Материал: 1210

76
Цепные коды. При цепном (непрерывном кодировании) последовательности a j и bj не могут быть разбиты на блоки. Связи при цепном кодировании носят скользящий характер. Множество всех возможных кодовых (разрешенных) последовательностей bj называют цепным кодом.
Простейшим примером служит дельта-код, символы которого формируются по правилу bj aj aj 1 , где знак вычитания по модулю mb . Пусть
ma mb 8. Тогда отрезку сообщения a j
соответствует отрезок кодовой последовательности bj :
Покажем формирование нескольких первых элементов
и т.д.
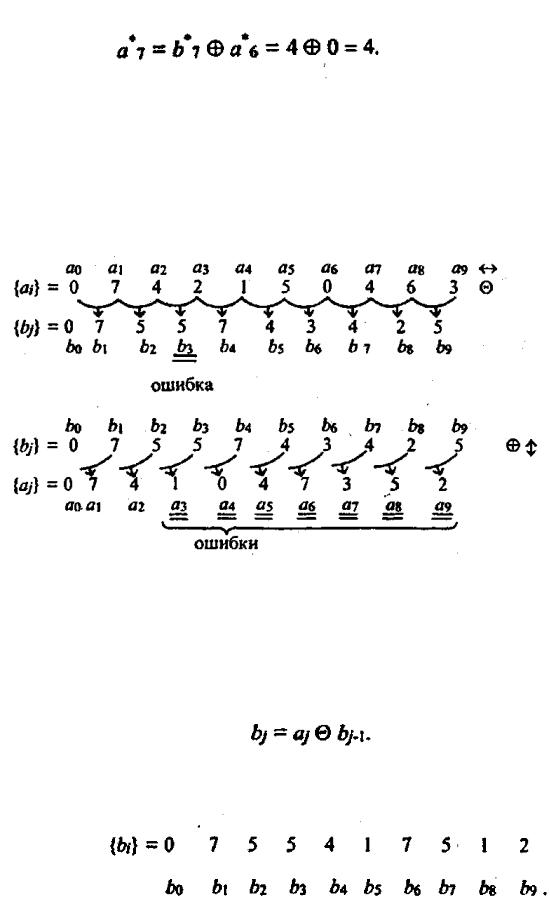
При декодировании принимаемые элементы сообщения вычисляют по правилу
77
Висходной последовательности {аj} пятый элемент а5 действительно
равен 5.
Висходной последовательности элемент aj = 4.
Поскольку декодирование каждой последующей позиции опирается на результат декодирования предшествующей позиций, дельта - коду свойственно явление размножения ошибок. Если, например, в приведенной кодовой по-
следовательности (принятой) bj четвертый символ b3 6 принимается как b3 5 , то далее последовательность будет декодироваться следующим образом:
Сравнивая запись последовательности чисел a j , (т.е. исходной после-
довательности) и последовательности чисел a j , (т.е. принятой последова-
тельности), видно, что, начиная с четвертой позиции (a3 и далее) идут ошибочно принятые символы.
Для устранения явления размножения ошибок вместо дельта-кода применяют относительный код, символы которого формируются по правилу
При этом тому же отрезку сообщения a j , который был выбран ранее, соответствует следующий отрезок кодовой последовательности
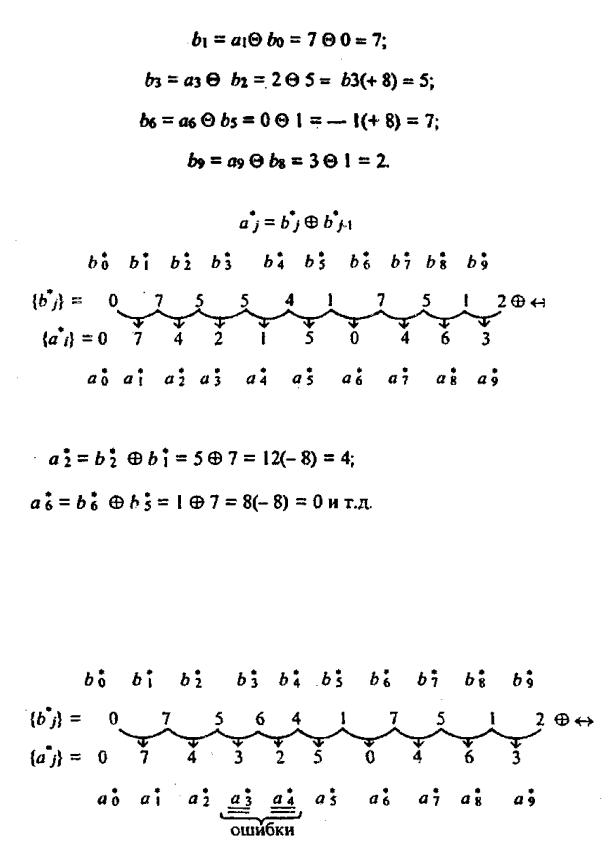
78
Покажем, как получились некоторые элементы последовательности bi :
Декодирование относительного кода осуществляется по правилу
Последовательность a j получилась следующим образом:
Как видно, a j совпала с a j .
Как и в предыдущем примере, введем ошибку в один из символов принятой последовательности bj , например в четвертой позиции b3 принята
цифра не 5, а 6. Запишем декодирование такой последовательности символов в соответствии с приведенным алгоритмом:
В данном случае появление ошибочного символа в принятой последовательности bj привели к появлению только двух ошибок в декодирован-
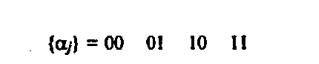
79
ной последовательности a j по сравнению с исходной последовательностью
a j . Отсюда следует, что относительный код в отличие от дельта-кода не
производит размножение ошибок, а дает на один ошибочно принятый символ две ошибки при декодировании, |Это является существенным достоинством относительного кода. |
Соотношения bj aj aj 1 и bj aj bj 1 являются рекуррентными,
поэтому цепные коды, символы которых формируются по рекуррентным со-
отношениям, называют рекуррентными кодами.
3.4 Блочные корректирующие коды
Коды, способные обнаруживать и исправлять ошибки и стирания, внесенные дискретным каналом, называются корректирующими. Отметим, что под ошибкой понимается замена одного переданного символа на какой-либо другой из-за каких-то воздействующих факторов. Под стиранием понимается отсутствие символа на соответствующей временной позиции из-за тех же воздействующих факторов (символ стирается).
Наибольшее распространение на практике получили блочные равномерные корректирующие коды. При достаточно большой длине такие коды позволяют получить сколь угодно малую вероятность ошибки при скорости передачи информации, сколь угодно близкой к пропускной способности дискретного канала, причем случайно выбранный код с высокой вероятностью близок к оптимальному. Это не снимает вопрос о выборе кода при ограниченных задержках и тем более вопрос о технической реализации корректирующих кодов.
Как отмечалось, блочный код длины п является корректирующим, если число K mak его кодовых комбинаций меньше числа N man всех возможных mb -ичных n-наборов.
Для декодирования с обнаружением ошибок достаточно сравнить принимаемую комбинацию со всеми возможными кодовыми комбинациями и стереть ее, если она не совпадет ни с одной из них. При этом возможны ситуации, когда обнаруживаются некоторые сочетания ошибок ε, преобразующие одну кодовую комбинацию в другую. В общем случае обнаруживаемость сочетания ошибок зависит от вида переданной кодовой комбинации.
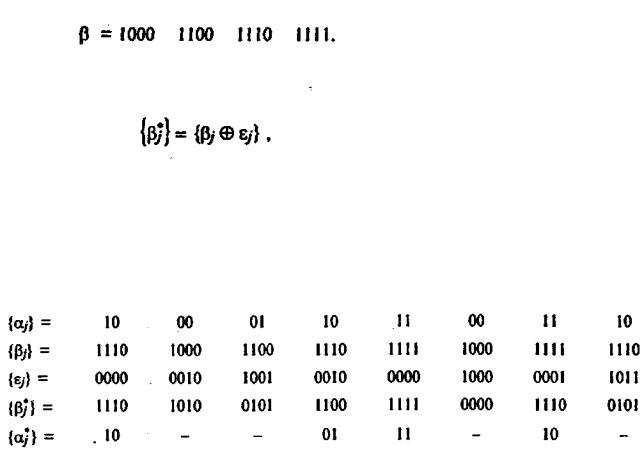
Покажем это на конкретном примере. Пусть имеется код следующих сочетаний
и из кода получаем новый код со следующими кодовыми сочетаниями:
80
На приемной стороне декодирование осуществляется по алгоритму
где j - сочетание возможных ошибок.
Построим соответствующую таблицу взаимных сочетаний сообщенийa j , кодовых комбинаций j , ошибок j , принимаемых комбинаций
|
|
|
, выдаваемых получателю информации при декодиро- |
j |
и сочетаний a j |
вании с обнаружением ошибок:
Из полученных сочетаний следует, что при передаче выбранной комбинации сообщений a j обнаруживаются ошибки (показанные в последова-
тельности черточками) на 2-й, 3-й, 6-й и 8-й позициях. В этом случае
j
получились комбинации j , которые отсутствуют в исходной кодовой таб-
лице соответствия j и j , т.е. запрещенные кодовые комбинации 1010, 0101, 0000. В то же время наличие ошибки j 0010 не дало обнаружения ошибки j 1110 , так как при декодировании получили j , что является
разрешенной комбинацией и декодировалось как 01 при передаче
j
j 10 .
Таким образом возможны ситуации, как отмечалось, когда одно и то же значение ошибки 0010 позволяет обнаружить ошибку (передавалось значение j 10 ) и одновременно не обнаружить ее (передавалось значение
j 10 ), т.е. это определяется видом исходного сообщения.
Отметим, что код с расстоянием d обнаруживает любые сочетания ошибок кратности q<d (максимальная кратность полностью обнаруживаемых ошибок q0 = d - 1). Следовательно, чтобы обнаружить, например 2 ошибки, нужно иметь кодовое расстояние между комбинациями d = 3.