Материал: ЛБ4 МОКр Исследование способов представления информации
Теория
информации предсказывает, что при
вероятности символа, скажем 0,4, ему в
идеале следует присвоить код длины 1,32
бита, поскольку
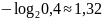 .
А метод Хаффмана присвоит этому символу
код длины 1 или 2 бита.
.
А метод Хаффмана присвоит этому символу
код длины 1 или 2 бита.
Арифметическое кодирование решает эту проблему путем присвоения кода всему, обычно большому передаваемому файлу, вместо кодирования отдельных символов (входным файлом может быть текст, изображение или данные любого вида). Алгоритм читает входной файл символ за символом и добавляет биты к сжатому файлу.
Чтобы
понять метод, полезно представлять себе
получающийся код в виде полуинтервала
 .
Таким образом, код «9746509» следует
интерпретировать как число 0,9746509, однако
часть 0, не будет включена в передаваемый
файл.
.
Таким образом, код «9746509» следует
интерпретировать как число 0,9746509, однако
часть 0, не будет включена в передаваемый
файл.
На первом этапе следует вычислить, или, по крайней мере, оценить частоты появления каждого символа алфавита. Наилучшего результата можно добиться, прочитав весь входной файл на первом проходе алгоритма сжатия, состоящего из двух проходов. Однако, если программа может получить хорошие оценки частот символов из другого источника, первый проход можно опустить.
Пример
1. Пусть
имеется три символа
,
и
с вероятностями
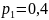 ,
,
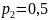 и
и
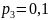 ,
соответственно. Интервал
делится между этими тремя символами на
части, пропорционально их вероятностям.
,
соответственно. Интервал
делится между этими тремя символами на
части, пропорционально их вероятностям.
Порядок следования подынтервалов не существенен. В нашем примере трем символам будут соответствовать подынтервалы , и .
Чтобы
закодировать строку «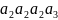 »,
начинаем преобразования с интервала
.
»,
начинаем преобразования с интервала
.
Первый символ сокращает его, отбросив 40% в начале и 10% в конце. Результатом будет интервал .
Второй символ сокращает интервал в той же пропорции до интервала . Третий символ переводит его в .
Наконец, символ отбрасывает от него 90% в начале, а конечную точку оставляет без изменения. Получается интервал .
Окончательным кодом этого метода будет служить любое число из этого интервала.
Здесь легко понять шаги алгоритма арифметического кодирования:
Задать «текущий интервал» [0,1).
Повторить следующие действия для каждого символа
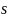 входного файла.
входного файла.Разделить текущий интервал на части пропорционально вероятностям каждого символа.
Выбрать подынтервал, соответствующий символу и назначить его новым текущим интервалом.
Когда весь входной файл будет обработан, выходом алгоритма объявляется любая точка, которая однозначно определяет текущий интервал (т.е. любая точка внутри этого интервала).
После каждого обработанного символа текущий интервал становиться все меньше и меньше, поэтому требуется все больше битов, чтобы выразить его, однако окончательным выходом алгоритма является единственное число, которое не является объединением индивидуальных кодов последовательности входных символов.
Среднюю длину кода можно найти, разделив размер выхода (в битах) на размер входа (в символах).
Пример 2. Продемонстрируем шаги сжатия для строки «SWISS MISS»
Символ |
Частота |
Вероятность |
Область |
S |
5 |
5/10=0.5 |
[0.5, 1.0) |
W |
1 |
1/10=0.1 |
[0.4, 0.5) |
I |
2 |
2/10=0.2 |
[0.2, 0.4) |
M |
1 |
1/10=0.1 |
[0.1, 0.2) |
пробел |
1 |
1/10=0.1 |
[0.0, 0,1) |
Процесс кодирования начинается инициализацией двух переменных Low и High и присвоением им значений 0 и 1 соответственно. Они определяют интервал [Low, High). По мере поступления и обработки символов, переменные Low и High начинают сближаться, уменьшая интервал.
С каждым поступившим символом переменные Low и High пересчитываются по правилу:
NewHigh = OldLow + Range×HighRange(X)
NewLow = OldLow + Range×LowRange(X)
где
Range
= OldHigh
– OldLow,
а HighRange(X)
и LowRange(X)
обозначают верхний и нижний конец
области символа
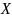 .
.
Символ |
|
Вычисление переменных Low и High |
S |
L H |
0.0+(1.0-0.0)×0.5=0.5 0.0+(1.0-0.0)×1.0=1.0 |
W |
L H |
0.5+(1.0-0.5)×0.4=0.70 0.5+(1.0-0.5)×0.5=0.75 |
I |
L H |
0.7+(0.75-0.70)×0.2=0.71 0.7+(0.75-0.70)×0.4=0.72 |
S |
L H |
0.71+(0.72-0.71)×0.5=0.715 0.71+(0.72-0.71)×1.0=0.72 |
S |
L H |
0.715+(0.72-0.715)×0.5=0.7175 0.715+(0.72-0.715)×1.0=0.72 |
Пробел |
L H |
0.7175+(0.72-0.7175)×0.0=0.7175 0.7175+(0.72-0.7175)×0.1=0.71775 |
M |
L H |
0.7175+(0.717525-0.7175)×0.1=0.717525 0.7175+(0.717525-0.7175)×0.2=0.717550 |
I |
L H |
0.717525+(0.717550-0.717525)×0.2=0.717530 0.717525+(0.717550-0.717525)×0.4=0.717535 |
S |
L H |
0.717530+(0.717535-0.717530)×0.5=0.7175325 0.717530+(0.717535-0.717530)×1.0=0.7175350 |
S |
L H |
0.7175325+(0.7175350-0.7175325)×0.5=0.71753375 0.7175325+(0.7175350-0.7175325)×1.0=0.71753500 |
Контрольные задания и вопросы
Дать определение информации и указать ее свойства.
Дать определение энтропии и указать ее свойства.
Какие возможности по сжатию текстов предоставлют их статистические свойства.
Рассчитать значение энтропии для русского и английского алфавитов.
Закодировать фразу, заданную преподавателем, с помощью метода равномерного кодирования.
Закодировать фразу, заданную преподавателем, с помощью метода кодирования по Шеннону-Фано.
Закодировать фразу, заданную преподавателем, с помощью метода Хаффмана.
Закодировать фразу, заданную преподавателем, с помощью метода арифметического кодирования.
Рекомендуемая литература
Сэломон Д. Сжатие данных, изображений и звука. М.: Техносфера, 2004. – 368 с.
Брандт З. Анализ данных. Статистические и вычислительные методы для научных работников и инженеров. – М.: Мир, ООО «Издательство ACT», 2003. – 686 с.
Вентцель Е. С., Овчаров Л.А. Прикладные задачи теории вероятностей. – М.: Радио и связь, 1983. – 416с.