Материал: Введение в эконометрику10
Р
Таблица 3
1,02
-2,75
0,207
1,98
0,750
1,02
24,03
8
25,21
8,39
![]() при x=0, а значение x=0 далеко
отстоит от наблюдений фактора.
при x=0, а значение x=0 далеко
отстоит от наблюдений фактора.
2.2.3. Отображение линии регрессии на поле корреляции
Провести линию регрессии можно двумя способами:
Рассчитать таблицу значений
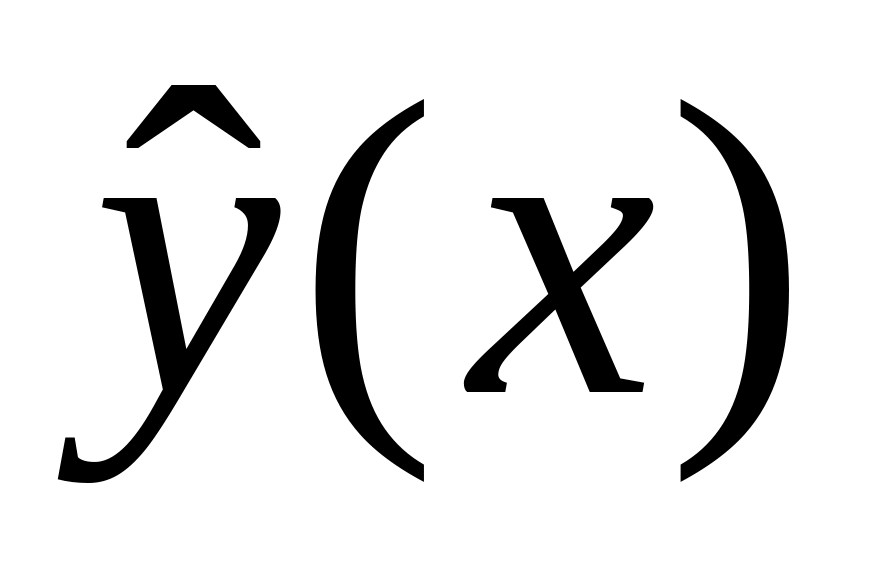 по
формуле (2), затем добавить полученный
ряд данных на диаграмму и отформатировать
его. Для добавления ряда данных на
диаграмму следует:
по
формуле (2), затем добавить полученный
ряд данных на диаграмму и отформатировать
его. Для добавления ряда данных на
диаграмму следует:
выделить диаграмму;
из главного меню выбрать команду Диаграмма / Исходные данные, в полученном окне выбрать вкладку Ряд;
нажать кнопку Добавить, указать название ряда и диапазоны ячеек, содержащих значения X и Y; подтвердить добавление ряда кнопкой ОК.
На диаграмме выделить ряд точек наблюдений (щелчком мыши), в контекстном меню выбрать пункт Добавить линию тренда. В полученном окне на вкладке Тип выбрать линейный тренд. На вкладке Параметры можно установить флажки для показа на диаграмме линии регрессии и значения коэффициента детерминации R2.
Линия регрессии для рассматриваемой задачи показана на рис. 3.
2.2.4. Прогнозирование значения отклика
Прогноз
осуществляется по формуле (2). Подставив
в (2) значения
=1,02,
=-2,75
при x=8м получим
![]() 5,38
усл. ед., при x=15м
12,49 усл. ед.
Также для прогноза используется функция
Тенденция.
5,38
усл. ед., при x=15м
12,49 усл. ед.
Также для прогноза используется функция
Тенденция.
2.2.5 Оценивание значимости уравнения регрессии
Абсолютное
значение выборочного коэффициента
корреляции вычислим по формуле, следующей
из (12а):
![]() .
Значение R2 берем из таблицы
3 результатов функции ЛИНЕЙН: R2=0,750,
|r|=0,866. Следовательно, связь между Y
и X достаточно тесная.
.
Значение R2 берем из таблицы
3 результатов функции ЛИНЕЙН: R2=0,750,
|r|=0,866. Следовательно, связь между Y
и X достаточно тесная.
Значения остаточной и регрессионной суммы получим из таблицы 3: Qe=8,39, QR=25,21. Так как QR>> Qe , то, скорее всего, уравнение регрессии значимо. Полную сумму квадратов вычислим по формуле (11): Q=33, 60. Смысл этих сумм был разъяснен в §1.5.
Проверим гипотезу о незначимости уравнения регрессии по критерию Фишера. Из таблицы 3: F=24,03. Квантиль F-распределения вычислим с помощью функции FРАСПОБР: f(0,05; 1; 8)=5,32. Таким образом, неравенство (14) выполнено, и уравнение значимо.
Проверим
гипотезу H о равенстве нулю коэффициента
регрессии. Из таблицы 3:
![]() 1,02,
1,02,
![]() =0,207.
По формуле (15в) определяем: Т=4,90.
Квантиль распределения Стьюдента
вычислим с помощью функции СТЬЮДРАСПОБР:
t(0,05; 8)=2,31. Получили, что неравенство
(16) выполнено. Следовательно, гипотезу
H следует отклонить, и коэффициент
регрессии значим.
=0,207.
По формуле (15в) определяем: Т=4,90.
Квантиль распределения Стьюдента
вычислим с помощью функции СТЬЮДРАСПОБР:
t(0,05; 8)=2,31. Получили, что неравенство
(16) выполнено. Следовательно, гипотезу
H следует отклонить, и коэффициент
регрессии значим.
3. Задание* на самостоятельную работу
Исследуется зависимость доли расходов на продовольственные товары в общих расходах (Y) от средней дневной заработной платы одного работающего (X) в семи территориях Уральского региона по данным, представленным в таблице 4. Провести анализ зависимости Y(X) по аналогии с §2.
Таблица 4. Зависимость доли расходов от средней заработной платы
Территория |
Y |
Х |
Удмуртская республика |
68,8 |
45,1 |
Свердловская область |
61,2 |
59,0 |
Башкортостан |
59,9 |
57,2 |
Челябинская область |
56,7 |
61,8 |
Пермская область |
55,0 |
58,8 |
Курганская область |
54,3 |
47,2 |
Оренбургская область |
49,3 |
55,2 |
Практическая работа №2. Интервальное оценивание параметров уравнения регресии
1. Теоретическая часть
Доверительный интервал коэффициента регрессии
Так как статистика (15б) имеет распределение Стьюдента с n-2 степенями свободы, то с вероятностью γ=1- справедливо соотношение:
![]() (17)
(17)
где t(;n-2) – квантиль распределения Стьюдента уровня 1-.
Из неравенства (17) получаем интервальную оценку коэффициента регрессии m доверительной вероятности (надежности) γ:
![]() (18)
(18)
Доверительный интервал дисперсии возмущений
Так как статистика S2 (см. формулу (8а)) имеет распределение хи-квадрат с n-2 степенями свободы, то с вероятностью γ=1- справедливо соотношение:
![]() ,
,
где 2(z; n-2) –квантиль уровня значимости 1-z распределения хи-квадрат.
Из последнего неравенства с учетом формулы (8а) получаем доверительный интервал дисперсии возмущений 2 надежности γ:
![]() . (19)
. (19)
1.3. Интервальное оценивание функции регрессии
Под функцией регрессии (см. §1.1) понимается f(x)≡MxY – условное математическое ожидание отклика Y при заданном значении x фактора. Из несмещенности оценок и и соотношения (2) следует:
![]() .
.
Можно
доказать (см., например, [5]), что для
выборочного среднего квадратичного
отклонения
![]() справедлива формула:
справедлива формула:
![]() , (20)
, (20)
а центрированная и нормированная статистика
![]()
распределена по Стьюденту с числом степеней свободы n-2. Отсюда следует, что с вероятностью γ=1- выполняется соотношение:
![]() ,
,
и доверительный интервал MxY надежности γ определяется неравенством:
![]() (21)
(21)
Из соотношений (20), (21), в частности, следует, что величина доверительного интервала функции регрессии зависит от значения объясняющей переменной х: чем больше отклонение х от среднего значения , тем шире доверительный интервал, и, соответственно, меньше точность оценивания.
1.4. Интервальное оценивание индивидуальных значений отклика
Соотношение (21) дает интервальную оценку среднего значения отклика при условии заданного x в рамках классической нормальной линейной регрессионной модели. Доверительный интервал индивидуального значения отклика y* (см., например, [5]) задается соотношением:
![]() , (22)
, (22)
где
![]() . (23)
. (23)
Решение типовой задачи в среде Excel
2.1. Постановка задачи
Продолжаем исследовать зависимость добычи угля на 1 рабочего (Y) от толщины угольного пласта (Х) (см. таблицу 1). Требуется:
Найти с надежностью γ=0,95 интервальные оценки коэффициента регрессии m и дисперсии 2 возмущений.
Построить 95-процентные доверительные интервалы линии регрессии и индивидуальных значений отклика.
Повторить п.п.1-2 для доверительной вероятности 0,9.
2.2. Выполнение задания в среде Excel
Доверительный интервал коэффициента регрессии определяем по формуле (18). В практической работе №1 уже нашли: 1,02, =0,207 (см. таблицу 3); t(0,05; 8)=2,31 (с помощью функции СТЬЮДРАСПОБР). Подставив эти значения в формулу (18), получаем 95-процентный доверительный интервал для коэффициента m: 0,538≤m≤1,495.
Для расчета интервальной оценки дисперсии возмущений в формулу (19) подставляем значение Qe=8,39 из таблицы 3. Квантили распределения хи-квадрат находим, применяя функцию ХИ2ОБР: 2(0,025;8)=17,53, 2(0,975;8)=2,18. Получаем 95-процентный доверительный интервал дисперсии возмущений: 0,479≤2≤3,85.
Расчеты
доверительных границ функции регрессии
и индивидуальных значений отклика
приведены в таблице 5. Рассматривался
немного более широкий диапазон x,
чем диапазон наблюдений. Значения
![]() вычислялись по формуле (2),
– по формуле (20), sy*
– по формуле (23). Значения
,
,
вычислялись по формуле (2),
– по формуле (20), sy*
– по формуле (23). Значения
,
,
![]() ,
s были взяты из таблицы 3. Через N
(V) обозначена нижняя (верхняя)
доверительная граница функции регрессии,
через N инд (V инд) –нижняя
(верхняя) доверительная граница
индивидуальных значений отклика. В
соответствии с соотношениями
(21), (22) использовались формулы:
,
s были взяты из таблицы 3. Через N
(V) обозначена нижняя (верхняя)
доверительная граница функции регрессии,
через N инд (V инд) –нижняя
(верхняя) доверительная граница
индивидуальных значений отклика. В
соответствии с соотношениями
(21), (22) использовались формулы:
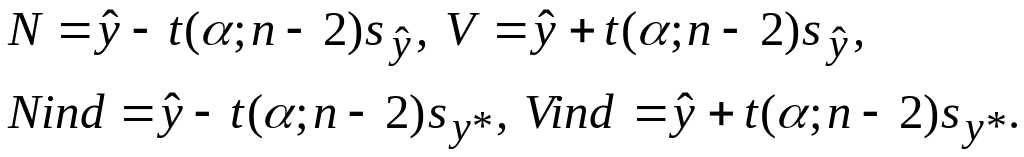
Графики доверительных границ, построенные по таблице 5, показаны на рис. 4.
Таблица 5. Расчеты доверительного интервала функции регрессии
x |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
|
3,34 |
4,36 |
5,38 |
6,39 |
7,41 |
8,43 |
9,44 |
10,46 |
11,48 |
|
0,78 |
0,59 |
0,43 |
0,33 |
0,35 |
0,46 |
0,63 |
0,81 |
1,01 |
N |
1,56 |
2,99 |
4,37 |
5,62 |
6,61 |
7,36 |
7,99 |
8,58 |
9,15 |
V |
5,13 |
5,73 |
6,38 |
7,16 |
8,21 |
9,50 |
10,89 |
12,34 |
13,80 |
sy* |
1,28 |
1,18 |
1,11 |
1,08 |
1,08 |
1,12 |
1,20 |
1,31 |
1,44 |
N ind |
0,38 |
1,63 |
2,81 |
3,91 |
4,92 |
5,83 |
6,67 |
7,44 |
8,16 |
V ind |
6,31 |
7,09 |
7,94 |
8,88 |
9,90 |
11,02 |
12,21 |
13,48 |
14,79 |
Для быстрого выполнения расчетов необходимо грамотно использовать абсолютные адреса ячеек Excel. Так, например, чтобы провести вычисления для двух значений доверительной вероятности (γ=0,95 и γ=0,9) достаточно:
записать значение γ=0,95 в ячейку листа Excel;
выполнить расчеты, ссылаясь на эту ячейку с абсолютным адресом;
изменить значение в ячейке с 0,95 на 0,9, чтобы получить результаты для γ=0,9 (в результате автоматического пересчета по формулам).
Задание на самостоятельную работу.
Продолжаем исследование зависимости доли расходов на продовольственные товары в общих расходах (Y) от средней дневной заработной платы одного работающего (X) в семи территориях Уральского региона (таблица 4). Необходимо провести расчеты доверительных интервалов параметров линейной регрессии по аналогии с §2.
Практическая работа №3. Решение задач эконометрики с применением Множественной линейной регрессии
1. Теоретическая часть
1.1. Уравнение множественной линейной регрессии
Пусть зависимая переменная Y связана с p (p>1) независимыми переменными X1, X2, …, Xp соотношением:
Y=0+ 1X1+ 2X2+…+ pXp+e, (24)
где 0, 1, 2,…, p – детерминированные величины, e – случайное возмущение.
Если математическое ожидание возмущения равно нулю (Mε=0), то соотношение (24) называется уравнением линейной множественной регрессии.
Пусть проведено n наблюдений величин X1, X2, …, Xp и Y. Значение отклика в i-ом наблюдении (i=1, 2, …, n) обозначим yi, значения факторов – xi1, xi2, …, xip, значение возмущения – ei. Тогда соотношение (24) примет вид:
yi =0+ 1xi1+ 2xi2+…+ pxip +ei, (24а)
Далее через Y будем обозначать вектор-столбец наблюдений отклика: Y=(y1, …, yn)′. Также обозначим: =(0, 1, , p)′ – вектор-столбец неизвестных коэффициентов регрессии, e=(e1, …, en)′ – вектор-столбец возмущений,
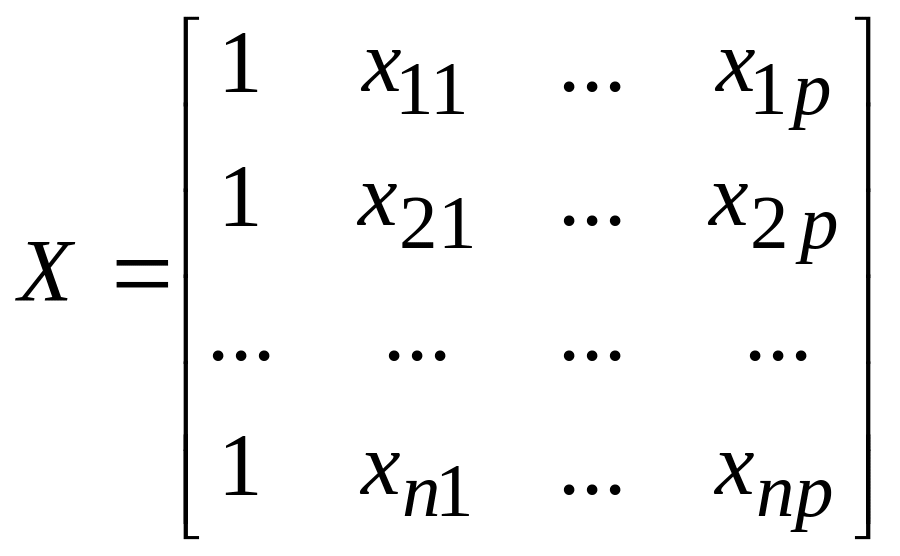
– матрица наблюдений независимых переменных размера n(p+1). Тогда соотношение (24а) можно записать в матричном виде:
Y=X+ε. (25)
Обратите внимание, что введение в матрицу X первого столбца из единиц равносильно умножению коэффициента 0 на фиктивную переменную x0, которая во всех наблюдениях принимает значение 1 (xi0=1, i=1, 2, …, n).
Требуется по наблюдениям найти в некотором смысле наилучшие оценки b=(b1, , bp)′ коэффициентов . Если оценки b получены, то оценку отклика по известному значению факторов x1, x2, ..., xp можно определить по формуле:
![]() . (26)
. (26)
1.2. МНК-оценки коэффициентов множественной линейной регрессии
В соответствии с МНК оценки коэффициентов регрессии определяются из условия минимума остаточной суммы квадратов Qe.