Материал: Однофакторный дисперсионный анализ
Равенство нулю математического ожидания
случайной компоненты: ![]() = 0.
= 0.
Дисперсия случайной компоненты постоянна: ![]() .
.
Случайная компонента ![]() ,
а следовательно, и
,
а следовательно, и ![]() имеют нормальный
закон распределения.
имеют нормальный
закон распределения.
Число градаций факторов должно быть не менее трех.
Данная модель в зависимости от уровней фактора с помощью F-критерия Фишера позволяет проверить одну из нулевых гипотез.
При выполнении дисперсионного анализа для
связанных выборок возможна проверка еще одной нулевой гипотезы H0{и) -
индивидуальные различия между объектами наблюдения выражены не более, чем
различия, обусловленные случайными причинами.
Однофакторный дисперсионный анализ
(Практическая реализация в IBM SPSS Statistics 20)
Исследователя интересует вопрос, как изменяется определенный признак в разных условиях действия переменной (фактора). Изучается действие только одной переменной (фактора) на исследуемый признак. Мы уже рассмотрели пример из экономики теперь приведем пример из психологии например, как изменяется время решения задачи при разных условиях мотивации испытуемых (низкой, средней, высокой мотивации) или при разных способах предъявления задачи (устно, письменно или в виде текста с графиками и иллюстрациями), в разных условиях работы с задачей (в одиночестве, в комнате с преподавателем, в классе). В первом случае фактором является мотивация, во втором - степень наглядности, в третьем - фактор публичности.
В данном варианте метода влиянию каждой из градаций подвергаются разные выборки испытуемых. Градаций фактора должно быть не менее трех.
Пример 1. Три различные группы из шести
испытуемых получили списки из десяти слов. Первой группе слова предъявлялись с
низкой скоростью -1 слово в 5 секунд, второй группе со средней скоростью - 1
слово в 2 секунды, и третьей группе с большой скоростью - 1 слово в секунду.
Было предсказано, что показатели воспроизведения будут зависеть от скорости
предъявления слов (табл. 3) [3, с. 23].
Таблица 3
Количество воспроизведенных слов
|
|
Группа 1 низкая скорость |
Группа 2 средняя скорость |
Группа 3 высокая скорость |
|
1 |
8 |
7 |
4 |
|
2 |
7 |
8 |
5 |
|
3 |
9 |
5 |
3 |
|
4 |
5 |
4 |
6 |
|
5 |
6 |
6 |
2 |
|
6 |
8 |
7 |
4 |
|
суммы |
43 |
37 |
24 |
|
среднее |
7,17 |
6,17 |
4,00 |
Сформулируем гипотезы: различия в объеме воспроизведения слов между группами являются не более выраженными, чем случайные различия внутри каждой группы: Различия в объеме воспроизведения слов между группами являются более выраженными, чем случайные различия внутри каждой группы.
Запустим программу SPSS
Введем числовые значения в окне “данные”
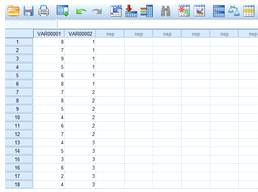
Рис. 1. Ввод значений в SPSS
В окне “Переменные” опишем все исходные данные, согласно условию
Задачи
![]()
Рисунок 2 Окно переменные
Для наглядности в графе метка опишем название таблиц
В графе “Значения” опишем номер каждой группы
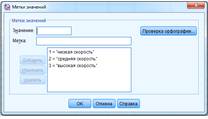
Рисунок 3 Метки значений
Все это делается для наглядности т.е. этими настройками можно пренебречь
В графе “шкала”, во втором столбце нужно поставить значение номинальная
В окне “данные” закажем однофакторный дисперсионный анализ с помощью меню «Анализ» Сравнение средних
Однофакторный дисперсионный анализ…
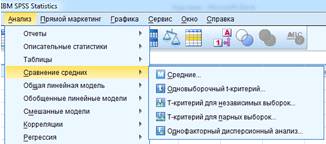
Рисунок 4 Функция Однофакторный дисперсионный
анализ
В открывшемся диалоговом окне “Однофакторный
дисперсионный анализ” выделим зависимую переменную и внесем ее в “список
зависимых”, а переменную фактор в окно “фактор”
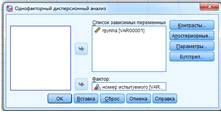
Рисунок 5 выделение списка зависимых и фактора
Настроим некоторые параметры для качественного
выведения данных
Рисунок 6 Параметры для качественного выведения
данных
Вычисления по выбранному алгоритму однофакторного дисперсионного анализа начинается после щелчка “ОК”
По окончанию вычислений в окне просмотра
выводятся результаты расчета
|
Описательные статистики |
||||||||
|
Группа |
||||||||
|
|
N |
Среднее |
Стд. Отклонение |
Стд. Ошибка |
95% доверительный интервал для среднего |
Минимум |
Максимум |
|
|
|
|
|
|
|
Нижняя граница |
Верхняя граница |
|
|
|
низкая скорость |
6 |
7,17 |
1,472 |
,601 |
5,62 |
8,71 |
5 |
9 |
|
средняя скорость |
6 |
6,17 |
1,472 |
,601 |
4,62 |
7,71 |
4 |
8 |
|
высокая скорость |
6 |
4,00 |
1,414 |
,577 |
2,52 |
5,48 |
2 |
6 |
|
Итого |
18 |
5,78 |
1,927 |
,454 |
4,82 |
2 |
9 |
|
Таблица 2. Описательные статистики
В таблице Описательные статистики приведены основные показатели по скоростям в группах и их итоговые значения
![]() - количество
наблюдений в каждой группе и суммарное
- количество
наблюдений в каждой группе и суммарное
Среднее - среднее арифметическое наблюдений в каждой группе и по всем группам вместе
Стд. Отклонение, Стд. Ошибка - среднее квадратическое отклонение и стандартные отклонения
% доверительный интервал для среднего - эти интервалы являются наиболее точными для каждой группы [5.62; 8,71] и по всем группам вместе [4,82; 6.74], нежели если взять интервалы ниже или выше этих границ.
Минимум, Максимум - минимальные и максимальные значения для каждой группы, которые услышали испытуемые
однофакторный дисперсионный случайный
|
Критерий однородности дисперсий |
|||
|
группа |
|||
|
Статистика Ливиня |
ст.св.1 |
ст.св.2 |
Знч. |
|
,089 |
2 |
15 |
,915 |
Критерий однородности Ливиня используется для
проверки дисперсий на гомогенность(однородность). В данном случае он
подтверждает незначимость различий между дисперсиями, поскольку значение =
0.915 т.е явно больше 0.05. Поэтому результаты полученные с помощью
дисперсионного анализа признаются корректными.
|
Однофакторный дисперсионный анализ |
|||||
|
группа |
|||||
|
|
Сумма квадратов |
ст.св. |
Средний квадрат |
F |
Знч. |
|
Между группами |
31,444 |
2 |
15,722 |
7,447 |
,006 |
|
Внутри групп |
31,667 |
15 |
2,111 |
|
|
|
Итого |
63,111 |
17 |
|
|
|
В таблице однофакторный дисперсионный анализ приведены результаты Однофакторного ДА
Сумма квадратов «между группами» представляет собой сумму квадратов разностей между общим средним значением и средними значениями в каждой группе с учетом весовых коэффициентов, равных числу объектов в группе
«Внутри групп» представляет собой сумму квадратов разностей среднего значения каждой группы и каждого значения этой группы
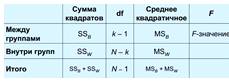
Столбец «ст.св.» содержит число степеней свободы V:
Межгрупповое (v=число групп - 1);
Внутригрупповое (v=число объектов - число групп - 1);
«средний квадрат» содержит отношение суммы квадратов к числу степеней свободы.
В столбце «F» приведено отношение среднего квадрата между группами к среднему квадрату внутри групп.
В столбце «знч» содержится значение вероятности
того, что наблюдаемые различия случайны
Таблица 4 Формулы
Графики средних
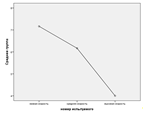
По графику видно, что он убывает. Так же можно
определить по таблице Fк k1=2, k2=15 табличное значение статистики равно 3,68.
По правилу если ![]() , то нулевая
гипотеза принимается, в противном случае принимается альтернативная гипотеза.
Для нашего примера
, то нулевая
гипотеза принимается, в противном случае принимается альтернативная гипотеза.
Для нашего примера ![]() (7.45>3.68),
следовательно принимается альтернативная гипотеза. Таким образом возвращаясь к
условию задачи можно сделать вывод нулевая гипотеза
(7.45>3.68),
следовательно принимается альтернативная гипотеза. Таким образом возвращаясь к
условию задачи можно сделать вывод нулевая гипотеза ![]() отклоняется
и принимается альтернативная
отклоняется
и принимается альтернативная ![]() : различия в объеме
воспроизведения слов между группами являются более выраженными, чем случайные
различия внутри каждой группы
: различия в объеме
воспроизведения слов между группами являются более выраженными, чем случайные
различия внутри каждой группы ![]() ). Т.о. скорость
предъявления слов влияет на объем их воспроизведения.
). Т.о. скорость
предъявления слов влияет на объем их воспроизведения.
Однофакторный дисперсионный анализ
(Практическая реализация в Microsoft Office
2013)
На этом же примере рассмотрим однофакторный дисперсионный анализ в Microsoft Office 2013
Решение задачи в Microsoft Excel
.Откроем Microsoft Excel.
. Введем данные из задачи для проведения
дисперсионного анализа
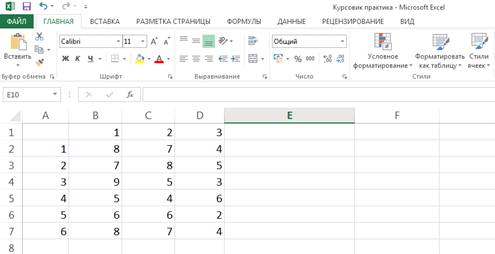
Рисунок 1. Запись данных в Excel
.Преобразуем данные в числовой формат. Для этого
на вкладке главное есть пункт “Формат” а в нем есть подпункт “Формат ячейки”.
На экранe появится окно Формат ячеек. Рис. 2 Выберем Числовой формат и
введенные данные преобразуются. Как показано на Рис.3
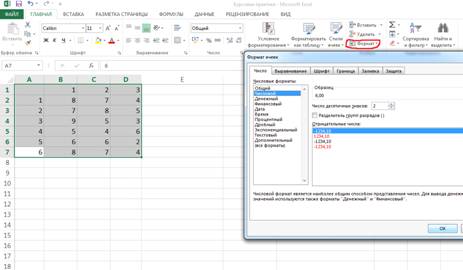
Рисунок 2 Преобразуем в числовой формат
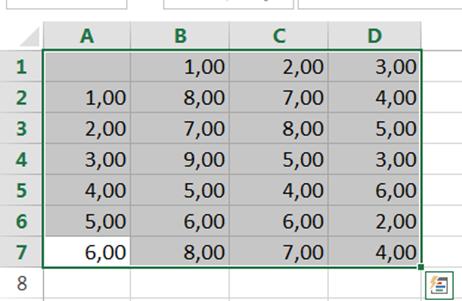
Рисунок 3 Результат после преобразование
.На вкладке данные есть пункт “анализ данных” кликнем по нему.
Выберем Однофакторный дисперсионный анализ
Рисунок 6 Анализ данных
. На экране появится окно Однофакторный
дисперсионный анализ для проведения дисперсионного анализа данных (Рис.7).
Произведем настройку параметров
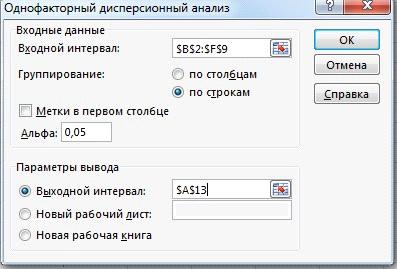
Рис. 7 Настройка параметров для однофакторного
анализа
. Щелкнем мышью в поле Входной интервал. Выделим диапазон ячеек B2::F9, данные в котором нужно проанализировать. В поле Входной интервал группы элементов управления Входные данные, появится указанный диапазон.
. Если в группе элементов управления Входные данные не установлен переключатель по строкам, то установите его, чтобы программа Ехcel воспринимала группы данных по строкам.
. Если нужно Установите флажок Метки в первой строке в группе элементов управления Входные данные, если первый столбец выделенного диапазона данных содержит названия строк.
. В поле ввода Альфа группы элементов управления Входные данные по умолчанию отображается величина 0,05, которая связана с вероятностью возникновения ошибки в дисперсионном анализе.
. Если в группе элементов управления Параметры вывода не установлен переключатель выходной интервал то установим его либо выберем переключатель новый рабочий лист, чтобы данные были перенесены на новый лист.
. Нажмем кнопку ОК, чтобы закрыть окно
Однофакторный дисперсионный анализ. Появятся результаты дисперсионного анализа
(Рис.8).
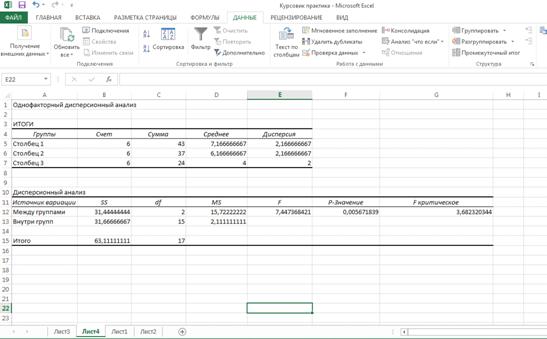
Рисунок 8 Вывод данных
В диапазоне ячеек А4:Е7 расположены результаты описательной статистики. В строке 4 находятся названия параметров, в строках 5 - 7 - статистические значения, вычисленные по партиям. В столбце «Счет» расположены количества измерений, в столбце «Сумма» - суммы величин, в столбце «Среднее» - средние арифметические значения, в столбце «Дисперсия» - дисперсии.
Полученные результаты показывают, что наибольшая средняя разрывная нагрузка в партии №1, а наибольшая дисперсия разрывной нагрузки -в партии №2, №1.
В диапазоне ячеек А10:G15 отображается информация, касающаяся существенности расхождений между группами данных. В строке 11 находятся названия параметров дисперсионного анализа, в строке 12 - результаты межгрупповой обработки, в строке 13 - результаты внутригрупповой обработки, а в строке 15 - суммы значений этих двух строк.
В столбце SS расположены величины варьирования, т.е. суммы квадратов по всем отклонениям. Варьирование, как и дисперсия, характеризует разброс данных.
В столбце df находятся значения чисел степеней свободы. Данные числа указывают на количество независимых отклонений, по которым будет вычисляться дисперсия. Например, межгрупповое число степеней свободы равняется разности количеству групп данных и единицы. Чем больше число степеней свободы, тем выше надежность дисперсионных параметров. Данные степеней свобод в таблице показывают, что для внутригрупповых результатов надежность выше, чем для межгрупповых параметров.
В столбце MS расположены величины дисперсии, которые определяются отношением варьирования и числа степеней свобод. Дисперсия характеризует степень разброса данных, но в отличие от величины варьирования, не имеет прямой тенденции увеличиваться с ростом числа степеней свобод. Из таблицы видно, что межгрупповая дисперсия значительно больше внутригрупповой дисперсии.
В столбце F находится, значение F-статистики, вычисляемое отношением межгрупповой и внутригрупповой дисперсий.
В столбце F критическое расположено F-критическое значение, рассчитываемое по числу степеней свободы и величине Альфа. F-статистика и F-критическое значение используют критерий Фишера-Снедекора.