Материал: Розробка алгоритму ідентифікації різних видів складних об’єктів моніторингу при веденні інформаційної роботи
2.1 Основні
ознаки, що дозволяють здійснювати ідентифікацію складних об’єктів моніторингу
на основі нечітких алгоритмів кластерного аналізу
Відомі [2] деякі етапи кластеризації. Початковим етапом кластеризації є необхідність складання вектора характеристик для кожного об’єкта - як правило, це набір ознак з невеликими числовими значеннями. Однак існують також алгоритми, що працюють з якісними (категорійними) характеристиками. Вихідними даними для здійснення кластеризації ОМ буде вектор характеристик географічних координат просторових даних розміщення ДРВ; частотний діапазон та інтенсивність їх роботи. Визначивши вектор характеристик, можна провести його нормалізацію, щоб всі компоненти давали однаковий внесок при розрахунку «відстані». У процесі нормалізації всі значення приводяться до деякого діапазону, наприклад, [-1, -1] або [0, 1]. Для кожної пари об’єктів вимірюється «відстань» між ними - ступінь схожості. Існує безліч метрик, ось лише основні з них:
відстань Евкліда. Найбільш поширена
функція відстані. Є геометричною відстанню у багатовимірному просторі. Такий
метод шукає кластери як сфери однакового розміру.
![]() ,
(2.1)
,
(2.1)
де ![]() − центр i-го кластера;
− центр i-го кластера;
![]() −
і-ий об’єкт кластеризації;
−
і-ий об’єкт кластеризації;
![]() −
відстань між об’єктами з вихідної матриці даних і центрами кластерів;−
кількість елементів у вибірці.
−
відстань між об’єктами з вихідної матриці даних і центрами кластерів;−
кількість елементів у вибірці.
квадрат евклідової відстані.
Застосовується для надання більшої ваги віддаленішим один від одного об’єктам.
Ця відстань обчислюється таким чином:
![]() ;
(2.2)
;
(2.2)
відстань міських кварталів
(манхеттенська відстань). Ця відстань є середньою різниць по координатах. У
більшості випадків застосування такої відстані призводить до таких же
результатів, як і для звичайної відстані Евкліда. Проте при його застосуванні
вплив окремих великих різниць (викидів) зменшується (оскільки вони не зводяться
в квадрат). Формула для розрахунку манхеттенскої відстані:
![]() ;
(2.3)
;
(2.3)
відстань Чебишева. Ця відстань може
виявитися корисною, коли треба визначити два об'єкти як «різні», якщо вони
розрізняються по будь - якій одній координаті. Відстань Чебишева обчислюється
за формулою:
![]() ;
(2.4)
;
(2.4)
степенева відстань. Застосовується у
разі, коли необхідно збільшити або зменшити вагу, що відноситься до
розмірності, для якої відповідні об’єкти сильно відрізняються. Степенева
відстань обчислюється за наступною формулою:
![]() ,
(2.5)
,
(2.5)
де r і p - параметри, що визначаються користувачем. Параметр p відповідальний за поступове зважування різниць по окремих координатах, параметр r відповідальний за прогресивне зважування великих відстаней між об’єктами. Якщо обидва параметри - r і p - рівні 2, то ця відстань співпадає з відстанню Евкліда.
Вибір метрики повністю лежить на досліднику, оскільки результати кластеризації можуть істотно відрізнятися при використанні різних метрик [19].
Для даного випадку найбільш доцільна
метрика - Евклідова [5], так як дана міра ідеально підходить для розрахунку
географічних відстаней та бойових порядків. Решта метрик менш доцільніші, так
як вони застосовуються для вирішення інших специфічних завдань, і не придатні
для здійснення кластеризації просторових даних. Основні характеристики бойових
порядків засобів ППО і ознаки по яких можливо здійснювати кластеризацію
представлені у табл. 2.1.
Таблиця 2.1
Основні характеристики бойових порядків засобів ППО і ознаки по яких можливо здійснювати кластеризацію
|
Назва дивізіону |
Кількість бойових батарей, шт. |
Відстань між бойовими батареями, км |
Віддаленість від переднього краю, км |
Дальність зв’язку, км |
|
“Чапарел - Вулкан” |
3 |
8-15 |
>15 |
8-30 |
|
“Петріот” |
6 |
30-50 |
>40 |
30-100 |
|
“Удосконалений Хок” |
3-4 |
15-40 |
>35 |
15-80 |
Ознаки, по яким здійснюється кластеризація:
кількість бойових батарей - N;
відстань між бойовими батареями ![]() ;
;
віддаленість від переднього краю ![]() ;
;
дальність зв’язку
![]() .
.
2.2 Вибір
доцільного алгоритму кластеризації складних об’єктів моніторингу
Проаналізувавши відомі алгоритми кластеризації [4] , для вирішення задачі ідентифікації, найбільш доцільними є нечіткі алгоритми. Нечіткі методи кластеризації, на відміну від чітких, дозволяють одному і тому ж об’єкту належати одночасно кільком кластерам з різним ступенем приналежності. Нечітка кластеризація в багатьох ситуаціях переважає чітку, зокрема для об’єктів, розташованих на грані кластерів.
Алгоритм кластеризації складається з ряду блоків:
вибір початкового нечіткого розбиття n об’єктів k кластерів шляхом вибору матриці приналежності U розміру n x k;
пошук значення критерію нечіткої
помилки, використовуючи матрицю U:
![]() ,
(2.6)
,
(2.6)
де ![]() -
«центр мас» нечіткого кластера k :
-
«центр мас» нечіткого кластера k :
![]() ;
(2.7)
;
(2.7)
кожне спостереження «приписується» до одного з n кластерів - того, відстань до якого найкоротша;
розраховується новий центр кожного кластера як елемент, ознаки якого розраховуються як середнє арифметичне ознак об’єктів, що входять у цей кластер.
Відбувається така кількість ітерацій (повторюються кроки 3-4), поки кластерні центри не стануть стійкими (тобто при кожній ітерації в кожному кластері виявлятимуться одні й ті самі об’єкти). Це повторення грунтоване на мінімізації цільової функції, яка представляє собою відстань від будь-якого елемента кластера у центрі самого кластеру, зважених щодо членства класу, відносно іншого елемента кластера. Дисперсія всередині кластера буде мінімізована, а між кластерами - максимізована. Цей алгоритм може не підійти, якщо заздалегідь невідоме число кластерів, або необхідно однозначно віднести кожен об'єкт до одного кластера.
Переваги:
простота та швидкість виконання.
Недоліки:
результат кластеризації у найбільшій мірі залежить від випадкових початкових позицій кластерних центрів;
алгоритм чутливий до аномальних вимірів (викидів), які можуть викривлювати середнє.
Існують наступні алгоритми нечіткого кластерного аналізу:
FCM (Fuzzy c-means - нечітких c-середніх);
гірської кластеризації;
поступово зростаючого розбиття.
Алгоритм FCM
Алгоритм нечіткої кластеризації називають FCM - алгоритмом (Fuzzy Classifier Means, Fuzzy C-Means). Метою FCM - алгоритму кластеризації є автоматична класифікація безлічі об'єктів, які задаються векторами ознак в просторі ознак. Іншими словами, такий алгоритм визначає кластери і відповідно класифікує об'єкти. Кластери представляються нечіткими множинами, і, крім того, межі між кластерами також є нечіткими.алгоритм кластеризації припускає, що об'єкти належать усім кластерам з певним ступенем приналежності. Ступінь приналежності визначається відстанню від об'єкта до відповідних кластерних центрів. Даний алгоритм ітераційно обчислює центри кластерів і нові ступені приналежності об'єктів.
Алгоритм нечіткої кластеризації виконується наступним чином :
а) ініціалізація.
Вибираються наступні параметри:
необхідна кількість кластерів N, 2 <N <К;
міра відстаней (Евклідова);
фіксований параметр q;
початкова (на нульовій ітерації)
матриця приналежності ![]() об'єктів
об'єктів
![]() з
урахуванням заданих початкових центрів кластерів
з
урахуванням заданих початкових центрів кластерів ![]() .
.
б) регулювання позицій ![]() центрів
кластерів.
центрів
кластерів.
На t-му ітераційному кроці при
відомій матриці ![]() обчислюється
обчислюється ![]() відповідно
до викладеного вище рішенням системи диференціальних рівнянь.
відповідно
до викладеного вище рішенням системи диференціальних рівнянь.
в) корегування значень приналежності
![]() .
.
Враховуючи відомі ![]() ,
вираховуються
,
вираховуються ![]() , якщо
, якщо ![]() ,
в іншому випадку:
,
в іншому випадку:
![]() ;
(2.8)
;
(2.8)
г) зупинка алгоритму.
Алгоритм нечіткої кластеризації
зупиняється при виконанні наступної умови:
![]() ,
(2.9)
,
(2.9)
де || || − матрична норма (Евклідова);
ε − заздалегідь заданий рівень точності.
Алгоритм гірської кластеризації
Алгоритм пікового групування (гірської кластеризації), запропонований Р. Ягером та Д. Фільовим, не вимагає задавання кількості кластерів. Кластеризація гірським алгоритмом не є нечіткою, однак, її часто використовують при синтезі нечітких правил з даних.
Ідея алгоритму полягає в тому, що спочатку визначають точки, які можуть бути центрами кластерів. Далі для кожної такої точки розраховується значення потенціалу, що показує можливість формування кластера в її околиці. Чим щільніше розташовані об’єкти в околиці потенційного центра кластера, тим вище значення його потенціалу. Після цього ітераційно вибираються центри кластерів серед точок з максимальними потенціалами. Алгоритм гірської кластеризації можна записати як послідовність таких кроків:
а) формування потенційних центрів
кластерів, число яких Q повинно бути кінцевим. Центрами кластерів можуть бути
об'єкти кластеризації - екземпляри вибірки х. Тоді Q = S, де S - кількість
екземплярів у вибірці x. Другий спосіб вибору потенційних центрів кластерів
полягає в дискретизації простору вхідних ознак. Для цього діапазони зміни
вхідних ознак розбивають на кілька інтервалів. Проводячи через точки розбиття
прямі, паралельні координатним осям, одержуємо «сітковий» гіперкуб. Вузли цієї
сітки і будуть відповідати центрам потенційних кластерів. Позначимо через ![]() -
кількість значень, що можуть приймати центри кластерів за r-ою координатою, r =
1,2,...N. Тоді кількість можливих кластерів буде дорівнювати:
-
кількість значень, що можуть приймати центри кластерів за r-ою координатою, r =
1,2,...N. Тоді кількість можливих кластерів буде дорівнювати:
![]() ;
(2.10)
;
(2.10)
б) розрахунок потенціалу центрів
кластерів за формулою:
![]() ,
(2.11)
,
(2.11)
де ![]() -
потенційний центр q-го кластера;
-
потенційний центр q-го кластера;
![]() −
значення j-ої ознаки для q-го кластера;
−
значення j-ої ознаки для q-го кластера;
α − додатня константа;
![]() −
відстань (Евклідова) між потенційним центром кластера
−
відстань (Евклідова) між потенційним центром кластера ![]() та
об’єктом кластеризації
та
об’єктом кластеризації ![]() .
.
У випадку, коли об’єкти
кластеризації задані двома ознаками (N = 2), графічне зображення розподілу
потенціалу буде являти собою поверхню, що нагадує гірський рельєф (рис. 2.1).
Звідси і назва - гірський алгоритм кластеризації.
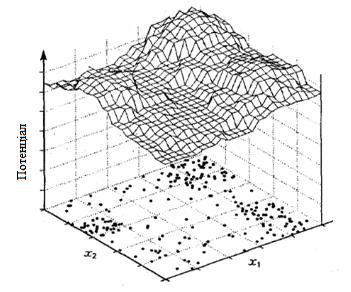
Рисунок 2.1 −
Розподіл
потенціалу при кластеризації гірським алгоритмом
в) вибір центрами кластерів координати «гірських» вершин. Для цього, центром першого кластера призначають точку з найбільшим потенціалом. Звичайно, найвища вершина оточена декількома досить високими піками. Тому призначення центром наступного кластера точки з максимальним потенціалом серед вершин, що залишилися, призвело б до виділення великого числа близько розташованих центрів кластерів.
Щоб вибрати наступний центр кластера
необхідно спочатку виключити вплив щойно знайденого кластера. Для цього
значення потенціалу для можливих центрів кластерів, що залишилися, перераховується
в такий спосіб: від поточних значень потенціалу віднімають внесок центра щойно
знайденого кластера (тому кластеризацію за цим алгоритмом іноді називають
субтрактивною). Перерахунок потенціалу відбувається за формулою:
![]() ,
(2.12)
,
(2.12)
де ![]() − потенціал на першій ітерації;
− потенціал на першій ітерації;
![]() −
потенціал на другій ітерації;
−
потенціал на другій ітерації;
β − додатня константа;
![]() −
номер першого знайденого центра кластера:
−
номер першого знайденого центра кластера:
![]() .
(2.13)
.
(2.13)
Номер центра другого кластера
визначається за максимальним значенням оновленого потенціалу:
![]() .
(2.14)
.
(2.14)
Потім знову перераховуються значення
потенціалів:
![]() .
(2.15)
.
(2.15)
д) якщо максимальне значення потенціалу перевищує деякий поріг, то здійснюється перехід до пункту б), у іншому випадку - зупинка. Алгоритм гірської кластеризації є ефективним, якщо розмірність вхідного вектора не є занадто великою. У іншому випадку (при великій кількості ознак) число потенційних центрів наростає лавиноподібно, і процес розрахунку чергових пікових функцій стає занадто тривалим, а процедура кластеризації - малоефективною.