Материал: Потапов В.В. Решение задач биоинформатики при помощи веб - и интернет-сервисов
2Базы данных для биоинформатика: инструмент и результат
В1957 году Макс Перутц и Джон Кендрю получили первую детальную трехмерную структуру белка миоглобина. Тогда это был титанический труд, ведь в докомпьютерную эру все вычисления производились руками аспирантов. Объем информации был колоссальным — ведь в моделях хранятся координаты каждого атома!
Именно поэтому первыми биологическими базами были базы трехмерных структур, работать с ними «на бумаге» было очень и очень
Другой огромный объем информации появился в результате совершенствования технологий секвенирования геномов живых организмов, позволивших поставить этот процесс на поток. Методы
6

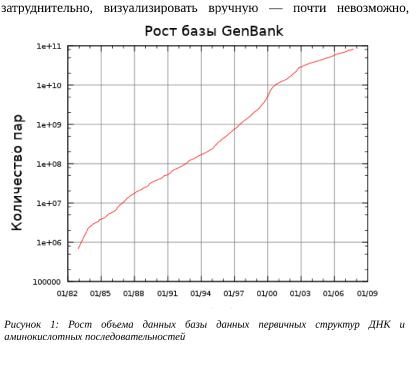
полимеразной цепной реакции (ПЦР) и автоматического определения нуклеотидных последовательностей сделали возможным получение генетической информации в не представимом ранее масштабе. Вспомним, один геном человека это три миллиарда пар оснований! Первый геном человека был расшифрован в 2000м году, и в настоящее время секвенаторы по всему миру выдают миллиарды букв генетического кода, который собирается в базах данных первичных структур и требует анализа и обработки. Объем этой информации удваивается, в среднем, каждые 18 месяцев!
Вопрос: Посмотрите на график увеличения объема данных GenBank. С чем связано ускорение роста базы в начале 21 века?
До изобретения быстрых методов секвенирования ДНК большинство исследований молекулярной эволюции проводились с использованием аминокислотных последовательностей. Определение аминокислотных последовательностей занимало много времени, и иногда было ошибочным. В настоящее время определить последовательность ДНК гораздо легче, чем последовательность белка, поэтому аминокислотные последовательности получают из нуклеотидных последовательностей, используя таблицы генетического кода.
Еще один источник «наборов букв» для баз данных - научные статьи. Общепринятый сегодня принцип ранжирования научной информации основан на индексе цитирования — на том, сколько раз статью процитировали в других статьях. Считается, что чем больше ссылаются на статью, тем информация в ней более востребована, тем выше рейтинг автора и журнала, в котором она издана. Понятно, что посчитать этот индекс вручную, перелопатив все статьи во всех научных журналах, практически нереально, и это одна из причин того, что научные публикации фиксируются в базах данных. Другая причина
— необходимость механизмов поиска, позволяющая не только найти необходимые сведения, но и избежать дублирования, обеспечить уникальность научной работы.
Каждая база данных содержит логически организованную структуру данных (так в библиотеке книги расположены по разделам и полкам). Любой записи этой базы обычно соответствует идентификатор. Как правило, в разных базах идентификаторы одной и той же сущности (например, биологической последовательности) разные, но бывает, что в нескольких базах принята одна и та же идентификация.
7

Идентификатор однозначно определяет запись базы, но не биологический объект, несколько исследований одного и того же объекта с чуть разными результатами будут иметь разные идентификаторы.
Биологические базы данных всегда содержат средства для поиска данных, в том числе для «нечеткого» поиска, т. е. эти средства могут ответить на вопрос «найти что-то наиболее похожее на...»
Современные биологические базы являются централизованными хранилищами информации, тысячи исследователей непрерывно пополняют их новыми данными, исправляют и дополняют. Информация в этих базах бывает неполна или даже содержит ошибки, поэтому приходится проверять её, сверяя множество источников, но научная деятельность в биоинформатике без этих баз просто невозможна.
Вопрос: Почему биологические базы данных содержат ошибки?
Сегодня биологических баз данных существует великое множество — базы данных ДНК, РНК, белков — их первичных, вторичных, третичных структур, базы данных статей по биологии и медицине и др. Чтоб оценить количество и разнообразие биологических баз данных можно, например, посмотреть их аннотированный каталог по адресу http://www.jcbi.ru/baza/
Крупнейшими и важнейшими биологическими базами данных являются:
•GenBank http://www.ncbi.nlm.nih.gov/genbank/ — база данных первичных структур ДНК и аминокислотных последовательностей.
• Protein Data Bank http://www.pdb.org - банк данных пространственных структур белков и нуклеиновых кислот
•PubMed http://www.ncbi.nlm.nih.gov/pubmed/ - база данных статей по биологии и медицине
8
Задание: Воспользовавшись поиском в Интернете или информацией из этого пособия, приведите еще три примера специализированных биологических баз.
2.1GenBank — база данных биологических последовательностей
Мировой архив последовательностей нуклеиновых кислот возник благодаря партнерству трех организаций — Национального центра биотехнологической информации (National Center for Biotechnology Information, USA), Библиотеки данных Европейского института биоинформатики (EMBL Data Library, UK) и Банка данных ДНК Японского национального института генетики (DNA Data Bank of Japan, National Institute of Genetics). Эти учреждения ежедневно обмениваются информацией.
В эти базы поступают данные о последовательностях ДНК и РНК, полученные из проектов исследований геномов, научных публикаций и заявок на патенты. Научные журналы требуют при публикации статьи внесения упоминаемых в ней новых последовательностей в базу данных, что обеспечивает ее наполнение.
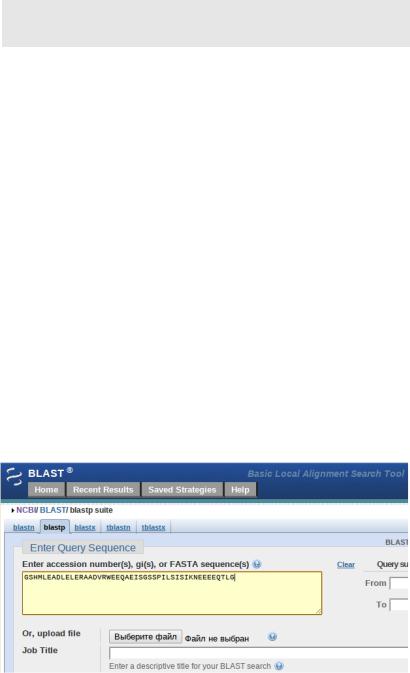
Системы поиска GenBank помогают решать одну из основных для биоинформатика задач — поиск информации о имеющейся у него биологической последовательности. Пусть у нас есть аминокислотная последовательность:
GSHMLEADLELERAADVRWEEQAEISGSSPILSITISEDGSMSIKNEE EEQTLG
Попробуем найти данные о ней в базе GenBank.
Рисунок 2: GenBank - поиск по аминокислотной последовательности

Можно перейти по ссылке, указанной в предыдущей главе, а можно просто набрать в поисковой строке google «NCBI», первой ссылкой будет искомая. Выберем на этом ресурсе BLAST (Basic Local Alignment Search Tool, средство для поиска локального выравнивания). Т. к. наша последовательность аминокислотная, а не нуклеотидная— выбираем поиск по белковой базе, protein blast и копируем в его поле ввода нашу последовательность, а потом нажимаем на кнопку BLAST. После нескольких секунд поиска, база данных выдаст нам результат — наша последовательность больше всего похожа на последовательность 2FOM Chain A, Dengue Virus Ns2bNS3 PROTEASE.
Щелкнув по ссылке, мы можем просмотреть более подробную информацию.
Вопрос: Что в приведенной информации является идентификатором записи базы данных?
2.2Protein Data Bank - банк данных трехмерных структур белков и нуклеиновых кислот
Protein Data Bank был основан еще в 1971 году Уолтером Гамильтоном в национальной лаборатории Брукхавена он наполняется данными о пространственной структуре белков и нуклеиновых кислот, полученными с помощью рентгеновской кристаллографии или ЯМР — спектроскопии, его также легко найти в google по названию.
Откроем сайт www.pdb.org и попробуем отыскать там информацию о нашей последовательности, ведь если она есть — значит для этой последовательности есть трехмерная структура! Введем идентификатор в строке поиска и получим полную информацию.
Наша последовательность принадлежит протеазе NS2b/NS3 вируса Денге, модель которой опубликованна в 2006 году. В базе указана даже ссылка на статью в PubMed с описанием получения этой модели. Существует также возможность покрутить трехмерную структуру модели прямо в браузере (щелкните View in JMOL), подобрать модели, похожие по аминокислотной последовательности или по структуре и многое, многое другое.
10