение
Глава 1. Теоретические основы анализа Big Data
1.1 О Big Data
.2 Map-Reduce
.3 Data Mining для работы с Big Data
1.4 Задачи, решаемые методами Data Mining
Вывод к первой главе
Глава 2. Кластерный анализ для Big Data
.1 Выбор метода кластеризации
.2 Иерархические методы
.3 Неиерархические методы
.4 Сравнение видов кластеризации
.5 Статистики, связанные с кластерным анализом
Вывод ко второй главе
Глава 3. Алгоритм разбиения торговых точек
.1 Профиль клиента
.2 Анализ соответствий
.3 Основная идея кластерного анализа
.4 Признаки для кластеризации
.5 Выявление однородных по местоположению точек
.5.1 Итоговое деление на страты
.6 Кластеризация объектов на однородные группы
.7 Кластеризация ассортимента торговых точек
Вывод к третьей главе
Заключение
Список литературы
Введение
Человечество в свое м развитии использует материальные, энергетические, инструментальные и информационные ресурсы. Информация о событиях прошлого, настоящего и возможного будущего представляет огромный интерес для анализа происходящего. Как говорили древние: Praemonitus praemunitus - «предупреждён - значит вооружён».
Современное развитие общества характеризуется небывалым ростом информационных потоков - в промышленности, торговле, финансовых ранках. Способность общества хранить и быстро обрабатывать информацию определяет в целом уровень развития государственности той или иной страны.
Проблема сбора, хранения и обработки информации в современном обществе уделяется огромное внимание. Однако, в настоящий момент существует явное противоречие. С одной стороны, человеческая цивилизация переживает информационный взрыв, объем информации с каждым годом увеличивается в разы. С другой стороны, рост текущего объема информации в обществе превышает индивидуальные возможности личности по ее усвоению. Наличие такой проблематики инициирует массовое развитие технологий, технических средств, коммутационных потоков.
Исключительно важная роль информации в современном мире, привела к выявлению информации как собственного ресурса, столь же важного и необходимого, как энергетические, финансовые, сырьевые ресурсы.
Потребности общества в сборе, хранении и обработке информации как товара создали новый спектр услуг - рынок информационных технологий.
Для наиболее полного и цельного использования информационных технологий, информацию нужно собирать, обрабатывать, создавать места хранения, накопления, создавать системы передачи и системы ограничения доступа, наконец, информацию нужно систематизировать. Последняя проблема наиболее актуальна в последнее время, поскольку большой, даже огромный, объем информации, поступающий в глобальные массивы хранения, без ее систематизации может привести к информационному коллапсу, когда доступ или поиск нужной информации может привести к поиску иголки в стоге сена.
Цель данной работы: Сравнительный анализ методов кластерного анализа в решении задач группировки.
Задача: Проанализировать подходы к использованию кластерного анализа в задачах типизации большого множества данных.
В ходе работы будут использованы различные методы кластерного анализа, с
целью выявления преимуществ и недостатков каждого из них, а также выбора
наиболее оптимального под выполнение поставленных задач. Также будет поднят
главный вопрос кластерного анализа - вопрос о количестве кластеров, и будут даны
рекомендации по его решению. Актуальность данной работы обусловлена острой
необходимостью определения оптимальных методов обработки больших объемов данных
и решения задач систематизации данных в кратчайшие сроки. Широкое практическое
применение полученных посредством кластерного анализа данных и обуславливает
актуальность данного исследования. Определенным аспектам такой проблематики в
современном развитии информационных технологий и посвящена моя дипломная
работа.
Глава 1. Теоретические основы анализа Big Data
.1 О Big Data
Термин «Big Data» характеризует совокупности данных c возможным экспоненциальным ростом, которые слишком велики, слишком неформатированы или совсем неструктурированы для анализа традиционными методами.
Технологии Big Data - серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объемов и значительного многообразия. Данные технологии применяются для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения информации по многочисленным узлам вычислительной сети. Они сформировались в конце 2000-х годов в качестве альтернативы традиционным системам управления базами данных и решениям класса Business Intelligence. В настоящее время большинство крупнейших поставщиков информационных технологий для организаций в своих деловых стратегиях используют понятие «большие данные», а основные аналитики рынка информационных технологий посвящают концепции выделенные исследования.
В настоящее время значительное количество компаний внимательно следят за развитием технологий. Согласно отчетам компании McKinsey «Global Institute, Big data: The next frontier for innovation, competition, and productivity» (Глобальный Институт, большие данные: следующий рубеж для инноваций, конкуренции и производительности), данные стали важным фактором производства наряду с трудовыми и капитальными ресурсами. Использование Big Data становится основой конкурентного преимущества и роста компаний.
В условиях современности организации и компании создают огромное количество неструктурированных данных: текст, различные документы изображения, видео, машинные коды, таблицы и тому подобное. Все эта информация размещается и хранится в множестве репозиториев, зачастую за пределами организации.
Организации могут обладать доступом к огромному массиву собственных данных, но при этом необходимых инструментов, с которыми реально было бы установить взаимосвязи между всеми этими данными и основываясь на них сделать значимые выводы, могут и не иметь. Учитывая быстрый и непрерывный рост данных, становится остро необходимым переход от традиционных методов анализа к более прогрессивным технологиям класса Big Data.
Характеристики. В современных источниках понятие Big Data определяется как данные объема в порядках терабайт. Признаки Big Data можно определить как «три V»: volume - объем; variety - разнородность, множество; velocity - скорость (необходимость очень быстрой обработки).
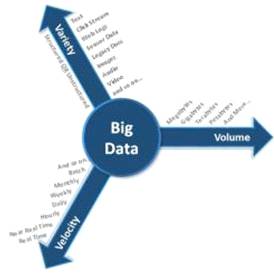
Рисунок 1 Признаки больших данных
· Объем. Стремительное развитие технологий и популяризация социальных сетей способствуют очень быстрому росту объемов данных. Эти данные, генерируемые как людьми, так и машинами распространяются в различных местах и форматах в огромных объемах.
· Скорость. Данный признак - это скорость генерации данных. Получение необходимых данных в кратчайшие сроки является важным конкурентным преимуществом для разработчиков решений, в том числе и потому что разные приложения имеют различные требования к задержкам.
· Разнообразие. Разнообразие можно отнести к различным форматам хранения данных. На сегодняшний день в мире генерируются значительные объемы неструктурированных данных, и это помимо структурированных данных, которые получают на предприятиях. До начала эры развития технологии Big Data совсем не было мощных и надежных инструментов в отрасли, которым было бы по силам работать с объемными неструктурированными данными, с которыми приходится видеть сегодня.
Потребление огромного количества структурированных данных, генерируемых как внутри, так и вне пределов предприятия является необходимостью для организаций в современном мире для того, дабы оставаться конкурентоспособными.
К «категории» Big data традиционно относят не только привычные электронные таблицы, но и неструктурированные данные, которые могут храниться в виде изображений, аудиофайлов, видеофайлов, веб-журналов, данных датчиков и многие другие. Разновидностью в мире больших данных и будет называться этот аспект различных форматов данных.
Ниже в рисунке 2 находится сравнительная характеристика традиционной базы и базы Big Data.
Существуют некоторое количество отраслей, данные в которых собираются и накапливаются весьма интенсивно. Для приложений такого класса, в которых есть необходимость хранения данных годами, накопленные данные классифицируются как Extremely Big Data.
Отмечается также рост числа приложений Big Data в коммерческих и
государственных секторах, объем данных такого рода приложений находится в
хранилищах и зачастую составляет сотни петабайт.
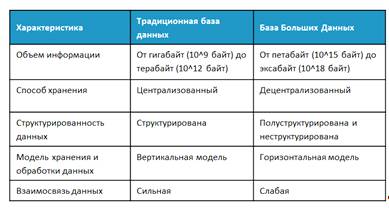
Рисунок 2 Сравнительные характеристики данных
Развитие определенных технологий делает возможным «отслеживание» людей, их привычек, интересов и потребительского поведения различными методами. В качестве примера можно привести использование интернета в целом и в частности - покупки в Интернет-магазинах, таких как Walmart (по данным Википедии, хранилище данных Walmart оценивается более чем в 2 петабайт), или путешествуем и перемещаемся с мобильными телефонами, совершаем звонки, пишем письма, делаем фотографии, заходим в аккаунты в социальных сетях из различных точек планеты - все это накапливается в базах данных и может быть полезно использовано благодаря быстрой обработке больших данных.
Аналогичным образом, современные медицинские технологии генерируют большие объемы данных, относящиеся к оказанию медицинской помощи (изображения, видео, мониторинг в реальном времени).
Источники больших данных. Подобно тому, как изменились форматы хранения данных, источники данных также эволюционировали и постоянно расширяются. Необходимо хранить данные в широком разнообразии форматов.
С развитием и продвижением технологии объем данных, которые генерируются, постоянно растет. Источники больших данных можно разделить на шесть различных категорий, как показано ниже.
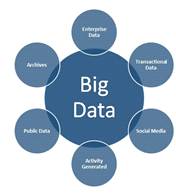
Рисунок 3 Источники больших данных
· Данные предприятия. На предприятиях в разных форматах имеются большие объемы данных. Общие форматы включают плоские файлы, электронные письма, документы Word, электронные таблицы, презентации, HTML-страницы, документы PDF, XML-файлы, устаревшие форматы и т. д. Эти данные, распространяемые по всей организации в разных форматах, называются корпоративными данными .
· Транзакционные данные. Каждое предприятие имеет свои приложения, которые включают в себя выполнение различных видов транзакций, таких как веб-приложения, мобильные приложения, CRM-системы и многие другие.
Для поддержки транзакций в этих приложениях в качестве базовой инфраструктуры обычно используется одна или несколько реляционных баз данных. В основном это структурированные данные и называются транзакционными данными.
· Социальные медиа. В социальных сетях, таких как Twitter, Facebook и многие другие, генерируются большое количество данных. Обычно в социальных сетях используются неструктурированные форматы данных, в том числе текст, изображения, аудио, видео. Эта категория источников данных называется социальной СМИ .
· Activity Generate. Сюда входят данные из медицинских устройств, цензурные данные, видео наблюдения, спутники, башни сотовых телефонов, промышленное оборудование и другие данные, генерируемые в основном машинами. Эти типы данных называются данными Activity Generate.
· Публичные данные. Эти данные включают в себя данные, которые общедоступны, как данные, публикуемые правительствами, данные исследований, публикуемые научно-исследовательскими институтами, данные метеорологических и метеорологических отделов, данные переписи, Википедия, образцы данных с открытым исходным кодом и другие данные, которые свободно доступны для общественности. Этот тип общедоступных данных называется Public Data .
· Архив. Организации архивируют много данных, которые либо больше не требуются, либо очень редко требуются. В сегодняшнем мире, когда оборудование дешевеет, ни одна организация не хочет удалять какие-либо данные, они хотят хранить как можно больше данных. Этот тип, к которым менее часто обращаются, называется архивными данными.
Примеры реализации. В качестве примера реализации данной технологии чаще всего приводится проект Hadoop, который разработан для осуществления распределенных вычислений, используемых для обработки внушительных объемов данных.
Этот проект разрабатывается в рамках Apache Software Foundation. Компания Cloudera поддерживает данный проект в коммерческом плане.
В качестве участников в проект привлечены разработчики из различных стран мира. информация кластеризация провайдер
Технологически Apache Hadoop можно назвать свободным Java-фреймворком, который поддерживает выполнение распределенных приложений, работающих на больших кластерах, построенных на стандартном оборудовании.
Так как обработка данных выполняется на кластере серверов, в случае выхода из строя одного из них, работа будет перераспределена между другими работающими.
Также необходомо сказать о реализации в Hadoop технологии MapReduce, основной задачей которой является автоматическое распараллеливание данных и их обработку на кластерах.
Ядром Hadoop является отказоустойчивая распределенная файловая система HDFS (Hadoop Distributed File System), оперирующая системами хранения.
Суть системы в разбитии входящих данных на блоки, для которых есть специально отведенная позиция в пуле серверов для каждого из них. Система делает возможным для приложений масштабироваться. Уровнем будут тысячи узлов и петабайты данных.
1.2 Map-Reduce
В данном пункте речь пойдет об алгоритме Map-Reduce, который является моделью для распределенных вычислений.
В основе принципов его работы лежит распределение входных данных на рабочие узлы распределенной файловой системы для предварительной обработки (map-шаг) и, затем следует свертка (объединение) заранее обработанных данных (reduce-шаг).
Алгоритм вычисляет промежуточные суммы каждого узла распределенной файловой системы, затем вычисляет сумму промежуточных значений и получает итоговую сумму.
Магический квадрант провайдеров решений в области систем управления
хранилищами данных ( Gartner, февраль 2017)
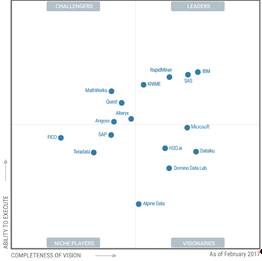
Рисунок 4 Лидеры
Компании:
· Лидеры: IBM, SAS, RapidMiner, KNIME
· Претенденты: MathWorks, Quest (ранее Dell), Alteryx, Angoss
· Вижуанарии: Microsoft, H2O.ai, Dataiku, Domino Data Lab, Alpine Data
· Нишевые игроки: FICO, SAP, Teradata
1.3 Data Mining для работы с Big Data
Data Mining (DM) - “Это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей”.
Особенностью Data Mining можно назвать сочетание широкого математического инструментария (от классического статистического анализа до новых кибернетических методов) и последних достижений в сфере информационных технологий.
Данная технология объединяет строго формализованные методы и методы неформального анализа, т.е. количественный и качественный анализ данных.
.4 Задачи, решаемые методами Data Mining
· Корреляция - установление статистической зависимости непрерывных выходных от входных переменных.
· Кластеризация - это группировка объектов (наблюдений, событий) на основе данных (свойств), описывающих сущность этих объектов. Объекты внутри кластера обязаны быть "похожими" друг на друга и при этом иметь отличия от объектов, попавших в другие кластеры.