Материал: Анализ ценовых стратегий на рынке мобильной связи Российской Федерации
Если коэффициент -0.2<β<0.2, то можно говорить, что повышение коэффициента на одну единицу влечет за собой увеличение зависимой переменной на β*100%.
Модель строится с помощью метода наименьших квадратов.
На выходе имеется ряд коэффициентов, с помощью которых можно составить представление о взаимосвязи переменных.
Согласно модели можно составить следующую формулу стоимости мобильной связи:
«Логарифм стоимости «средней корзины»» = 5,84 + 9,61Е-06*«средняя заработная плата по региону» + 2,37Е-05*«спрос на сотовую связь» - 0,0894*«количество операторов, действующих в регионе».
Коэффициенты 9,61Е-06; 2,37Е-05; -0,0894 - это коэффициенты β1, β2, β3, которые отражают, насколько значение «стоимости корзины» зависит от изменения показателей, к которым эти коэффициенты относятся. В модели полученные коэффициенты являются значимыми. Это определяется с помощью T-статистики (t-Statistic), которая рассчитывается как отношение оценки коэффициента к его стандартной ошибке и используется для проверки гипотезы о том, что коэффициент равен нулю. Для проверки необходимо определить уровень значимости, вычислить t-критическое и сравнить с расчетным значением.
Полученные коэффициенты значимы, а это значит, что выбранные показатели влияют на стоимость «средней корзины» и факт наличия сегментации рынка в соответствии с данными критериями подтверждается.
Интерпретировать полученные коэффициенты можно следующим образом: если количество компаний-операторов, действующих в регионе, увеличится 1 единицу, то стоимость мобильной связи в регионе снизится на 9,35%. Кроме того, увеличение на 1 единицу показателя объема услуг связи, оказанных населению, то есть спроса на мобильную связь, увеличивает цену «корзины» на 9,61Е-04%; а увеличение средней заработной платы в регионе на 1 рубль влечет за собой увеличение цены на мобильную связь на 0,00237%. Эти данные подтверждают предположения о направлении зависимостей, описанные выше.. Error (стандартная ошибка) - это показатель надежности расчетного параметра. Стандартная ошибка - это стандартное отклонение оценок, которые будут получены при многократной случайной выборке данного размера из одной и той же совокупности. Как видно по данным, стандартные ошибки коэффициентов небольшие. Полученные значения могут варьироваться в пределах полученной стандартной ошибки. squared, то есть коэффициент детерминации, который равен отношению ESS к TSS, - это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости. Его рассматривают как универсальную меру связи одной случайной величины от множества других случайных величин. Чем ближе значение коэффициента к 1, тем сильнее зависимость. С помощью коэффициента детерминации определяют точность модели.
В изучаемой модели коэффициент детерминации равен 0,56. Это говорит о том, что модель не совсем точная, но неплохая. Неточность модели можно объяснить тем, что в ней не учитывается себестоимость мобильной связи, которая тоже влияет на стоимость «корзины». Но, тем не менее, полученная модель верно отражает искомые зависимости.статистика нужна для определения значимости модели. В данном случае модель значимая.
Таким образом, предположение о том, что цена на мобильную связь в каждом регионе России зависит от уровня жизни, степени конкуренции, а также спроса на сотовую связь в данном регионе, подтвердилось. В результате была получена значимая модель множественной регрессии со значимыми коэффициентами.
Также необходимо отметить, что в полученной
модели важную роль играет уровень конкуренции в регионе, так как один
дополнительный игрок на рынке мобильной связи в регионе снижает стоимость
мобильной связи на целых 9%.
.3.2 Тестирование модели
Для проверки качества модели были проведены различные тесты.
Были проведены самые основные тесты: проверка остатков на нормальность, проверка на правильность спецификации и функциональной формы, проверка на гетероскедастичность.
А. Тест на нормальность остатков.
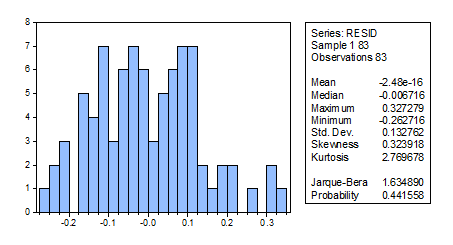
Рисунок 12. Тест на нормальность остатков
Тест Jarque-Bera не позволяет отвергнуть гипотезу о нормальном распределении остатков модели. Этот тест проверяет распределения на нормальность путем сверки показателей асимметрии и эксцесса со значениями этих показателей, характерными для нормального распределения (асимметрия=0, эксцесс=3). Но данный тест является довольно слабым инструментов для проверки на нормальность.
Следом был проведен другой тест проверки остатков
на нормальность распределения:
Таблица 5.
Тест проверки остатков на нормальность распределения
|
Empirical Distribution Test for RESID |
|
|||
|
Hypothesis: Normal |
|
|
||
|
Date: 06/16/13 Time: 15:33 |
|
|
||
|
Sample: 1 83 |
|
|
|
|
|
Included observations: 83 |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
Method |
Value |
Adj. Value |
Probability |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Lilliefors (D) |
0.058909 |
NA |
> 0.1 |
|
|
Cramer-von Mises (W2) |
0.038622 |
0.038855 |
0.7031 |
|
|
Watson (U2) |
0.033449 |
0.033650 |
0.7540 |
|
|
Anderson-Darling (A2) |
0.302714 |
0.305548 |
0.5672 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Данный тест показывает, что распределение остатков близко к нормальному.
Нормальность распределения остатков не влияет на эффективность, несмещенность и состоятельность МНК-оценок, но нормальность их распределения нужна для корректного тестирования гипотез с помощью t- и F-статистик. Она редко наблюдается, но, по возможности, необходимо стремиться к тому, чтобы распределение остатков было близким к нормальному.
Б. Тест на функциональную форму
Затем был проведен Ramsey RESET-test на
функциональную форму. Этот тест основан на вспомогательной регрессии зависимой
переменной на факторы исходной модели и, плюс, различные степени оцененных по
исходной модели значений зависимой переменной.
Таблица 6.
Тест на функциональную форму
|
Ramsey RESET Test: |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
F-statistic |
2.891687 |
Prob. F(2,77) |
0.0615 |
|
|
Log likelihood ratio |
6.011012 |
Prob. Chi-Square(2) |
0.0495 |
|
|
|
|
|
|
|
|
|
|
|
|
|
value близко к 5%, так что ситуация пограничная. На 10% уровне статистика теста значимо отлична от нуля (гипотеза о том, что квадрат и куб предсказанных значений незначимы, отвергается на 10% уровне значимости). На 5% уровне значимости ошибка спецификации не выявляется.
В. Проверка на гетероскедастичность
Сначала был проведен тест Уайта:
Таблица 7.
Тест Уайта на гетероскедастичность
|
Heteroskedasticity Test: White |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
F-statistic |
1.887664 |
Prob. F(9,73) |
0.0672 |
|
|
Obs*R-squared |
15.66953 |
Prob. Chi-Square(9) |
0.0741 |
|
|
Scaled explained SS |
12.56083 |
Prob. Chi-Square(9) |
0.1835 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Тест White проверяет гипотезу о том, что в модели имеется постоянство дисперсии остатков, то есть, нет гетероскедастичности. P-value также близко к 5%, как и в предыдущем тесте, так что ситуация пограничная. В данном случае гипотеза не отклоняется на 10% уровне значимости.
В тесте White сначала строится зависимость квадратов остатков от объясняющих переменных, их квадратов и всех или некоторых попарных произведений. И проводится тест на значимость регрессии. Проверяется гипотеза о том, что все коэффициенты перед объясняющими переменными равны нулю.
Также если ![]() ,
то регрессия значима в целом, и имеет место гетероскедастичность.
,
то регрессия значима в целом, и имеет место гетероскедастичность.
В тесте White вспомогательная регрессия более гибкая, что позволяет выявить гетероскедастичность почти любой формы. Но при большом количестве объясняющих переменных в регрессии становится слишком много параметров, из-за чего тест может не обнаружить гетероскедастичности, когда она есть.
Были проведены другие тесты на
гетероскедастичность.
Таблица 8.
Тест Бройша-Пагана-Годфри на гетероскедастичность
|
Heteroskedasticity Test: Breusch-Pagan-Godfrey |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
F-statistic |
0.847565 |
Prob. F(3,79) |
0.4720 |
|
|
Obs*R-squared |
2.588136 |
Prob. Chi-Square(3) |
0.4596 |
|
|
Scaled explained SS |
2.074671 |
Prob. Chi-Square(3) |
0.5571 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Тест Бройша-Пагана-Годфри применяется в тех случаях,
когда проверяется нулевая гипотеза об отсутствии гетероскедастичности.
Альтернативная гипотеза о том, что имеет место гетероскедастичности вида ![]() ,
где
,
где ![]() -
это вектор независимых переменных. Другими словами, данный тест выявляет
простую гетероскедастичность линейного типа. В данном случае, так как p-value
> 0.05, то нулевая гипотеза о постоянстве дисперсии остатков не отклоняется.
-
это вектор независимых переменных. Другими словами, данный тест выявляет
простую гетероскедастичность линейного типа. В данном случае, так как p-value
> 0.05, то нулевая гипотеза о постоянстве дисперсии остатков не отклоняется.
Таблица 9.
Тест Харви на гетероскедастичность
|
Heteroskedasticity Test: Harvey |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
F-statistic |
0.290557 |
Prob. F(3,79) |
0.8321 |
|
|
Obs*R-squared |
0.905812 |
Prob. Chi-Square(3) |
0.8240 |
|
|
Scaled explained SS |
1.123076 |
Prob. Chi-Square(3) |
0.7715 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Тест Харви почти такой же, как тест Бройша-Пагана-Годфри.
Он тоже проверяет гипотезу о постоянстве дисперсии остатков. Но в отличие от
первого теса тест Харви имеет альтернативную гипотезу о том, что наблюдается
гетероскедастичность вида ![]() , где
, где ![]() -
это вектор независимых переменных. Другими словами, выявляется экспоненциальная
зависимость.
-
это вектор независимых переменных. Другими словами, выявляется экспоненциальная
зависимость.
В данном случае нулевая гипотеза не отклоняется,
что говорит об отсутствии гетероскедастичности такого типа.
Таблица 10.
Тест Глейзера на гетероскедастичность
|
Heteroskedasticity Test: Glejser |
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
F-statistic |
0.425702 |
Prob. F(3,79) |
0.7351 |
|
|
Obs*R-squared |
1.320425 |
Prob. Chi-Square(3) |
0.7243 |
|
|
Scaled explained SS |
1.191964 |
Prob. Chi-Square(3) |
0.7549 |
|
|
|
|
|
|
|
|
|
|
|
|
|
Следующий тест - тест Глейзера - так же, как предыдущие тесты, проверяет гипотезу об отсутствии гетероскедастичности.
Тест Глейзера выявляет значимость
вспомогательных регрессионных зависимостей модуля остатков от функциональных
форм каждого регрессора.
![]() ,
, ![]() ,
,
![]() ,
j = {2, … k}
,
j = {2, … k}
Если коэффициент β значим хотя бы в одной из трех регрессий, то имеет место гетероскедастичность.
В данном случае гипотеза об отсутствии гетероскедастичности не отклоняется, значит, имеет место гомоскедастичность.
Таким образом, гетероскедастичность не была выявлена.
Также при тестировании модели было установлено, что в ней отсутствует мультиколлениарность.
Таким образом, модель получилась значимая и точная, что доказывает влияние выбранных факторов на цену в каждом регионе страны.
Однако может возникнуть вопрос: а что если изменение цен в зависимости от региона в большей степени зависит не от выбранных критериев, а от того, что в каждом регионе операторы имеют разные издержки на услуги мобильной связи? Ответить на этот вопрос помогла статья Н.О. Шпагиной (Шпагина, 2008). В статье проводится детальный расчет себестоимости услуг мобильной связи, согласно которому установленная себестоимость услуг следующая: