Материал: patrakeev_im_geoprostranstvennye_tekhnologii_v_modelirovanii
свыше 0,5 означает повышение требований к уровню определенности заключения об истинности Ω.
2. Вычислить µ Ω. Разыграть равномерную распределенную на интервале [0,1] случайную величину. Пусть полученное значение есть γ0. Тогда искомый результат определяется выражением (4.16). Здесь µ Ω рассматривается как вероятность истинности условия Ω.
В общем случае степень истинности оказывается не числом из отрезка [0,1], а нечетким числом. Логика, в которой степени истинности являются нечеткими числами, называется лингвистической. Иногда в литературе нечеткую логику называют многозначной, лингвистическую логику – нечеткой.
Лингвистическая степень истинности (ее значения – нечеткие числа) появляется, в частности, при оценке истинности одних нечетких высказываний относительно других. Пусть имеются высказывания
|
|
W : (X есть F) |
|
и |
Q : (X есть G) , |
|
где |
F, |
G – нечеткие подмножества U. |
Тогда истинность Q |
|||
относительно W вычисляется как степень соответствия G и F [60]: |
||||||
|
|
T (W, Q) |
= |
Uτ [0,1] |
μT (τ ) |
, |
где |
|
μT (τ ) |
= |
sup μF (u) , |
|
|
u: μ = μG (u)
Одним из элементов лингвистической логики является правило истинности модификации, которое заключается в следующем. Пусть известно, что лингвистическая степень истинности высказывания Q : (X есть G) равна Т. Тогда справедливо высказывание W : (X есть F),
|
F = U u U μF (τ ) , |
где |
μF (u) = μT (μG (u)) , |
u = μ −1 G (τ ),
В лингвистической логике вводятся операции над лингвистическими истинностями, определяемые на основе формул (4.12) – (4.15) по принципу обобщения. Операции позволяют вычислять лингвистическую степень истинности составных логических выражений.
136
Отдельное направление работ в лингвистической логике связано с изучением построения выводов из нечетких посылок, включающих нечеткие кванторы типа «редко», «очень часто» и т.п.
Рассмотрим правило логического вывода modus ponens в условиях нечеткой интерпретации. Допустим A, A*, B, B* представляют собой четыре нечетких высказывания (в литературе часто используется термин – утверждения); тогда обобщенное правило modus ponens будет читаться следующим образом: например, если x представляет собой лингвистическую переменную плотность населения, то y – лингвистическую переменную потенциал развития, A и A* представляют нечеткое высказывание «высокая плотность населения» и «очень высокая плотность населения»; B и B* соответственно, нечеткие высказывания – «высокий потенциал для развития и «очень высокий потенциал для развития», то можно сформулировать следующий логический вывод:
и «очень высокий потенциал для развития», то можно сформулировать следующий логический вывод:
Условие. Территория x имеет очень высокую плотность населения (A*). Импликация. Если территория x имеет высокую плотность населения (A), то данная территория y имеет высокий потенциал для развития (B). Вывод. Территория имеет x очень высокий потенциал для развития (B*).
Рассмотреное правило можно записать в виде формулы:
B*= (А → В) A* |
(4.17) |
Интуитивная простота нечеткой логики как методологии разрешения проблем гарантирует ее успешное использование в системах анализа информации. При этом происходит подключение человеческой интуиции и опыта оператора.
В отличие от традиционной математики, требующей на каждом шагу моделирования точных и однозначных формулировок закономерностей, нечеткая логика предлагает совершенно иной уровень мышления, благодаря которому творческий процесс моделирования происходит на наивысшем уровне абстракции, при котором постулируется лишь минимальный набор закономерностей.
Нечеткие числа, получаемые в результате «не вполне точных измерений», во многом аналогичны распределениям теории вероятностей, но свободны от присущих последних недостатков: малое количество пригодных к анализу функций распределения, необходимость их принудительной нормализации, соблюдение требований аддитивности, трудность обоснования адекватности математической абстракции для описания поведения фактических величин. При возрастании точности нечеткая логика приходит к стандартной, булевой. По сравнению с
137
вероятностным методом, нечеткий метод позволяет резко сократить объем производимых вычислений, что, в свою очередь, приводит к увеличению быстродействия нечетких систем.
4.2.2 Основные понятия нечеткого управления
Нечеткое управление представляет собой применение теории нечетких множеств и нечеткой логики в системах управления различного назначения. В настоящее время для многих приложений, связанных с управлением различными процессами и явлениями, необходимо построение модели рассматриваемого процесса или явления. Знание модели позволяет подобрать соответствующие параметры управления. Однако часто построение корректной модели представляет собой трудную проблему, требующую иногда введения различных упрощений. Применение теории нечетких множеств и нечеткой логики для управления процессами не предполагает знания моделей этих процессов. Следует только сформулировать правила поведения в форме нечетких условных суждений типа IF ... THEN.
Данная методология обеспечивает достаточно простой способ делать определенные выводы и предположения, основанные на расплывчатости, неоднозначности и неточности, зашумленности или полного отсутствия входной информации. Основная идея этой методологии заключается в том, чтобы в процесс управления сложной динамической системой включить человеческие знания и опыт.
Основу нечеткого управления составляет база правил. База правил, иногда называемая лингвистической моделью, представляет собой
множество нечетких правил R (k ) , k = 1, …, N, |
|
|
вида |
|
|
|
|
||||||||||||||||||||||
R (k ) : IF (x1 это A1k |
AND |
x2 |
это A 2k |
AND … AND |
xn |
это |
A nk |
) |
|||||||||||||||||||||
|
|
|
|
THEN (y1 это B1k AND y2 |
|
это B 2k |
AND … AND |
xm |
это |
A mk |
), |
||||||||||||||||||
где N – |
|
количество нечетких правил; |
|
|
|
|
|
|
|
|
|||||||||||||||||||
|
|
A ik |
|
– |
|
нечеткие множества, |
|
A ik X i |
|
R , i = 1, …, |
n ; |
|
|
|
|||||||||||||||
|
|
B kj |
|
– |
|
нечеткие множества, |
B kj Y j |
R , j = 1, …, |
m ; |
|
|
||||||||||||||||||
|
|
X i |
, |
|
|
i = 1, …., |
n – |
пространство входных переменных; |
|
|
|||||||||||||||||||
|
|
Y j |
, |
|
j = 1, …., |
m |
– |
пространство выходных переменных; |
|
||||||||||||||||||||
|
|
x1 , |
|
x2 ,…, |
|
|
xn |
– |
входные переменные лингвистической модели, |
||||||||||||||||||||
причем ( |
|
|
, |
|
|
|
,…, |
|
|
|
|
)T = x X |
× X × … |
× X ; |
|
|
|
|
|||||||||||
x |
x |
|
|
x |
|
|
|
|
|||||||||||||||||||||
1 |
|
|
|
2 |
|
|
|
n |
|
|
|
1 |
|
|
2 |
|
|
|
n |
|
|
|
|
||||||
|
|
y1 , y2 ,…, |
|
ym |
– |
выходные переменные лингвистической модели, |
|||||||||||||||||||||||
причем ( |
|
, |
|
|
|
,…, |
|
|
|
|
)T = y |
Y |
|
× Y |
|
× … × |
Y |
|
. |
|
|
|
|
||||||
y |
y |
2 |
|
y |
m |
1 |
2 |
m |
|
|
|
|
|||||||||||||||||
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||
138
Необходимо отметить, что нечеткие правила R (k ) , k = 1, …, N связаны между собою логическим оператором ИЛИ (OR). Кроме того, допустим, что выходы y1 , y2 ,…, ym взаимно независимы. Поэтому без утраты общности можно использовать нечеткие правила со скалярным выходом в форме:
R (k ) : IF (x |
это A k |
AND x |
2 |
это A k |
AND … AND |
x |
n |
это A k |
) (4.18) |
1 |
1 |
|
2 |
|
|
n |
|
THEN ( y это B k )
Каждое правило вида (4.17) состоит из части IF, которая называется посылкой (antectdent), и части THEN, называемой следствием (consequest). Посылка правила содержит набор условий, тогда как следствие содержит
вывод. Переменные ( |
|
, |
|
,…, |
|
)T и ( |
|
, |
|
|
,…, |
|
|
)T |
могут принимать |
x |
x |
x |
y |
y |
2 |
y |
m |
||||||||
|
1 |
|
2 |
|
n |
1 |
|
|
|
|
|
||||
как лингвистические |
(например «малый», «средний», «большой»), так и |
||||||||||||||
числовые значения. Обозначив |
|
|
|
|
|
|
|
|
|
|
|
||||
X = X1 × X2 × … × Xn,
A k =A 1k × A 1k × … × A kn ,
то правило (4.17) можно представить в виде нечеткой импликации: R (k ) : A k → B k , k = 1, … , N.
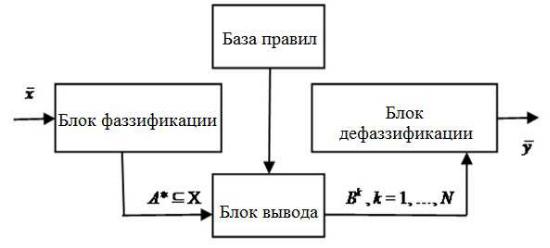
Типовая структура системы с нечетким управлением представлена на рис. 4.2. Как видно из рисунка, система состоит из нескольких компонентов: базы правил, рассмотренных выше, блока фаззификации (fazzification), блока выработки решения, блока дефаззификации.
Рис. 4.10 – Структура системы с нечетким управлением Система управления с нечеткой логикой оперирует нечеткими
множествами. Поэтому конкретное значение |
x |
= ( |
|
, |
|
,…, |
x |
)T |
X |
x |
x |
||||||||
1 |
|
2 |
|
n |
|
||||
входного параметра в системе с нечетким управлением подлежит операции
139

фаззификации, в результате которой значению x будет сопоставлено нечеткое множество A* X1 × X2 × … × Xn.
В системах управления с нечеткой логикой входные данные имеют точные и определенные значения. Эти входные данные будут преобразованы в «нечеткие» значения, которые будут характеризоваться функцией принадлежности нечеткого множества. На первом этапе в системах управления, основанных на нечеткой логике, выполняется процесс фаззификации (fuzzification process). Как правило, на этапе фаззификации создается универсальное пространство лингвистических переменных (иными словами область рассуждения) для которых определяются функции принадлежности, позволяющие преобразовать точные и определенные значения входных данных в нечеткий формат.
Например, в п. 4.2.1 рассмотрен подход, использующий лингвистические переменные и линейную функцию принадлежности для определения такой пространственной характеристики как протяженность градостроительной системы на основе использования точных значений плотности населения.
Процесс фаззификации позволяет создать три нечетких терма, а именно, урбанизированная территория, частично урбанизированная территория и не урбанизированная территория. Таким же образом можно описать такую особенность ландшафта как уклон, а именно как плоский, умеренный, крутой и очень крутой.
На втором этапе в системах управления, основанных на нечеткой логике, необходимо разработать базу правил системы нечеткого логического вывода, которая в литературе называется лингвистической моделью [57, 62]. Реализация нечеткого вывода основана на нечетких продукционных правилах. Поэтому рассмотрение формализма нечетких продукционных моделей приобретает самостоятельное значение. Нечеткие правила наиболее близки к логическим моделям, но что очень важно, они адекватно отражают знания экспертов конкретной предметной области.
Обычно логические модели представляют набор простых утверждений «ЕСЛИ-ТО», которые в обобщенной форме можно представить в виде:
|
(i): Q; P; A B; S,F,N , |
где (i) — |
имя нечеткой продукции; |
Q — сфера применения нечеткой продукции; |
|
Р — |
условие применимости ядра нечеткой продукции; |
140