Материал: Организация работ и приготовление сложных пюреобразных супов
.3.1.1.4 Проверка наличия текста
Для каждого предполагаемого участка
текста идет проверка новым классификатором SVM, чтобы,
наконец, проверить является ли это истинной текстовой строкой.
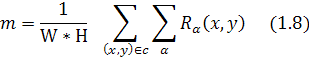
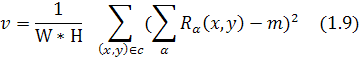
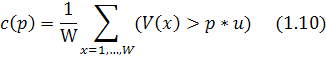
![]()
![]() {1.4, 1.0, 0.6, 0.2}
{1.4, 1.0, 0.6, 0.2}
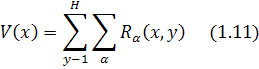
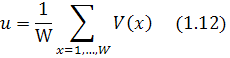
SVM
классификатор обучался на наборе данных из 200 текстовых строк и 160
нетекстовых строк. [15]

Рис. 1.15 Проверка наличия текста
На рисунке 1.15(b, c) видно
результат использования SVM классификатора.
.3.1.1.5 Экспериментальные результаты
На рисунке 1.16 показаны некоторые результаты испытания данного алгоритма.
Для количественных сравнений были взяты два показателя:
Скорость - среднее число обработанных изображений в секунду составила 12,9;
Точность - отношение правильно обнаруженных текстовых областей и имеющихся составила 91,1%.
Высокая точность заключается в том,
что использование двух простых классификаторов достигает лучшей
производительности, нежели использование одного сложного. [15]

Рис. 1.16 Результаты испытаний
Также существуют другие алгоритмы
обнаружения тестовых областей:
.3.1.2 Алгоритм «Быстрое и устойчивое текстовое обнаружение в изображениях и видео кадрах»
Этот алгоритм разработан в Институте Вычислительных Технологий китайской Академии Наук, Китай.
В основе алгоритма лежат четыре свойства:
(1) Плотное разнообразие интенсивности;
(2) Контраст между текстом и его фоном;
(3) Структурная информация;
(4) Свойство текстуры.
Чтобы классифицировать блок изображения в текстовый или не текстовый различными моделями классификаторов, в алгоритме предложена другая структура обнаружения. Она использует эти четыре свойства. В грубом обнаружении блоки текста получаются исходя из первого и второго свойств, предполагая, что у всех текстовых областей есть плотное разнообразие интенсивности и контраст с фоном. Затем эти текстовые области с помощью третьего свойства разделяются на текстовые строки, а свойство четыре используется, чтобы отличить текст от других нетекстовых шаблонов, плотное разнообразие интенсивности которых подобно тексту.
Мы рассматриваем четыре вида особенностей текстуры, чтобы идентифицировать текстовые строки.
Они включают:
Особенности небольшой волны;
Особенности гистограммы небольшой волны;
Особенности вхождения небольшой волны;
Особенности гистограммы счета.
Используется алгоритм выбора
особенности, чтобы найти эффективные особенности, и классификатор SVM, чтобы
выполнить текстовую/нетекстовую задачу классификации.
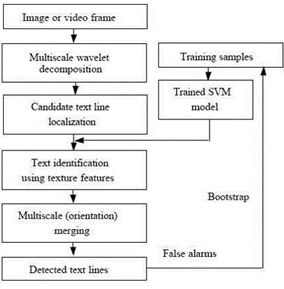
Рис. 1.17 Блок-схема алгоритма
По сравнению с существующими подходами основные преимущества предложенного алгоритма следующие:
(1) Быстрое обнаружение.
(2) Обнаружение текста с изменением размера шрифта.
(3) Комбинация особенностей текстуры. В работах исследователи используют традиционные особенности текстуры, чтобы отличить текст с нетекстовыми шаблонами. В этой работе четыре вида особенностей объединены, чтобы выполнить эту задачу. Используется передовой алгоритм выбора особенности, для нахождения степени важности различных особенностей.
(4) Действительно устойчивое
текстовое обнаружение. Метод может обнаружить текст в различных размерах и
цветах. Он также нечувствителен к текстовой ориентации строки при использовании
ориентированной области. Процедура классификации уменьшает ложные тревоги и
делает метод эффективным даже в сложном фоне. [16]
.3.1.2.1 Многошкальная декомпозиция небольшой волны
Преобразование небольшой волны
(рисунок 1.17) используется в этом алгоритме для хорошего определения
местоположения, вычисляется с помощью отдельного фильтра как:
![]()
![]()
![]()
![]()
(а) Оригинальное изображение с различным размером текста;
(b) После преобразования.

Рис. 1.17 Двухуровневое
преобразование волны
«H» и «G» - высоки и
низкие полосовые фильтры соответственно, ![]()
![]() местоположения в двух уровнях
декомпозиции,
местоположения в двух уровнях
декомпозиции, ![]()
![]() - многошкальное представление
глубины оригинального изображения.
- многошкальное представление
глубины оригинального изображения.
Текст различных размеров может быть
извлечен из различных уровней декомпозиции. [16]
.3.1.2.2 Обнаружение предполагаемых участков текста
Рассмотрим рисунок 1.18:
(a) Оригинальное изображение;
(b) Пиксели кандидата в первом масштабе;
(c) Горизонтальные предполагаемые текстовые области в первом уровне;
(d) Основанный
на плотности метод.

Рис 1.18 Обнаружение текстовых областей
кандидатов
Рассматривая разнообразие
интенсивности пикселей в текстовых областях (рисунок 1.18(b))
определяем особенность энергии небольшой волны пикселя ![]()
![]() ) в уровне n как:
) в уровне n как:
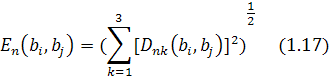
Для обнаружения пикселей
предполагаемой области, интегрируются коэффициенты небольшой волны в трех
высокочастотных подполосах «LH», «HL» и «HH».
Особенность энергии волны ![]()
![]() отражает разнообразие интенсивности
вокруг пикселя в уровне n. Пиксель будет являться пикселем
текста в уровне n если его энергия волны будет больше
чем динамический порог:
отражает разнообразие интенсивности
вокруг пикселя в уровне n. Пиксель будет являться пикселем
текста в уровне n если его энергия волны будет больше
чем динамический порог:
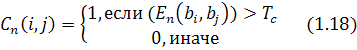
Где ![]()
![]() является картой пикселей
предполагаемых текстовых областей в уровне n как
показано на рисунке 1.18(b), пиксели кандидата спроектированы
в оригинальное изображение.
является картой пикселей
предполагаемых текстовых областей в уровне n как
показано на рисунке 1.18(b), пиксели кандидата спроектированы
в оригинальное изображение. ![]()
![]() - порог, определенный как:
- порог, определенный как:
![]()
Где ![]()
![]() - основной порог, значение которого
30.0, при котором текстовый пиксель может быть воспринят человеком.
- основной порог, значение которого
30.0, при котором текстовый пиксель может быть воспринят человеком. ![]()
![]() определен гистограммой энергии
(рисунок 1.19). Значение
определен гистограммой энергии
(рисунок 1.19). Значение ![]()
![]() может быть вычислено как:
может быть вычислено как:
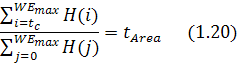
![]()
![]() гарантирует, что пиксели, которые
находятся в темной области гистограммы (рисунок 1.19) будут являться пикселями
предполагаемой текстовой области. Опытным путем найдено, что текстовые пиксели
в изображении редко превышают 15% всех пикселей этого изображения. Поэтому
гарантирует, что пиксели, которые
находятся в темной области гистограммы (рисунок 1.19) будут являться пикселями
предполагаемой текстовой области. Опытным путем найдено, что текстовые пиксели
в изображении редко превышают 15% всех пикселей этого изображения. Поэтому ![]()
![]() выбран как 0,15. Определение
выбран как 0,15. Определение ![]()
![]() таким образом может гарантировать,
что текстовые области будут найдены в изображениях с различным контрастом. Для
изображений с низким контрастом
таким образом может гарантировать,
что текстовые области будут найдены в изображениях с различным контрастом. Для
изображений с низким контрастом ![]()
![]() заменятся
заменятся ![]()
![]() , это гарантирует, что большинство
фоновых пикселей исключаться. С Инкрементом контраста и сложности изображения,
, это гарантирует, что большинство
фоновых пикселей исключаться. С Инкрементом контраста и сложности изображения, ![]()
![]() выбран и адаптивно вычислен. И чем
больше контраст в изображении, тем больше
выбран и адаптивно вычислен. И чем
больше контраст в изображении, тем больше ![]()
![]() должен быть. Пиксели,
контраст которых больше чем
должен быть. Пиксели,
контраст которых больше чем ![]()
![]() , являются пикселями текста. [16]
, являются пикселями текста. [16]
Рис. 1.19 Гистограмма энергии
небольшой волны изображения.
.3.1.2.3Основанный на плотности рост области
Текстовая область сделана из кластера текстовых пикселей. Плотные текстовые пиксели могут создать текстовую область, изолированные - искажения. Для того чтобы соединить текстовые пиксели (блоки) в текстовые области используется специальная морфологическая операция - выращивающий метод:
(1) Ищется начальный пиксель;
(2) Если начальный пиксель «Р» найден, создается новая область. После чего итерационно собираются непомеченные пиксели кандидатов и маркируются этой областью;
(3) Если есть еще начальные пиксели, то начинается с шага (1);
(4) Маркируются найденные области как текстовые, а оставшиеся пиксели объединяются в фон.
Рисунок 1.18(d) является примером тестовых областей, найденных предложенной методикой, основанной на плотности пикселей. [16]
1.3.1.2.4 Получение строк текста
Ориентация текстовых строк в области
кандидата может быть как показано на рисунке 1.20
Рис. 1.20 Различна ориентация
текстовых шаблонов
Много обнаруженных текстовых областей содержат многострочный текст. Специальная операция конфигурации проектирования используется, чтобы разделить эти области на текстовые строки. [16]
Текстовые и не текстовые области
имеют различную дисперсию интенсивностей и пространственные распределения
значений. Они
вычисляются по формулам:
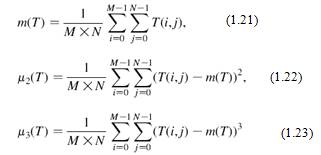
Особенности энергии, энтропии, инерции, местной однородности и корреляции в матрицах cо-вхождения вычислены соответственно как:
Далее все сводится опять же к обучению SVM
классификатора.

Рис. 1.21 Результаты испытаний данного алгоритма
.3.1.3 Штриховой фильтр
Так как основной алгоритм базируются на
штриховом фильтре, рассмотрим его более подробно.
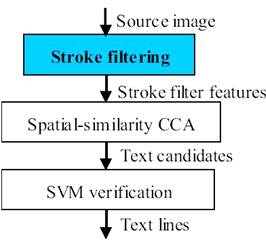
Рис. 1.22 Блок схема Штрихового фильтра
Штриховой фильтр (рисунок 1.22) предназначен для
текстовой локализации в видео и изображениях.
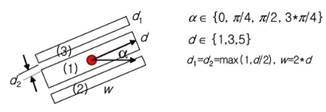
Рис. 1.23 Области для Штрихового фильтра
Для каждого пикселя в изображении вычисляется отклик штрихового фильтра (рисунок 1.23). Центральная точка обозначает пиксель изображения, вокруг которого есть три прямоугольных области. [17]
Штриховой отклик определятся по
формуле:
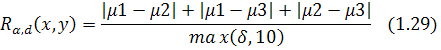
![]()
![]() - яркий штриховой отклик;
- яркий штриховой отклик;
![]()
![]() - темный штриховой отклик;
- темный штриховой отклик;
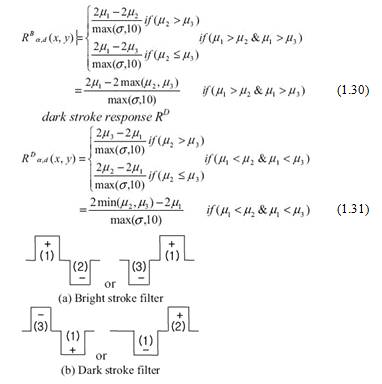
Рис. 1.24 Конфигурация Штрихового
фильтра
Конечная ориентация - масштаб
Штрихового фильтра определяются по формуле:
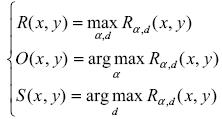
.3.1.4 Метод опорных векторов SVM
Так как во всех изученных алгоритмах используется так называемый SVM классификатор, основанный на методе опорных векторов, решено рассмотреть его более подробно.
Рассмотрим стандартную задачу
классификации - пространство Rn, два класса объектов - и
предположим, что классы линейно отделимы. Уравнение разделяющей гиперплоскости
имеет вид ![]()
![]() , где w - нормаль к
гиперплоскости. Полупространства, образуемые этой гиперплоскостью, задаются
неравенствами
, где w - нормаль к
гиперплоскости. Полупространства, образуемые этой гиперплоскостью, задаются
неравенствами ![]()
![]() и
и ![]()
![]() . Т.е. для всех точек одного класса
будет выполнено первое неравенство, а для точек другого класса - второе. Таким
образом, мы ищем решающую функцию в виде:
. Т.е. для всех точек одного класса
будет выполнено первое неравенство, а для точек другого класса - второе. Таким
образом, мы ищем решающую функцию в виде:
![]()
Ясно, что таких гиперплоскостей
может существовать бесконечно много. Чтобы понять, какая именно нужна нам,
вернемся к оценке риска классификации. В.Н. Вапником была доказана теорема, что
риск классификации может быть оценен в терминах эмпирического риска
(посчитанного на тренировочных данных) и слагаемого, учитывающего сложность
класса функций, из которого выбирается решение:

Минимизация риска классификации
эквивалентна решению следующей квадратичной задачи:
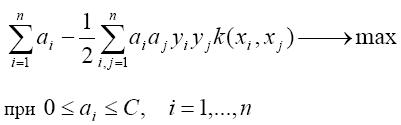
Размеры обучающей выборки следует оценивать как минимум несколькими сотнями тысяч. Это делает стандартные численные методы квадратичного программирования (метод Ньютона, прямодвойственные методы внутренней точки и другие) технически неприменимыми.
Недавно было предложено несколько интересных алгоритмов решения этой проблемы. Одни опираются на факт, что решение задачи не изменится, если из матрицы выкинуть строки и столбцы, соответствующие нулевым множителям Лагранжа. Другие предлагают решать подзадачи фиксированного размера, двигаясь в направлении наибольшего спуска целевой функции. Для решения задачи оптимизации, возникающей при обучении SVM, наиболее эффективным оказался метод, известный как Sequential Minimal Optimization (SMO).
Отличие SMO от других
алгоритмов заключается в том, что на каждом шаге он решает минимально возможную
подзадачу. Так как в задаче присутствует линейное ограничение, то минимальное
количество множителей Лагранжа для совместной оптимизации равно двум. А для
двух множителей задачу можно решить аналитически, не прибегая к численным
методам квадратичного программирования. Несмотря на то, что приходится решать
много подзадач, каждая из них решается настолько легко, что общее решение
задачи может быть найдено очень быстро. К тому же, при таком подходе нет
необходимости хранить даже часть Гессиана в памяти. Именно это алгоритм и был
выбран для решения задачи оптимизации, возникающей при обучении SVM. [9, 10]