Материал: part05
DICOM PS3.5 2020a - Data Structures and Encoding |
Page 131 |
G.5 RLE Header Format
The RLE Header contains the number of RLE Segments for the image, and the starting offset of each of the RLE Segments. Each of these numbers is represented by a UL (unsigned long) value stored in little-endian format. The RLE Header is 16 long words in length. This allows it to describe a compressed image with up to 15 RLE Segments. All unused segments offsets shall be set to zero.
Each of the starting locations for the RLE Segments are byte offsets relative to the beginning of the RLE Header. Since the RLE Header is 16 unsigned longs or 64 bytes, the offset of RLE Segment One is 64.
The following diagram illustrates the ordering of the offsets within the RLE Header.
Table G.5-1. Ordering of the Offsets Within the RLE Header
number of RLE Segments offset of RLE Segment 1 = 64 offset of RLE Segment 2
. . .
. . .
offset of RLE Segment n 0 0 0
G.6 Example of Elements For An Encoded YCbCr RLE Three-frame Image with Basic Offset Table
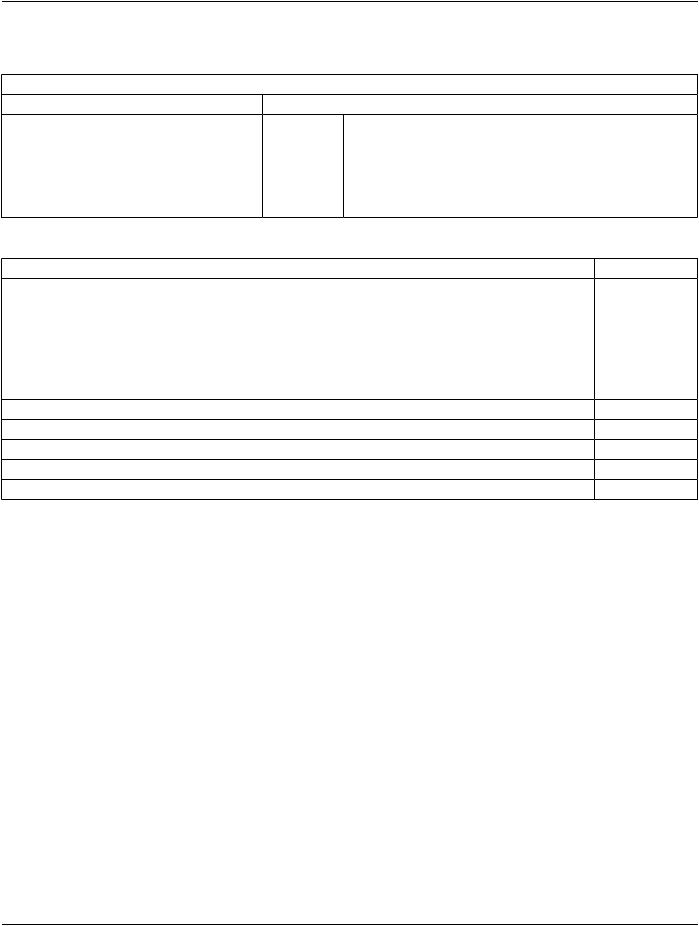
Table G.6-1 is an example of encoding of RLE Compressed Frames (described in Section G.4) with the basic offset table. Table G.6- 2 is an example of Item Value data for one frame.
Table G.6-1. Example of Elements for an Encoded YCbCr RLE Three-Frame Image with Basic Offset Table
Pixel Data |
Value |
Data |
|
|
Data Element |
|
|
|
ElementTagRepresentationElement |
|
|
|
|
|
|
||
|
|
Length |
|
|
|
|
|
|
|
|
|
Basic Offset Table with Item Value First Fragment (Frame 1) of Pixel Data |
|||||
|
|
|
Item Tag |
Item |
Item Value |
Item Tag |
Item |
Item Value |
|
|
|
|
Length |
|
|
Length |
|
(7FE0,0010) OB 0000HFFFFFFFFH(FFFE,E000) |
0000 |
0000 0000H(FFFE,E000) |
0000 |
RLE |
||||
with VR of |
|
undefined |
|
000CH |
0000 02D0H |
|
02C8H |
Compressed |
OB |
|
length |
|
|
0000 0642H |
|
|
Frame |
4 bytes |
2 bytes2 bytes 4 bytes |
4 bytes |
4 bytes |
000CH bytes |
4 bytes |
4 bytes 02C8H bytes |
||
- Standard -
Page 132 |
DICOM PS3.5 2020a - Data Structures and Encoding |
Table G.6-1b. Example of Elements for an Encoded YCbCr RLE Three-Frame Image with Basic Offset Table (continued)
Data Element Continued |
|
|
|
|
|
|
|
Second Fragment (Frame 2) of Pixel Data |
Third Fragment (Frame 3) of Pixel Data |
Sequence Delimiter Item |
|||||
Item Tag |
Item Length |
Item Value |
Item Tag |
Item Length |
Item Value |
Sequence |
Item Length |
|
|
|
|
|
|
Delimiter Tag |
|
(FFFE,E000) 0000 036AH |
RLE |
(FFFE,E000)0000 0BC8H |
RLE |
(FFFE,E0DD) 0000 0000H |
|||
|
|
Compressed |
|
|
Compressed |
|
|
|
|
Frame |
|
|
Frame |
|
|
4 bytes |
2 bytes |
036AH bytes |
4 bytes |
4 bytes |
0BC8H bytes |
4 bytes |
4 bytes |
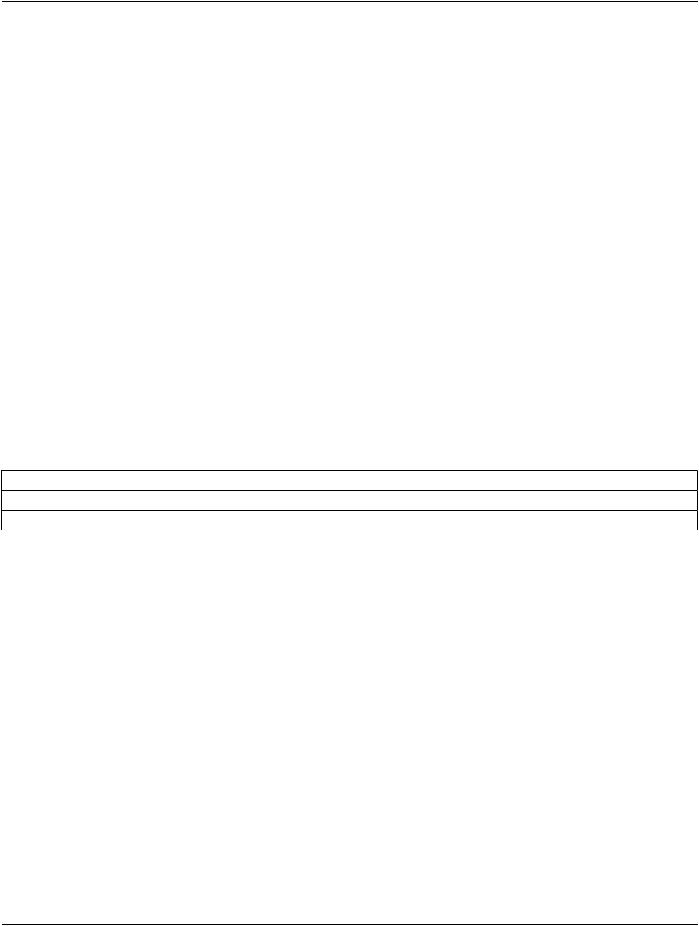
Table G.6-2. Example of Encoded YCbCr RLE Compressed Frame Item Value
|
Offset |
|
Data |
Description of Data |
|
0000 |
0000H |
0000 0003H |
number of RLE Segments |
(Header) |
|
|
|
0000 |
0040H |
location of RLE Segment 1 (Y component) |
|
|
|
0000 |
0140H |
locationofRLESegment2(CB component) |
|
|
|
0000 |
01C0H |
locationofRLESegment3(CR component) |
|
|
|
0000 |
0000H |
|
|
|
|
….. |
|
|
|
|
|
….. |
|
|
|
|
|
0000 |
0000H |
|
|
0000 |
0040H |
Y - RLE Segment Data |
|
(DATA) |
|
0000 |
0140H |
CB - RLE Segment Data |
|
(DATA) |
|
0000 |
01C0H |
CR - RLE Segment Data |
|
(DATA) |
|
- Standard -
DICOM PS3.5 2020a - Data Structures and Encoding |
Page 133 |
H Character Sets and Person Name Value Representation in the Japanese Language (Informative)
H.1 Character Sets for the Japanese Language
The purpose of this section is to explain the character sets for the Japanese language.
H.1.1 JIS X 0201
JIS X 0201 has the following code elements:
•ISO-IR 13 Japanese katakana (phonetic) characters (94 characters)
•ISO-IR 14 Japanese romaji (alphanumeric) characters (94 characters)
JIS X 0201 defines a 7-bit romaji code table (ISO-IR 14), a 7-bit katakana code table (ISO-IR 13), and the combination of romaji and katakana as an 8-bit code table (ISO-IR 14 as G0, ISO-IR 13 as G1).
The7-bitromaji(ISO-IR14)isidenticaltoASCII(ISO-IR6)exceptthatbitcombination05/12representsayensignandbitcombination 07/14 represents an over-line. These are national Graphic Character allocations in ISO 646.
The Escape Sequence for ISO/IEC 2022 is shown for reference in Table H.1-1 (for the Defined Terms, see PS3.3).
Table H.1-1. ISO/IEC 2022 Escape Sequence for ISO-IR 13 and ISO-IR 14
|
ISO-IR 14 |
ISO-IR 13 |
G0 set |
ESC 02/08 04/10 |
ESC 02/08 04/09 |
G1 set |
ESC 02/09 04/10 |
ESC 02/09 04/09 |
Note |
|
|
1.Table H.1-1 does not include the G2 and G3 sets that are not used in DICOM. See Section 6.1.2.5.1.
2.Defined Terms ISO_IR 13 and ISO 2022 IR 13 for the value of the Specific Character Set (0008,0005) support the G0 set for ISO-IR 14 and G1 set for ISO-IR 13. See PS3.3.
H.1.2 JIS X 0208
JIS X 0208 has the following code element:
•ISO-IR 87: Japanese kanji (ideographic), hiragana (phonetic), and katakana (phonetic) characters (942 characters, 2-byte).
H.1.3 JIS X 0212
JIS X 0212 has the following code element:
•ISO-IR 159: Supplementary Japanese kanji (ideographic) characters (942 characters, 2-byte)
The Escape Sequence for ISO/IEC 2022 is shown for reference in Table H.1-2 (for the Defined Terms, see PS3.3)
- Standard -

Page 134 DICOM PS3.5 2020a - Data Structures and Encoding
Table H.1-2. ISO/IEC 2022 Escape Sequence for ISO-IR 87 and ISO-IR 159
|
ISO-IR 87 |
ISO-IR 159 |
G0 set |
ESC 02/04 04/02 |
ESC 02/04 02/08 04/04 |
G1 set |
ESC 02/04 02/09 04/02 |
ESC 02/04 02/09 04/04 |
Note |
|
|
1.The Escape Sequence for the designation function G0-DESIGNATE 94-SET, has first I byte 02/04 and second I byte 02/08. There is an exception to this: The second I byte 02/08 is omitted if the Final Byte is 04/00, 04/01 or 04/02. See ISO/IEC 2022.
2.The table does not include the G2 and G3 sets that are not used in DICOM. See Section 6.1.2.5.1.
3.Defined Term ISO 2022 IR 87 for the value of the Specific Character Set (0008,0005) supports the G0 set for ISO-IR 87, and Defined Term ISO 2022 IR 159 supports the G0 set for ISO-IR 159. See PS3.3.
H.2 Internet Practice
DICOM has adopted an encoding method for Japanese character sets that is similar to the method for Internet practice.
The major protocols for the Internet such as SMTP, NNTP and HTTP adopt the encoding method for Japanese characters called "ISO-2022-JP" as described in RFC 1468, Japanese Character Encoding for Internet Messages. There is also a less commonly used Internet practice called "ISO-2022-JP-2" described in RFC 1554, which supports a larger repertoire of character sets and additionally requires an escape to a single-byte character set before encoding a SPACE (unlike DICOM and ISO-2022-JP).
The character sets supported for the Japanese language in DICOM and Internet practice are shown in Table H.2-1.
Table H.2-1. Character Sets for the Japanese language in DICOM and Internet practice
|
DICOM |
ISO-2022-JP |
|
ISO-2022-JP-2 |
ASCII (ISO-IR 6) |
ASCII (ISO-IR 6) |
ASCII (ISO-IR 6) |
||
JIS X 0201 |
Katakana (ISO-IR 13) |
JIS-X 0201 Romaji (ISO-IR 14) |
ISO8859-1 (ISO-IR 100) |
|
JIS X 0201 |
Romaji (ISO-IR 14) |
JIS X 0208-1978 Kanji (ISO-IR 42)ISO8859-7 Greek (ISO-IR 126) |
||
JIS X 0208 |
Kanji (ISO-IR 87) |
JIS-X 0208-1983 Kanji (ISO-IR 87)JIS X 0201 Romaji (ISO-IR 14) |
||
JIS X 0212 |
Kanji (ISO-IR 159) |
|
JIS X 0208-1978 |
Kanji (ISO-IR 42) |
|
|
|
JIS X 0208-1983 |
Kanji (ISO-IR 87) |
|
|
|
JIS X 0212-1990 |
Kanji (ISO-IR 159) |
|
|
|
GB2312-1980 (ISO-IR 58) |
|
|
|
|
KSC5601-1987 (ISO-IR 149) |
|
The Control Characters supported in DICOM and Internet practice are shown in Table H.2-2.
- Standard -

DICOM PS3.5 2020a - Data Structures and Encoding Page 135
Table H.2-2. Control Characters Supported in DICOM and Internet practice
DICOM |
ISO-2022-JP and ISO-2022-JP-2 |
LF (00/10) |
LF (00/10) |
FF (00/12) |
CR (00/13) |
CR (00/13) |
SO (00/14) |
ESC (01/11) |
SI (00/15) |
|
ESC (01/11) |
H.3 Example of Person Name Value Representation in the Japanese Language
Character strings representing person names are encoded using a convention for PN value representations based on component groups with 5 components.
For languages that use ideographic characters, it is sometimes necessary to write names both in ideographic characters and in phonetic characters. Ideographic characters may be required for official purposes, while phonetic characters may be needed for pronunciation and data processing purposes.
For the purpose of writing names in ideographic characters and in phonetic characters, up to 3 component groups may be used. The delimiter of the component group shall be the equals character "=" (3DH). The three component groups in their order of occurrence are: an alphabetic representation, an ideographic representation, and a phonetic representation.
H.3.1 Value 1 of Attribute Specific Character Set (0008,0005) is Not Present.
Example H.3-1. Value 1 of Attribute Specific Character Set (0008,0005) is Not Present
In this case, ISO-IR 6 is used by default in Specific Character Set:
(0008,0005) \ISO 2022 IR 87
Character String:
Yamada^Tarou= ^ = ^
Yamada^Tarou= ESC 02/04 04/02 ESC 02/08 04/02 ^ ESC 02/04 04/02 ESC 02/08 04/02 = ESC 02/04 04/02 ESC 02/08 04/02 ^ ESC 02/04 04/02 ESC 02/08 04/02
Encoded representation:
05/09 06/01 06/13 06/01 06/04 06/01 5/14 05/04 06/01 07/02 06/15 07/05 03/13 01/11 02/04 04/02 03/11 03/03 04/05 04/04 01/11 02/08 04/02 05/14 01/11 02/04 04/02 04/02 04/00 04/15 03/10 01/11 02/08 04/02 03/13 01/11 02/04 04/02 02/04 06/04 02/04 05/14 02/04 04/00 01/11 02/08 04/02 05/14 01/11 02/04 04/02 02/04 03/15 02/04 06/13 02/04 02/06 01/11 02/08 04/02
An example of what might be displayed or printed by an ASCII based machine that displays or prints the Control Character ESC (01/11) using \033:
Yamada^Tarou=\033$B;3ED\033(B^\033$BB@O:\033(B=\033$B$d$^$@\033(B^\033$B$?$m$&\033(B
- Standard -