Материал: Розробка алгоритму ідентифікації різних видів складних об’єктів моніторингу при веденні інформаційної роботи
Алгоритм гірської кластеризації
можна використовуватись для синтезу нечіткої бази знань. Нехай ми маємо ![]() -
центри кластерів, знайдені в результаті гірської кластеризації, кожному з яких
зіставлене значення цільової ознаки
-
центри кластерів, знайдені в результаті гірської кластеризації, кожному з яких
зіставлене значення цільової ознаки ![]() .
Тоді кожному центру кластера
.
Тоді кожному центру кластера ![]() ставиться у
відповідність правило: якщо
ставиться у
відповідність правило: якщо ![]() , то
, то ![]() ,
де нечіткі терми
,
де нечіткі терми ![]() та
та ![]() характеризуються
гаусівськими функціями приналежності:
характеризуються
гаусівськими функціями приналежності:
![]() . (2.16)
. (2.16)
Алгоритм поступово зростаючого розбиття IDA
Алгоритм поступово зростаючого розбиття IDA (incremental decomposition algorithm) полягає в наступному. На першій ітерації є одне продукційне правило, що має як область свого впливу (область, у якій значення результуючої функції приналежності передумови нечіткого правила перевищує задану величину) усю множину припустимих вхідних значень (рис. 2.2).
На другій ітерації дане правило
розбивається на два двома способами (показані стрілками). Проводиться навчання
і вибирається, який зі способів розбиття дає найменшу погрішність (даний
перехід відзначений чорною стрілкою). Серед наявних правил вибирається те, для
якого складова похибки в загальній похибці є найбільшою (область його впливу
заштриховано). Воно і підлягає розбиттю на два правила двома способами
(ітерація 3). Описаний процес продовжується до досягнення необхідної точності
або поки не буде згенеровано задане число продукційних правил.
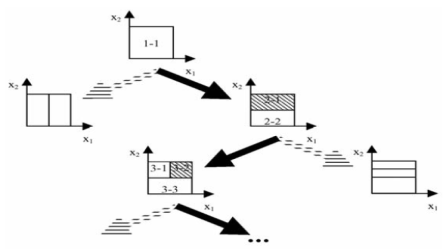
Рисунок 2.2 − Схема роботи
методу IDA
Інформація про ДРВп, що надходить
від пеленгаторних постів записується до бази даних. Після чого, сукупність
даних, що досліджується представляє собою кінцеву множину ДРВп ![]() ,
кожен елемент якої характеризується множиною кількісних та якісних
характеристик
,
кожен елемент якої характеризується множиною кількісних та якісних
характеристик ![]() , наприклад: координати
розташування ДРВп, вид зв’язку (КХ, УКХ), інтенсивність роботи (частота виходу
в ефір впродовж 12 годин), які у свою чергу після проведення аналізу і
кластеризації дадуть змогу оператору відобразити реальну РЕО, на якій чітко
буде відображатись кількість підрозділів (бойових батарей в даному випадку) N,
відстань між ними
, наприклад: координати
розташування ДРВп, вид зв’язку (КХ, УКХ), інтенсивність роботи (частота виходу
в ефір впродовж 12 годин), які у свою чергу після проведення аналізу і
кластеризації дадуть змогу оператору відобразити реальну РЕО, на якій чітко
буде відображатись кількість підрозділів (бойових батарей в даному випадку) N,
відстань між ними ![]() , віддаленість від
переднього краю
, віддаленість від
переднього краю ![]() , дальність зв’язку
, дальність зв’язку
![]() .
Для ідентифікації складних ОМ необхідно вибрати оптимальний алгоритм
кластеризації. В даній роботі пропонується вибрати алгоритм C-means та усунути
його основний недолік - необхідність попереднього задання кількості кластерів.
Для усунення даного недоліку мною запропоновано частково поєднати алгоритм C -
means та алгоритм гірської кластеризації, адже перевагою останнього є те, що
він не вимагає задавання кількості кластерів, а сам їх шукає і встановлює для
них центри, які можуть бути КП (командним пунктом) в бойовому порядку
підрозділу. Ця умова є необхідною для вирішення задачі кваліфікаційної роботи,
тому для ідентифікації складних об’єктів моніторингу буде використано саме це
поєднання методів. Для застосування цього алгоритму необхідно розрахувати
математичну модель та визначити характеристики ДРВп, які підлягають обробці.
.
Для ідентифікації складних ОМ необхідно вибрати оптимальний алгоритм
кластеризації. В даній роботі пропонується вибрати алгоритм C-means та усунути
його основний недолік - необхідність попереднього задання кількості кластерів.
Для усунення даного недоліку мною запропоновано частково поєднати алгоритм C -
means та алгоритм гірської кластеризації, адже перевагою останнього є те, що
він не вимагає задавання кількості кластерів, а сам їх шукає і встановлює для
них центри, які можуть бути КП (командним пунктом) в бойовому порядку
підрозділу. Ця умова є необхідною для вирішення задачі кваліфікаційної роботи,
тому для ідентифікації складних об’єктів моніторингу буде використано саме це
поєднання методів. Для застосування цього алгоритму необхідно розрахувати
математичну модель та визначити характеристики ДРВп, які підлягають обробці.
2.3 Синтез
математичної моделі кластеризації об’єктів за результатами роботи засобів
радіомоніторингу
Для заданої множини ДРВп K, що
характеризується вхідними векторами ![]() і
N визначених кластерів
і
N визначених кластерів ![]() передбачається, що
будь-яка
передбачається, що
будь-яка ![]() належить
будь-якому
належить
будь-якому ![]() з приналежністю
з приналежністю ![]() в
інтервалі [0,1], де j - номер кластера, а k − номер вхідного вектора.
в
інтервалі [0,1], де j - номер кластера, а k − номер вхідного вектора.
Для забезпечення однозначності в
розрахунках при розробці математичної моделі приймаються до уваги наступні
умови нормування для ![]() :
:
![]() ;
(2.17)
;
(2.17)
![]() .
(2.18)
.
(2.18)
Для забезпечення найбільшої ймовірності
приналежності ДРВп до кластеру необхідно мінімізувати суми всіх зважених
відстаней ![]() :
:
![]() ,
(2.19)
,
(2.19)
де q − фіксований параметр, заданий перед ітераціями.
Для досягнення вищезазначеної мети
необхідно вирішити наступну систему рівнянь:
![]() (2.20)
(2.20)
![]()
де N − кількість кластерів;− кількість ДРВп;
![]() −
ймовірність входження
−
ймовірність входження ![]() до кластеру
до кластеру ![]() .
.
Сумісно з умовами нормування ![]() дана
система диференціальних рівнянь має наступний розв’язок:
дана
система диференціальних рівнянь має наступний розв’язок:
![]() ,
(2.21)
,
(2.21)
де ![]() − зважений центр мас.
− зважений центр мас.
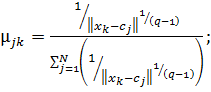 (2.22)
(2.22)
Таким чином представлено математичну
модель, яка забезпечує процес кластеризації ОМ з заданою приналежністю в умовах
невизначеності, за визначеними ознаками з використанням алгоритму C-means, на
основі якої створено алгоритм ідентифікації складних ОМ.
2.4
Алгоритм ідентифікації складних об’єктів моніторингу на основі нечітких
алгоритмів кластерного аналізу
На даний час розроблена велика кількість програмних пакетів, які забезпечують вирішення задач в різних галузях науки. Найбільш всеохоплюючим різноманітних галузей науки є програмний пакет Matlab.
Для вирішення поставлених задач ідентифікації ОМ доцільно використовувати функції кластеризації програмного пакету Matlab.
В даному програмному пакеті необхідно розробити алгоритм, щоб забезпечити виконання наступних вимог до кластеризації складних ОМ:
автоматичного визначення кількості кластерів, що розглядаються з заданої множини ДРВ;
автоматичного визначення приналежності кожного ДРВ до кожного з кластерів;
зручне для оператора представлення даних для подальшої їх обробки та аналізу;
визначення кількості засобів зв’язку і типу зв’язку, який вони реалізовують;
визначення інтенсивності роботи засобу зв’язку, яка є передумовою для надання її статусу основного ДРВп в підрозділі.
На основі розробленої математичної моделі розроблений алгоритм, що реалізує вимоги для виконання поставленого завдання в програмному середовищі MatLab. В додатку А представлена блок - схема алгоритму кластеризації, що забезпечує вирішення поставлених задач.
Алгоритм побудований на основі функціональних блоків. Робота функціонального блоку розрахована по певних функціях, які мають вхідні аргументи. Аргументом функції може виступати як сукупність ДРВп з їхніми параметрами, що підлягають кластеризації, так і окремі характеристики, що визначають роботу даного алгоритму.
В даному алгоритмі показано процес кластеризації ОМ з використанням двох функцій кластеризації subclust та fcm, які входять до програмного пакету Matlab.
Після того, як головна функція отримала вхідні дані про ОМ, (додаток А, блок 1), вона викликає функцію subclust, або метод субтрактивної нечіткої кластеризації (додаток А, блок 3), який забезпечує визначення кількості кластерів.
Ідея методу субтрактивної кластеризації полягає в тому, що кожна точка даних передбачається як центр потенційного кластера, після чого обчислюється деяка міра здатності кожної точки даних представляти центр кластера. Ця кількісна міра заснована на оцінці щільності точок даних довкола відповідного центру кластера.
Даний алгоритм заснований на виконанні наступних дій:
а) вибір точки даних з максимальним потенціалом для представлення центру першого кластера.
б) видалення всіх точки даних в околиці центру першого кластера, величина якої задається параметром radii, щоб визначити наступний нечіткий кластер і координати його центру. Тобто цей параметр дозволяє вибрати максимальний радіус кластера, в даному випадку на вибір тактичного нормативу бойового порядку.
Ці дві процедури повторюються до тих пір, поки всі точки даних не виявляться всередині околиць радіусу radii шуканих центрів кластерів.
Функція командного рядка subclust
знаходить центри кластерів методом субтрактивної кластеризації. Вона
використовується в наступному форматі:
[C, S] = subclust (X, radii,
xBounds, options)
Розглянемо вхідні аргументи:
Матриця X містить дані кластеризації щодо ДРВп, а також їх характеристики. Перші дві колонки матриці X відповідають координатам окремих точок даних, решта колонок це якісні показники ДРВп..
Параметр radii є вектором, компоненти якого набувають значень з інтервалу [0, 1] і задають діапазон розрахунку центрів кластерів по кожній з ознак вимірів, тобто ним задаються дані щодо радіусу ОМ. При цьому робиться припущення, що всі дані містяться в деякому одиничному гіперкубі. Можливо задавати радіус для кожної характеристики ДРВп окремо. У загальному випадку малі значення параметра radii призводять до пошуку великої кількості малих бойових формувань (взвод, рота).
Аргумент xBounds є матрицею розмірності (2*q), яка визначає спосіб відображення матриці даних X в деякому одиничному гіперкубі. Тут q - кількість ознак, що розглядаються в множині даних. Цей аргумент є необов’язковим, якщо матриця X вже нормалізована. Перший рядок матриці xBounds містить мінімальні значення інтервалу виміру кожної з ознак, а другий рядок - максимальні значення виміру кожної з ознак. Приклад задання аргументу “xBounds=[-10_-5; 10_5]”. При проведенні кластеризації перша характеристика знаходитиметься в межах [-10 +10], а друга [-5 +5].
Для зміни заданих за умовчанням параметрів алгоритму кластеризації може бути використаний додатковий вектор options. Компоненти цього вектора можуть набувати наступних значень:
options (1) = quashFactor - параметр, використовуваний як коефіцієнт для множення значень radii, які визначають околицю центру кластера. Це здійснюється з метою зменшення впливу потенціалу граничних точок, що розглядаються як частина нечіткого кластера;
options (2) = acceptRatio - параметр, що встановлює потенціал як частину потенціалу центру першого кластера, вище за який інша точка даних може розглядатися як центр іншого кластера;
options (3) = rejectRatio - параметр, що встановлює потенціал як частину потенціалу центру першого кластера, нижче за який інша точка даних не може розглядатися як центр іншого кластера;
options(4) = verbose - якщо значення цього параметра не дорівнює нулю, то на екран монітора виводиться інформація про виконання процесу кластеризації.
Вихідними значеннями функції будуть змінні [C, S]:
а) Функція subclust повертає матрицю С значень координат центрів нечітких кластерів. При цьому кожен рядок цієї матриці містить координати одного центру кластера.
б) Ця функція також повертає вектор S, компоненти якого представляють значення s, які визначають діапазон впливу центру кластера по кожній з ознак, що розглядаються. При цьому всі центри кластерів володіють однаковою множиною значень s, які призначені для визначення правильності розбиття кластерів.
Отримані значення центрів кластерів з параметру “C” передаються у функцію fcm. Синтаксис функції fcm має наступний вигляд:
[center, U, obj_fcn] = fcm(data, cluster_n, options)
Вхіднимн аргументами цієї функції є:
data: матриця початкових даних ДРВп X кластеризації, s-рядок якої представляє інформацію про один об’єкт нечіткої кластеризації у формі вектора xs = (xs1, xs2, ..., xsN), xsj - кількісне значення ознаки для об’єкта даних ДРВп, s=1, 2,..., S - кількість екземплярів кластеризації, N - кількість параметрів (ознак), що описують один екземпляр (або кластер);
cluster_n: кількість шуканих нечітких кластерів (більше одиниці).
Вихідними аргументами цієї функції [center, U, obj_fcn] є :
center: матриця центрів шуканих нечітких кластерів ДРВп, кожен рядок якої представляє собою координати центру одного з нечітких кластерів у формі вектора;
U: матриця значень функцій приналежності шуканого нечіткого розбиття, або матриця ймовірностей;
obj_fcn: значення цільової функції на кожній з ітерацій роботи алгоритму FCM.
Функція fcm (data, cluster_n, options) може бути викликана з додатковими аргументами options, які призначені для управління процесом нечіткої кластеризації, а також для зміни критерію зупинки роботи алгоритму і відображення інформації на екрані монітора.
Ці додаткові аргументи мають наступні значення:
options (1) : експоненціальна вага m для розрахунку матриці нечіткого розбиття U (за умовчанням це значення дорівнює т=2);
options (2): максимальне число ітерацій k (за умовчанням це значення дорівнює k=100);
options (3): мінімально допустиме значення покращення цільової функції за одну ітерацію алгоритму (за замовчанням це значення дорівнює e=0.00001);
options (4): інформація про поточну ітерацію, що відображується на екрані монітора (за умовчанням це значення дорівнює 1).
Якщо будь-яке із значень додаткових аргументів дорівнює NAN (не число), то для цього аргументу використовується значення за умовчанням. Функція fcm закінчує свою роботу, коли алгоритм FCM виконає максимальну кількість ітерацій , або коли різниця між значеннями цільових функцій на двох послідовних ітераціях буде менше заданого апріорі значення параметра збіжності алгоритму e.
Функція fcm реалізована у вигляді m-файла і використовує, у свою чергу, три інші функції:
функцію initfcm для формування матриці вихідного розбиття деяким випадковим чином;
функцію distfcm розрахунку матриці відстаней між точками даних і центрами кластерів;
функцію stepfcm для розрахунку значень цільової функції і функцій приналежності об’єктів нечітким кластерам на кожній ітерації роботи алгоритму FCM. Всі ці функції також реалізовані у вигляді m-файлів.
Представлений алгоритм ідентифікації забезпечує проведення кластеризації ОМ. Також існує можливість задання параметрів кластеризації. Проте використання лише одного алгоритму для ідентифікації ОМ не може в достатній мірі забезпечувати розв’язання всього спектра задач ідентифікації ОМ. Таким чином, для успішного проведення ідентифікації необхідно використовувати різні алгоритми аналізу даних.
Висновок до другого розділу
В даному розділі було розглянуто всі
існуючі методи кластеризації, серед яких було обрано найбільш доцільний
алгоритм для виконання задачі ідентифікації ОМ. Таким алгоритмом є поєднання
алгоритму С-means. та алгоритму гірської кластеризації Для застосування цього
алгоритму було розраховано математичну модель, де запропоновано використання
формули Евклідової відстані, що найбільш підходить для розрахунку по
координатах.
. АПРОБАЦІЯ АЛГОРИТМУ
ІДЕНТИФІКАЦІЇРІЗНИХ ТИПІВ СКЛАДНИХ ОБ’ЄКТІВ НА ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ
КЛАСТЕРНОГО АНАЛІЗУ