Материал: Алгебра_кортежей
Для вычисления P(Q) сначала найдем дополнение Q:
{a2}
Q = {a1}
|
|
|
{e3} |
||
{b3} |
|
{d3} |
|
|
|
. |
|||||
{b} {c } |
|
|
|||
{e} |
|||||
1 |
3 |
|
1 |
|
|
{c1} |
{d1,d2} |
|
|||
Используя методы п. 3.1, преобразуем Q в ортогональную C-систему:
|
|
|
|
2 |
|
|
1 |
1 |
|
3 |
|
|
|
|
|
|
{a |
|
} {b} {c} {d |
|
} |
|
|||||
|
|
|
|
|
|
{b1} |
|
{d3} |
{e3} |
|
|||
|
|
|
{a1} |
|
|||||||||
|
|
|
{a |
|
} {b ,b } {c} |
{d |
|
} |
{e} |
|
|||
|
|
|
|
2 |
|
2 |
3 |
1 |
|
3 |
|
1 |
|
|
Q |
= |
{a2} |
{b3} |
|
{d1,d2} |
{e1} |
. |
|||||
|
|
|
{a} {b ,b } {c } {d |
|
} |
{e } |
|
||||||
|
|
|
|
1 |
|
2 |
3 |
3 |
|
3 |
|
3 |
|
|
|
|
{a2} |
{b3} |
{c3} {d1,d2} |
{e2,e3} |
|||||||
|
|
|
|
|
|
{b3} {c3} {d1,d2} |
{e3} |
|
|||||
|
|
|
{a1} |
|
|||||||||
Подставляя в эту матрицу значения вероятностей из таблицы, получим значение P(Q) = 0.13012. Отсюда P(Q) = 1 – P(Q) = 0.86988. Заметим, что вероятности сложных компонент, например, {b2, b3}, равны сумме вероятностей элементов этих компонент.
Чтобы вычислить P( x2(Q)), можно воспользоваться алгоритмом, приведенным в п. 4.5. Тогда:
{a1} |
|
|
|
|
|
|
|
{e1,e2} |
||
x2(Q) = {a2} |
{c2,c3} |
{d3} |
|
|
|
. |
||||
|
|
{c ,c |
} {d ,d |
} |
{e ,e } |
|||||
|
|
1 |
2 |
|
1 |
2 |
|
2 |
3 |
|
Полученная C-система не ортогональна. Можно воспользоваться уже известным методом и ортогонализовать дополнение этой C-системы. Но в данном случае можно поступить проще. Проанализируем множество {C1, C2, C3} C-кортежей полученной C-системы. Среди них только одна пара {C1, C3} не ортогональна. Найдем пересечение этих C-кортежей:
C1 С3 = [{a1} {c1, c2} {d1, d2} {e2}].
Следовательно, можно применить формулу:
P( x2(Q)) = P(C1) + P(C2) + P(C3) – P(C1 С3).
После подстановки значений вероятностей элементарных событий в
170
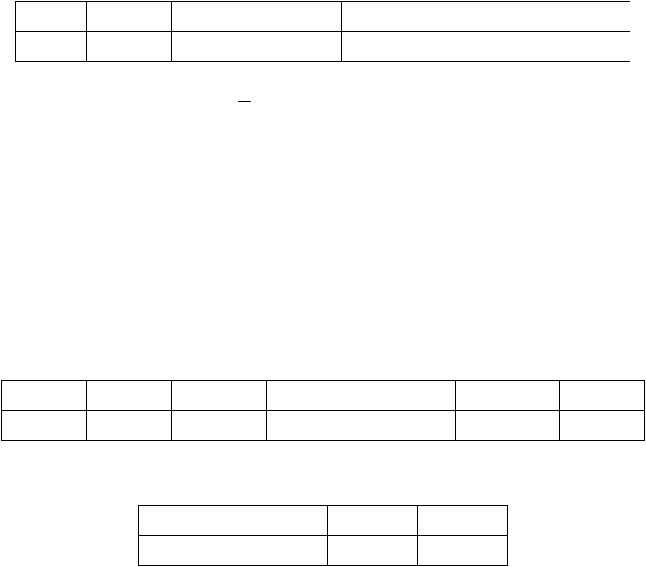
формулу получим:
P( x2(Q)) = 0.6864.
Опишем систему, где события заданы пересекающимися интервалами. Пример 5.2. Система задана в пространстве X Y, где атрибуты
представлены в виде интервалов, при этом X = [0, 7] и Y = [0, 5]. Заданы также плотности распределения вероятностей f1(x, d1, e1) и f2(y, d2, e2) на атрибутах, где d1, e1, d2, e2 – параметры распределений. В этой системе задано составное событие в виде АК-объекта
{a1} {b1} R[XY] = {a2,a4} {b2} ,
{a3} {b3}
где ai, bj – интервалы, заданные в табл. 5.2:
|
|
|
|
|
|
Таблица 5.2. |
a1 |
a2 |
a3 |
a4 |
b1 |
b2 |
b3 |
[0, 2.8] |
[1.7, 3.4] |
[3.4, 5.5] |
[4.3, 6.4] |
[0, 2.3] |
[1.4, 3.2] |
[2.3, 5.0] |
Необходимо определить последовательность расчетов для вычисления вероятности событий R и y(R).
Чтобы решить задачу, достаточно использовать только открытые интервалы. Для элементаризации системы построим возрастающие ряды
границ интервалов в атрибутах: |
|
|
|
|
|
|
|||
для X: 0; 1.7; 2.8; 4.4; 4.3; 5.5; 6.4; 7; |
|
|
|
|
|
||||
для Y: 0; 1.4; 2.3; 4.2; 5. |
|
|
|
|
|
|
|
||
После этого получим следующие множества |
элементарных |
интервалов |
|||||||
(таблицы 5.3 и 5.4): |
|
|
|
|
|
|
|
|
|
для X: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 5.3. |
r1 |
r2 |
r3 |
|
r4 |
|
r5 |
|
r6 |
r7 |
(0, 1.7) |
(1.7, 2.8) |
(2.8, 3.4) |
(3.4, 4.3) |
(4.3, 5.5) |
(5.5, 6.4) |
(6.4, 7) |
|||
для Y: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Таблица 5.4. |
|
|
q1 |
|
q2 |
|
q3 |
|
q4 |
|
|
(0, 1.4) |
(1.4, 2.3) |
(2.3, 3.2) |
(3.2, 5) |
|
||||
|
|
|
|
|
171 |
|
|
|
|

Соответственно:
a1 = {r1, r2}; a2 = {r2, r3}; a3 = {r4, r5}; a4 = {r5, r6}; b1 = {q1, q2}; b2 = {q2, q3}; b3 = {q3, q4}.
Тогда после подстановки найдем:
|
{r1,r2} |
{q1,q2} |
|||
R = {r2 ,r3 ,r5 ,r6} |
{q2 ,q3} . |
||||
|
{r ,r } |
{q |
3 |
,q |
} |
|
4 5 |
|
|
4 |
|
Для каждого кванта ri или qj вычислим соответствующую вероятность. Например,
P(r3) = 3,4 f1 (x,d1,e1 ).
2,8
Теперь можно приступить к ортогонализации соответствующих сложных событий. Для события R вычислим R и, после преобразования R в ортогональную C-систему, найдем P(R) = 1 – P(R).
|
|
|
|
{r3 ,r4 ,r5 ,r6 ,r7} |
{q3 ,q4} |
|
|
|
|
|
|
{q3 |
,q4 |
} |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
{r ,r ,r } |
{q ,q |
|
} |
= |
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
R |
= |
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||||
|
|
|
|
|
|
1 |
4 |
7 |
|
|
|
1 |
|
4 |
|
|
|
{r ,r ,r ,r ,r } {q ,q |
} |
|
|
|
|
|
|
|
|||||||
|
|
|
|
{r ,r ,r ,r ,r } |
{q ,q |
2 |
} |
|
|
3 |
4 |
5 6 |
7 |
|
1 |
2 |
|
|
|
|
|
|
|
|
|||||||||
|
|
|
|
|
1 |
2 |
3 |
6 |
|
7 |
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
{r ,r ,r ,r ,r } {q } |
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 |
4 |
5 |
6 |
7 |
1 |
|
|
|
|
|
|
|
|
{q1,q4 |
} |
|
|
|
|
|
|
|
|
|
{q1 |
,q2 |
} |
= |
|
|
{r4 ,r7} |
|
{q2 |
} |
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
{r ,r } |
|
|
|
. |
|||||||
|
|
|
{r ,r ,r } {q |
|
,q } |
|
{r ,r ,r ,r ,r } {q |
,q } |
|
|
|
|
{q } |
||||||||||||||||||||
|
|
|
|
1 |
4 |
7 |
|
|
2 |
3 |
|
|
|
|
1 |
|
2 |
3 |
6 |
7 |
3 |
4 |
|
|
|
|
1 |
|
7 |
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
{r1,r2 ,r3,r6 ,r7} |
{q4} |
|||||||
Подставляя вероятности квантов и используя теоремы 5.1 и 5.2, имеем:
P(R) = 1 – P(R) = 1 – ((P(r3) + P(r4) + P(r5) + P(r6) + P(r7))P(q1) + (P(r4) + + P(r7))P(q2) + (P(r1) + P(r7))P(q3) + (P(r1) + P(r2) + P(r3) + P(r6) + P(r7))P(q4)).
Далее, вычисляем:
{r3,r4 ,r5 ,r6 ,r7}
y(R) = –Y(R[XY]) = {r1,r4 ,r7} = {r7}.{r1,r2 ,r3,r6 ,r7}
Отсюда P( y(R)) = P(r7).
В данном примере сравнительно легко непосредственно преобразовать C-систему R в ортогональную, используя то обстоятельство, что она
представляет бинарное отношение и имеет в атрибуте Y сравнительно немного
172
компонент. Учитывая это, разложим C-систему R так, чтобы в атрибуте Y были только одноэлементные множества, а затем объединим C-кортежи, у которых компоненты в атрибуте Y одинаковы. Находим:
{r1,r2}
R= {r2 ,r3 ,r5 ,r6}{r4 ,r5}
{q1,q2} {q2 ,q3} = {q3 ,q4}
|
{r1,r2} |
q1 |
|
|
|
|
|
|
|
|
|
|
|
{r1,r2} |
q2 |
|
|
|
|
{r1,r2} |
q1 |
||||
|
|
|
|
|
|
{r ,r ,r ,r ,r } |
|
|
|
|||
{r ,r ,r ,r} |
q |
|
|
= |
q |
|
||||||
|
2 3 5 6 |
|
2 |
|
|
1 |
2 |
3 5 6 |
|
2 |
. |
|
{r2,r3,r5,r6} |
q3 |
|
{r2 ,r3 ,r4 ,r5 ,r6} |
q3 |
|
|||||||
{r ,r} |
q |
|
|
|
{r ,r } |
q |
4 |
|
||||
|
4 5 |
|
3 |
|
|
|
|
4 |
5 |
|
|
|
{r4,r5} |
|
|
|
|
|
|
|
|
|
|
||
|
q4 |
|
|
|
|
|
|
|
|
|||
Тогда можно получить другую, несколько более простую, формулу вероятности события R:
P(R) = (P(r1) + P(r2))P(q1) + (P(r1) + P(r2) + P(r3) + P(r5) + P(r6))P(q2) + + (P(r2) + P(r3) + P(r4) + P(r5) + P(r6))P(q3) + (P(r4) + P(r5))P(q4).
5.1.3. Вероятностная логика на основе АК
Термин "вероятностная логика" получил широкое распространение в работах по искусственному интеллекту после опубликования статьи известного специалиста по искусственному интеллекту Н. Нильсона [Nilsson, 1986]. Его идея была продолжена другими исследователями. В публикациях по вероятностной логике ставилась следующая задача: заданы оценки вероятностей некоторого множества событий, представленных формулами исчисления высказываний, необходимо найти вероятностную оценку события, заданного логической формулой, отличающейся от исходных. Другой аспект совмещения вероятности и логики – логико-вероятностный анализ [Рябинин, 1981], где вероятность формул вычисляется по вероятностям значений логических переменных, – в этих работах не рассматривался. Кроме того, анализ работ по вероятностной логике показывает, что в них результатом соединения классических понятий "вероятность" и "логика" оказываются некоторые неклассические логики. Далее рассматривается концепция вероятностной логики в классическом варианте через призму алгебры кортежей.
Совмещение понятий "логика" и "вероятность" вызывает немало трудностей. На первый взгляд, здесь все просто, если взять за основу
173
аксиоматику вероятности, предложенную А.Н. Колмогоровым [Колмогоров, 1972], в которой алгебра событий, погруженных в вероятностную меру, соответствует алгебре множеств. Например, для событий, представленных множествами A и B, вероятностная мера их объединения вычисляется по формуле:
P(A B) = P(A) + P(B) – P(A B).
Таким образом, для точного вычисления вероятности события (A B) помимо вероятностей P(A) и P(B) необходимо знать вероятность P(A B), в рамках некоторых ограничений (в частности, P(A B) min(P(A), P(B))) не зависящую от P(A) и P(B). Если при этом A B , то события A и B зависимы. Но когда A и B являются не множествами, а разными логическими переменными исчисления высказываний, то вероятность дизъюнкции этих событий вычисляется по формуле:
P(A B) = P(A) + P(B) – P(A)P(B),
для вычисления которой достаточно задать только вероятность событий A и B. Возникает вопрос: почему для логических соотношений имеет место другая методика расчета вероятности, хотя многим представляется, что алгебра множеств и булева алгебра изоморфны? Ответ на него оказывается ключевым при совмещении понятий "логика" и "вероятность". Дело в том, что в классической логике элементарные события, соответствующие разным логическим переменным, несовместимы, потому что любая логическая формула, содержащая n свободных переменных, изоморфна некоторому n-местному отношению, и события, соответствующие различающимся переменным, принадлежат разным атрибутам. Другими словами, логические переменные могут быть зависимыми, но не изначально, а только потому, что они содержатся в некоторой логической формуле, которая и определяет
зависимость между ними.
Абсурдность (с точки зрения математической логики) иного подхода видна из следующего примера, который иногда приводится в работах по вероятностной логике: для логических переменных (но не формул!) X и Y даются вероятности P(X), P(Y) и P(X Y), причем последняя вероятность не обязательно равна произведению предыдущих.
Значит, при погружении логических систем в вероятностное пространство
174