Материал: Организация работ и приготовление сложных пюреобразных супов
1.3.2 Разработка алгоритма
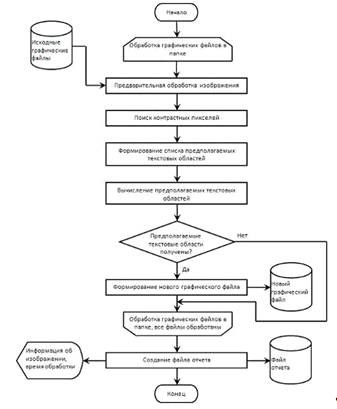
Рис. 1.25 Блок-схема алгоритма
В основу моего алгоритма был взят
существующий алгоритм «Быстрое и эффективное текстовое обнаружение»
разработанный в Университете Дипломированного специалиста китайской Академии
Наук, Пекин, Китай.
.3.2.1 Предварительная обработка изображений
Это главная функция, она включает в себя:
Нахождение размеров изображения (ширина, высота);
Перевод изображения в «Grayscale» режим;
Сжатие изображений (для тех, чей размер больше 600 пикселей по обеим сторонам);
Нахождение среднего отклонения интенсивности по всему изображению.
Перевод изображения в «Grayscale» режим так называемый «Серый» режим обязателен, это упрощает поиск «контрастных» пикселей и среднего отклонения интенсивности.
Изображение сжимается до размеров 600 пикселей по ширине или высоте, в зависимости от его пропорций.
Нахождение среднего отклонения
интенсивности пикселей необходимо для того чтобы выявить «особо контрастных
соседей» для каждого пикселя. Экспериментально вычислено, что именно среднее
значение отклонения дает более эффективный результат, нежели среднее
квадратичное.
.3.2.2 Поиск контрастных пикселей
Функция подсчитывает число «контрастных соседей» для каждого пикселя внутренней области рисунка (не лежащих на границе рисунка) и помещает результат в матрицу.
Эксперименты показали, что число 35 как пороговая разница в интенсивностях двух пикселей вполне работоспособно и очень эффективно.
Рассмотрим на примере:
08 02
56 48
30 14
У центрального «красного» пикселя
разница в интенсивности больше 35 с пятью «синими» пикселями, поэтому этому
пикселю присваиваем «контрастность» равную 5. В каждом квадратике, для каждого
пикселя, число его «особо контрастных соседей» не может превзойти 8.
.3.2.3 Формирование списка предполагаемых текстовых областей
Алгоритм предполагает, что размер символа в шрифте лежит в промежутке от 8 до 32 пикселей.
Это основная функция, так называемая «счетчик штрихованности», аналог «Штриховых Карт». Она вычисляет степень «штрихованности» квадратного участка изображения размером 24 на 24 пикселя.
Рассмотрим подробнее:
Эта функция в окошке 24 на 24 пикселя в матрице считает количество пикселей, у которых число «особо контрастных соседей» равно 3 или 6. Это самая важная часть. Число «особо контрастных соседей» может быть от 0 до 8, но нас интересует только 3 или 6. Это связано с тем, что символ - есть набор вертикальных, горизонтальных и диагональных палочек.
Рассмотрим на примере:
###00
###00
###00
###00
###00
###00
###00
Через «#» обозначена часть буквы. Большинство ее поверхностных пикселей имеют 3 «особо контрастных соседа», угловые пиксели имеют 5, но углов в символе мало, поэтому можно проигнорировать их.
Чем больше таких пикселей в окошке, тем больше его «штрихованность». Также только для 6 «особо контрастных соседей». Это когда символ толщиной в один пиксель.
Пример:
#########00
#0000000000
#0000000000
#0000000000
#0000000000
#0000000000
#0000000000
У всех пикселей этой буквы "Г" 6 «особо контрастных соседей», кроме двух конечных пикселей - у них 7. Но конечных пикселей намного меньше "внутренних", поэтому их тоже можно проигнорировать.
Далее результаты вычисления
количества «особо контрастных соседей» помещаются в массив, и вычисляется сумма
количества пикселей имеющих 3 и 6 «особо контрастных соседа». С помощью нее и
рассчитывается «штрихованность» окошка.
.3.2.4 Вычисление предполагаемых текстовых областей
Функция формирует список координат
прямоугольных текстоподобных областей изображения путем двойного вызова функции
«Формирование списка предполагаемых текстовых областей» и заполнения рабочей
матрицы теми пикселями, которые попали в квадраты, прошедшие критерий на
«текстоподобность».
.3.3 Практическая реализация алгоритма
Для практической реализации алгоритма был выбран язык «Python 2.6», так как он обладает достаточным и удобным набором средств для решения поставленной задачи. Реализация алгоритма на других языках, например «С++» более трудоемкая, но скорость работы программного модуля значительно возрастет. «Python» был выбран для демонстрации работоспособности модуля и алгоритма в рамках поставленной задачи.
Разработанный программный модуль
обрабатывает самые распространенные форматы графических файлов, такие как: '.bmp', '.jpg', '.jpeg', '.gif', '.png'. Модуль
берет графические файлы из папки, путь к которой прописан в коде программы и,
обрабатывая их, создает новые графический файлы с предполагаемыми текстовыми
областями в этой же папке. Имя новых файлов выглядит как «zz_имя_файла».
После того как все графические файлы в папке обработаны создается файл отчета в
виде html - страницы,
содержащей: входные фалы, результат обработки и описание файлов. Также в
главном окне программы появляется информация по мере обрабатывания файлов и
после завершения обработки (рисунок 1.26).
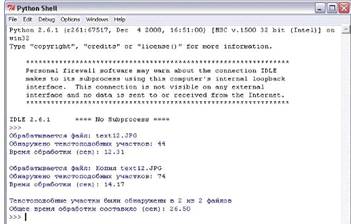
Рис. 1.26 Главное окно программы
В модуле есть параметры, которые отвечают за результат обработки и за определение потенциально опасных изображений, в которых может содержаться конфиденциальная информация, такие как:
Минимум для числа символов в «широком» участке текста (ns);
«Опасность» для числа всех участков (aw);
«Опасность» для числа всех "широких" участков (bw);
«Опасность» для общего числа символов во всех участках (cw).
Эти параметры можно менять в тексте программы для обеспечения различной степени фильтрации изображений и выявления потенциально «опасных». Фильтрация и выявление потенциально «опасных» изображений происходит по принципу:
Обнаружено текстоподобных участков: «Х» Из них содержащих не менее «ns» «условных» символов: «Y» .Общее число «условных» символов во всех участках: «Z», где X, Y, Z - значения, полученные в результате исследования изображения, сопоставляемые с параметрами.
Если X>aw и Y>bw - Да, то помечаем изображение как «Warning»;
Нет, то Если Z>cw - Да, помечаем изображение как «Warning»;
Нет, то изображение не помечается, где ns, аw, bw, cw - коэффициенты политики безопасности, которые вводим в коде.
Другими словами, сравниваем с заданным параметром «аw» количество «текстоподобных» участков, обнаруженных в изображении, также сравниваем количество «текстоподобных» участков содержащих «ns» «условных» символов с заданным параметром «bw». Если значения, найденные после исследования больше параметров, то на изображение ставится метка «Warning», если нет, то сравниваем общее количество «условных» символов в изображении с заданным числом «cw». Если общее количество «условных» символов в изображении больше заданного параметра, то на изображение ставится метка «Warning», если меньше, то анализируем следующие изображения.
Метка «Warning» необходима
для того чтобы отметить изображение как потенциально «опасное», которое может
содержать в себе конфиденциальную информацию. Для того чтобы система защиты,
оснащенная данным модулем, была оповещена об «опасном» графическом файле и
могла применить к нему определенные действия, например отправить на
исследование другими модулями этой системы.
.3.3.1 Пример работы программного модуля
Рассмотрим пример работы модуля на графическом файле:
Исходный файл:

Рис. 1.27 Пример исследуемого
изображения
В обработанном изображении выделяются предполагаемые текстовые блоки, остальное закрашивается серым фоном.
Файл после обработки:

Рис. 1.28 Результат исследования
При этом информация в отчете будет следующая:
Файл: text12.JPG;
Размеры растра: 816x891;
Имидж сжат до размеров: 600x655;
Обнаружено текстоподобных участков: 79;
Из них содержащих не менее 20 условных символов: 39;
Общее число условных символов во всех участках: 1534;
***WARNING***.
Это исследование было проведено со следующими параметрами в коде программы:
ns = 20;= 15;= 7;= 700.
Где:
Минимум для числа символов в "широком" участке текста (ns);
«Опасность» для числа всех участков (aw);
«Опасность» для числа всех "широких" участков (bw);
«Опасность» для общего числа символов во всех участках (cw).
Изображение после исследования
получила метку «WARNING» потому как данные, полученные
после исследования, не удовлетворяют критериям безопасности, установленным
нашими параметрами. Поэтому изображение признано потенциально «опасным», то
есть оно может содержать в себе конфиденциальную информацию.
.3.3.2 Особенности программного модуля
Параметр «cw» как общее число «условных» символов в изображении является глобальным параметром, который несет в себе возможность подстраховки от утечки информации, раскиданной по изображению небольшими текстовыми блоками, которые предыдущие условия могут пропустить, как не несущее в себе достаточного объема информации изображение.
Также в программном модуле есть другие особенности, которые позволяют снизить риск ложного обнаружения или наоборот - пропуска «опасного» графического файла.
Например:
(1) Если передаваемое изображение с потенциально «опасным» текстом повернуто на 90 градусов, исследуя его, текст естественно будет упущен, поэтому в модуле введена проверка изображения в перевернутом состоянии;
(2) Если «Штрихованность» предполагаемого текстового квадрата размером 24 на 24 пикселя очень большая и превосходит 3000, то это не будет являться текстовой область, так как таких плотных текстовых областей не бывает. В данной программе используется ограничение на плотность «Штрихованности» в интервале от 600 до 3000. Экспериментальным путем установлено что «Штрихованность» всех буквы и иероглифов в тексте попадает в промежуток от 600 до 3000;
(3) Сетка по своей структуре очень похожа не текст, от ее детектирования избавляемся с помощью пункта (2);
(4) Параметр «cw» как
глобальный параметр, который несет функцию проверки на большое количество
информации, раскиданной по изображению мелкими текстовыми блоками.
.3.3.3 Пример работы особенностей программного модуля
Рассмотрим пример работы особенностей программного модуля:
Исходный файл:
Как видно из рисунка 1.29 исследуемое изображение повернуто на 90 градусов и попадает под особенность (1).

Рис. 1.29 Пример исследуемого
изображения
Файл после обработки:
Как видно из рисунка 1.30
программный модуль повернул изображение на 90 градусов и исследовал его. К
сожалению, мы не можем отследить в какую сторону поворачивать изображение,
поэтому результатом может оказаться перевернутое изображение. На особенность
обнаружения текстовых областей это не влияет, так как текстовые блоки в любом
положении не меняют своих свойств.

Рис. 1.30 Результат исследования
Исходный файл:
Как видно из рисунка 1.31 на
изображении присутствует сетка и в ней текст. Оно попадает
под свойства (2) и (3).

Рис. 1.31 Пример исследуемого изображения
Файл после обработки:
Как видно из рисунка 1.32 текст был
успешно обнаружен, несмотря на наличие сетки, которая по своим свойствам очень
походит на текстовую область, а сама сетка была проигнорирована.

Рис. 1.32 Результат исследования
.3.3.4 Пример работы программного модуля в изображениях с различным текстом и сложным фоном
Такие изображения часто используются при распространении рекламы и спам-сообщений (рисунок 1.34):
Исходный
файл:

Рис. 1.33 Пример исследуемого
изображения
Файл после обработки:

Рис. 1.34 Результат исследования
Пример работы модуля на немного повернутом изображении со сложным фоном (рисунок 1.36):
Исходный файл:

Рис. 1.35 Пример исследуемого
изображения
Файл после обработки:

Рис. 1.36 Результат исследования
Пример работы модуля на изображении со сложным текстом (рисунок 1.38):
Исходный файл:

Рис. 1.37 Пример исследуемого изображения
Файл после обработки:
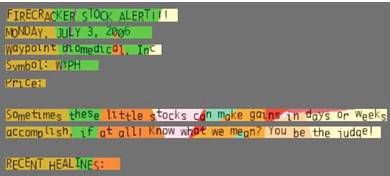
Рис. 1.38 Результат исследования
Пример работы модуля на сильно повернутом изображении со сложным текстом и фоном (рисунок 1.40):
Исходный файл:

Рис. 1.39 Пример исследуемого
изображения
Файл после обработки:

Рис. 1.40 Результат исследования
.3.3.5 Текст программы
Текст программы в Приложении 1.
.3.4 Вывод
Программный модуль разработан для
обнаружения блоков текста большого объема в изображениях, которые могут
содержать в себе конфиденциальную информацию. Также он хорошо работает в
изображениях со сложным текстом и сложным фоном. Одним из его достоинств
является то, что на обнаружение текста не влияет его размер или вид, в отличие
от существующих аналогичных решений (рисунок 1.37). Главные недостатки модуля
заключаются в его быстродействии и в том, что обнаружение текста будет
безуспешным, если его цвет слабо отличается от фона изображения, но
человеческий глаз может уловить его, или он повернут на достаточно сильный угол
по отношению к ориентации изображения, как показано на рисунке 1.39. Таким
образом, изучив все аспекты достоинств и недостатков разрабатываемого модуля,
можно сделать вывод, что для решения поставленной задачи он подходит, но для
обнаружения спама его следует усовершенствовать, что будет моим дальнейшим
исследованием.
1.4 Экспериментальное обоснование
результатов исследования
.4.1 Выбор метода верификации
Для проведения экспериментов был
выбран метод «ROC» кривых.
Понятие кривых «ROC» (Receiver Operating Characteristic -
функциональные характеристики приемника) взято из методологии анализа качества
приёма сигнала (Signal Detection Analysis). Теория,
стоящая за этим анализом, Theorie of Signal Detectability (TSD -
"Теория определимости сигнала"), хотя и происходит первоначально из
электроники и электротехники, но может также быть применена в любой области для
анализа полученных результатов (рисунок 1.41).
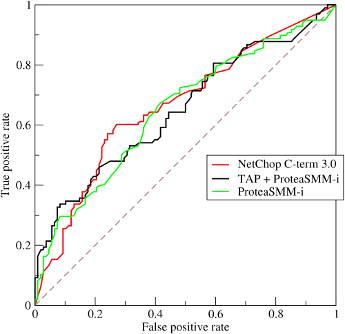
Рис. 1.41 Пример построения «ROC» кривых
Для построения «ROC» кривых необходимы значения:
true positive rate (TPR) - истинная норма; positive rate (FPR) - норма ошибочного допуска.