Материал: 1210
81
3.5 Линейные коды
Естественным способом систематизации построения корректирующих кодов является разделение кодовых символов на информационные, представляющие собой непосредственно элементы сообщения, и проверочные, функционально зависящие от информационных (полагаем та = тb). Блочный код длины n, содержащий К информационных и r n K проверочных символов, называют разделимым кодом (n, k). Избыточность разделимого кода r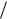 n .
n .
Условимся считать, что информационные символы расположены на первых К позициях кода, в проверочные — на последних r позициях блока и будем обозначать их соответственно a j , cv ,, где j 0, 1,..., K 1; v 0, 1,..., r 1.. Тогда
кодовая комбинация bn 1,..., b0 в случае разделимого кода может быть |
|
представлена как ak 1, ak 2 ,...,a0; |
cr 1,...,c0 . |
Разделимый код может быть задан без кодовой таблицы. Правило его построения полностью определяется заданием функциональной зависимости r-набора проверочных символов от К-набора информационных:
Подставляя в эту зависимость все возможные сочетания информационных символов, можно определить K mak кодовых комбинаций.
Разделимый (п, k) код с простым основанием тb, проверочные символы которого являются линейными комбинациями информационных символов по модулю этого основания называется линейным, или систематическим:
где — суммирование по модулю тb; vjv — произвольные mb -ичные числа. В дальнейшем рассматриваются лишь двоичные линейные коды, т.е.
Значение r соотношений для cv полностью определяет правило построения линейного кода. Эти соотношения в свою очередь определяются Kr двоич-
ными коэффициентами vj v . Так, линейный ход (15, 3) полностью определяется 3 2 6 двоичными числами. Если в качестве этих чисел выбрать, напри-
82
мер, v21 1, v11 1, v01 0, v20 1, v10 0, v00 1, то соотношения для cv примут вид
и, подставляя в них все возможные сочетания a j , получим все К = 23 = 8 кодовых комбинаций
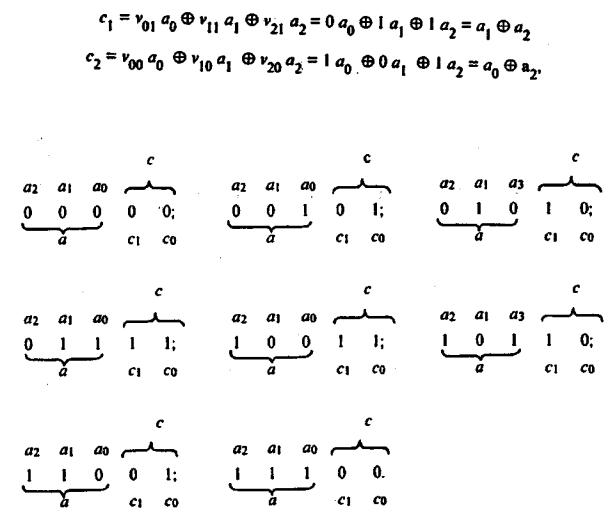
Построение кодера и декодера для линейных кодов. Работа кодера линей-
ного кода (рис. 3.1, а) тактируется во времени через некоторые выбранные интервалы t . В момент времени t1 , на выход кодера проходит символ а0 и
одновременно он записывается в ячейку 1 регистра сдвига. В момент времени t2 (через t после момента времени t1 ,) на выход кодера проходит символ а1и
одновременно записывается в
83
Рисунок 3.1 – Кодер и декодер для линейного кода:
1 - устройство вычисления синдрома, состоящее из четырех сумматоров по модулю 2
ячейку 1, а содержимое ячейки 1 переписывается в ячейку 2. В момент времени t3 (через t после t2) на выход кодера проходит символ a2 и записывается в ячейку 1, содержимое ячейки 1 записывается в ячейку 2, а содержимое ячейки 2 записывается в ячейку 3. Таким образом в момент времени t3 на выходе кодера имеются информационные символы а2, а1, а0 и в ячейках регистра сдвига соответственно записаны символы: ячейка 1 — а2, ячейка 2 — а1 и ячейка 3 — а0 . В момент времени t4 (через t после t3) сумматор 5 по модулю 2 образует проверочный символ c0, взяв содержимое ячеек 1 и 5 регистра сдвига, т.е. суммирует информационные символы a0 и a2. Результат суммирования подается на выход кодера. В момент времени t5 (через t после t4 ) аналогичную операцию выполняет сумматор 4 и на выход кодера проходит проверочный символ С1.
Таким образом, на выходе кодера будет получена кодовая комбинация
Задача декодирования состоит в проверке или восстановлении информационных символов с помощью проверочных символов. Суть заключается в проверке
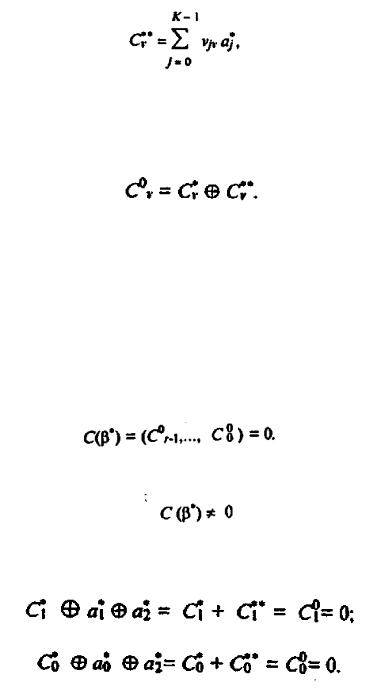
84
Сопоставляются принимаемые проверочные символы Cv (предполагается,
что эти символы передаются на приемную сторону без ошибок, а ошибки могут быть только в информационных символах) с проверочными символами
вычисленными на приемной стороне по принимаемым информационным символам a j .
Результат такой проверки может быть представлен в виде r-наборов элементов
Этот r -набор C Cr0 1, Cr0 2 ,...,C00 называют синдромом комбинации .
Очевидно, что число таких синдромов равно 2r .
Декодер для выбранного случая показан на рис. 3.1, б. Принцип работы декодера очевиден из рисунка, заметим только, что в декодер поступает комбинация C1C0a2a1a0 , т.е. в ячейку 1 в первый момент времени поступает информа-
ционный символ a0, далее с течением времени символ a0 перемещается по регистру сдвига и попадает в ячейку 5, а символ a1, находится в ячейке 4 и т.д. Если при передаче информации не произошло ошибки, то на выходе анализатора синдрома получим
Если же в одном из символов произошла ошибка, то на выходе анализатора синдрома зафиксируем
и с помощью проверки r -наборов находим место ошибки. Покажем это на примере, приведенном выше. Если ошибки нет, тогда соответствующие уравнения имеют вид
Возможны следующие варианты при появлении ошибки:
C10 0; C00 1. Анализ приведенных выражений показывает, что ошибочно
принят символ a , так как он не входит в другое уравнение, а там ошибки |
||||||||
|
|
0 |
|
|
|
|
|
|
нет; если C0 |
1; |
C0 |
0 , тогда ошибочно принят |
a ; если |
C0 |
1; |
C0 |
1. |
1 |
|
0 |
|
1 |
1 |
|
0 |
|
Ошибка фиксируется в обоих уравнениях, а в них входит символ a2 следовательно, именно этот символ принят ошибочно.
85
Таким образом при наличии двух проверочных символов однократная ошибка обнаруживается на любой позиции принятой кодовой комбинации.
3.6 Методы цифровой модуляции
Ранее указывалось, что методы теории кодирования наиболее примени-
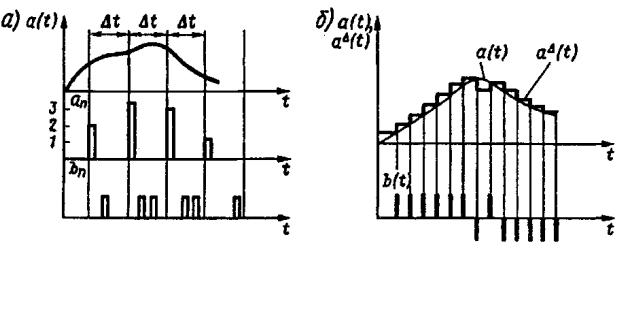
Рисунок 3.2 - Эпюры, поясняющие формирование сигнала с импульсно – кодовой и дельта - модуляцией
мы при осуществлении цифровой модуляции, поэтому, ознакомившись с элементами теории кодирования, опишем некоторые методы цифровой модуляции.
При цифровой модуляции, к которой относятся ИКМ и ДМ, исходное непрерывное сообщение предварительно дискретизируется и квантуется, затем кодируется и передается как дискретное сообщение.
Каждый отсчет в ИКМ кодируется в одну комбинацию представлением отображающей его ma - ичной цифры в двоичной mb 2 системе счисления по правилам, описанным в п. 3.2. Для полного использования кода число квантованных значений та = К обычно выбирают mbn 2n. Для речевых сооб-
щений чаще всего та = 32, 64, 128 или 256, что соответствует п = 5, 6, 7 или 8. Пример описанных преобразований для mа = 8, n = 3 показан на рис. 3.1, а. Полученные отсчетные значения в данном случае 2, 3, 3, 1, поэтому коды получаются 010, 011, 011, 001. Аналогично коды получаются при других значениях отсчетов сообщения в моменты времени t .
В системах с ИКМ применяют такие же способы манипуляций, как и в каналах с дискретными сообщениями, поэтому возможны следующие сочета ния ИКМ первичного сигнала с различными видами манипуляции несущего сигнала: ИКМ — АМн, ИКМ — ЧМн, ИКМ — ФМн. Соответственно общая структурная схема системы с ИКМ будет выглядеть, как показано на рис. 3.3,
а.