Материал: patrakeev_im_geoprostranstvennye_tekhnologii_v_modelirovanii
используется линейная функция принадлежности, в соответствии с выражением 4.7:
|
|
|
ρ |
|
0− |
|
ρ |
|
|
ρxi , j |
< ρ0 |
|
|
|
|
x i |
|
0 |
|
|
|||||
μSurban |
|
|
|
, j |
|
|
ρ0 |
£ ρxi , j £ ρ1 (xi, j Î X ) |
|
|||
( xi, j |
) = |
|
|
|
|
|
|
(4.7) |
||||
|
ρ 1 |
− |
ρ |
|
|
|||||||
|
|
|
|
0 |
|
|
ρxi , j |
³ ρ1 |
|
|||
|
|
|
|
|
1 |
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
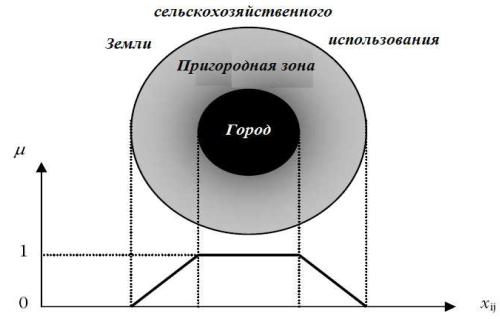
Используя данную функцию принадлежности, можно получить значение функции принадлежности, соответствующее заданному значению плотности населения.
Рассмотренный выше нечеткомножественный подход в определении урбанизированных территорий называется процессом фаззификации. Процесс фаззификации позволяет поставить в соответствие каждой ячейке ОС-пространства значение логико-лингвистических переменных, используя для этого рассмотренную выше функцию принадлежности (выражение 4.7).
Например, если плотность населения для единичного клеточного автомата (ячейки) ОС-пространства - меньше, чем нижний порог 
 , то клеточный автомат принимает значение 0. В этом случае состояние единичного клеточного автомата будет расцениваться как «не урбанизированная».
, то клеточный автомат принимает значение 0. В этом случае состояние единичного клеточного автомата будет расцениваться как «не урбанизированная».
Если плотность населения для единичного клеточного автомата (ячейки) ОС-пространства выше, чем верхний порог 

 , то в этом случае состояние единичного клеточного автомата будет расцениваться как «урбанизированная», а соответствующие клеточные автоматы принимают значение 1.
, то в этом случае состояние единичного клеточного автомата будет расцениваться как «урбанизированная», а соответствующие клеточные автоматы принимают значение 1.
Все другие единичные клеточные автоматы получают значение функции принадлежности в интервале [0;1], тем самым представляя степень урбанизации исследуемой территории. Состояния таких единичных клеточных автоматов можно отнести к «частично урбанизированному».
121
ρ0 |
ρ1 |
ρ1 |
ρ0 |
Рис. 4.6 – Иллюстрация нечеткомножественного подхода в определении урбанизированных территорий. Значение функции принадлежности µ определяет степень принадлежности каждой ячейки xi,j урбанизированной территории; 
 и
и 
 , соответственно, верхний и нижний пороги плотности населения, что и определяет разграничение территории
, соответственно, верхний и нижний пороги плотности населения, что и определяет разграничение территории
Такой подход позволяет моделировать непрерывный процесс перехода территории из состояния «не урбанизированная» к состоянию «урбанизированная», то есть моделировать процесс пространственного развития градостроительной системы.
4.2 Нечеткая логика в моделях функционально-пространственного развития градостроительных систем, основанное на однородных структурах
Для моделирования развития пространственной организации городской системы, которая тесным образом связана с социальной организацией общества, природно-географическими условиями, техническими возможностями, финансовыми ресурсами и целым рядом других факторов, и в известной степени зависима от них, целесообразно использовать формализмы теории нечетких множеств, которые позволяют моделировать плавное изменение свойств исследуемого объекта, а также неизвестные функциональные зависимости, выраженные в виде качественных связей.
122
В этом разделе представлена методология нечеткого управления, которая применяется при моделировании развития пространственной организации городской системы.
Так же как и нечеткое управление, основанное на двух важнейших понятиях – лингвистической переменной и нечеткой логике – эти два понятия рассматриваются первыми, а затем обсуждаются вопросы, связанные с применением нечеткого управления при моделировании развития пространственной организации городской системы, особенно в моделях, основанных на ОС-структурах.
4.2.1 Общие понятия о лингвистической переменной и нечеткой логике
«Под лингвистической переменной понимается такая переменная, значениями которой являются слова и словосочетания на некотором естественном или искусственном языке. С учетом нашего преклонения перед всем точным, строгим и количественным и нашего пренебрежения ко всему нечеткому, нестрогому и качественному неудивительным кажется приход цифровых компьютеров… эти компьютеры оказались весьма эффективными при работе с механистическими, т.е. неживыми системами, поведение которых определяется законами механики, физики, химии, электромагнетизма. К сожалению, этого нельзя сказать о гуманистических системах…» [51].
Далее профессор Л. Заде указывает, что «неэффективность компьютеров в работе с гуманистическими системами является выражением принципа несовместимости, согласно которому высокая точность несовместима с большой сложностью».
Поскольку слова в общем менее точны, чем числа, понятие лингвистической переменной дает возможность приближенно описывать явления, которые настолько сложны, что не поддаются описанию в общепринятых количественных терминах. В частности, нечеткое множество, представляющее собой ограничение, связанное со значениями лингвистической переменной, можно рассматривать как совокупную характеристику различных подклассов элементов универсального множества. В этом смысле роль нечетких множеств аналогична той роли, которую играют слова и предложения в естественном языке. Например, прилагательное красивый отражает комплекс характеристик внешности индивидуума. Это прилагательное можно также рассматривать как название нечеткого множества, представляющего собой ограничение,
123

обусловленное нечеткой переменной красивый. С этой точки зрения,
термины очень красивый, некрасивый, чрезвычайно красивый, вполне красивый и т. д. - названия нечетких множеств, образованных путем действия модификаторов очень, не, чрезвычайно, вполне и т. п. на нечеткое множество красивый. В сущности, эти нечеткие множества вместе с нечетким множеством красивый играют роль значений лингвистической переменной внешность.
Важным аспектом понятия лингвистической переменной является то, что эта переменная более высокого порядка, чем нечеткая переменная, в том смысле, что значениями лингвистической переменной являются нечеткие переменные. Например, значениями лингвистической переменной «Возраст» могут быть слова: молодой, немолодой, старый,
очень старый, немолодой и не старый, вполне старый и т. п. Иллюстрация рассматриваемой лингвистической переменной показана на рис. 4.7[51].
Каждое из перечисленных значений является названием нечеткой переменной. Если X – название нечеткой переменной, то ограничение, обусловленное этим названием, можно интерпретировать как смысл нечеткой переменной X. Так, нечеткая переменная старый, представляет собой нечеткое подмножество множества U = [1, 100] вида:
(старый) = {(u, µ старый(u) ) | u 









 }, (4.8)
}, (4.8)
где µ старый – функция принадлежности значения u лингвистической переменной старый, которая может быть представлена в виде следующего выражения:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
u [0,50] |
|
|
|
0 |
|
|
||
|
μ(u) = |
|
|
|
|
|
(4.9) |
|
|
|
|
−2 |
−1 |
||
|
|
u − 50 |
|
||||
|
|
1 |
+ |
|
|
|
u [50,100] |
|
|
||||||
|
|
|
5 |
|
|
||
|
|
|
|
|
|
|
|
Лингвистическая переменная характеризуется набором: |
|||||||
|
|
|
ЛП = (Ω, T(Ω), U, G, M) , |
||||
где Ω – |
название переменной; |
|
|
||||
T(Ω) – |
обозначает терм-множество переменной Ω, т.е. множество |
||||||
названий лингвистических значений переменной Ω, причем каждое из таких значений является нечеткой переменной X со значениями из универсального множества U с базовой переменной u;
124
|
|
U – |
универсальное множество U с базовой переменной u; |
|
|||||||||
|
|
G – |
синтаксическое правило (имеет обычно форму грамматики), |
||||||||||
порождающее названия X значений переменной Ω; |
|
|
|
||||||||||
|
M – |
семантическое правило, которое ставит в соответствие с каждой |
|||||||||||
нечеткой переменной X ее смысл M(X), т. е. нечеткое подмножество M(X) |
|||||||||||||
универсального множества U. |
|
|
|
|
|
|
|
||||||
|
|
Лингвистическая |
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
переменная |
|
|
ВОЗРАСТ |
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
Значения |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Очень |
|
Молодой |
|
|
Старый |
|
Очень |
|
||||
|
|
|
|
|
старый |
||||||||
|
молодой |
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||
1 |
0,8 |
0,6 |
1 |
0,8 |
0,6 |
0,6 |
0,7 |
0,8 |
0,9 |
0,7 |
0,8 |
1 |
|
0 |
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
100 |
Возраст |
|
|
|
Базовая |
переменная |
|
|
|
|
|
|
|
Рис. 4.7 – |
Иерархическая декомпозиция лингвистической переменной |
|
|||||||
|
|
|
|
|
«Возраст» |
|
|
|
|
|
Конкретное название X, порожденное синтаксическим правилом G, называется термом.
Терм, состоящий из одного слова или нескольких слов, всегда фигурирующих вместе друг с другом, называется атомарным термом. Терм, состоящий из одного или более атомарных термов, называется составным термом. Конкатенация некоторых компонент составного терма
является подтермом. Если X1, X2, .… - |
термы в T, то T можно представить в |
||||||
виде объединения: |
|
|
|
|
|
|
|
|
|
T = X1+ X2+… |
|
|
|
||
Если необходимо указать на то, что T был порожден грамматикой G, |
|||||||
обозначается как T (G). |
|
|
|
|
|
|
|
Кроме первичных термов лингвистическое значение может включать |
|||||||
в себя связки, такие, |
как и, |
или, |
…, |
ни |
и т.п.; |
отрицание |
не, такие |
неопределенности, как |
очень, |
более |
или |
менее, |
должным |
образом, |
|
125