Материал: ЛБ4 МОКр Исследование способов представления информации
Математические основы криптологии Лабораторная работа №4
Исследование способов представления информации в криптографических системах
Цель работы: исследовать обратимые сжимающие преобразования, используемые для предварительной обработки исходных текстов, и освоить методику сравнения их эффективности.
Задание:
Исследовать представления символов в кодировках ASCII и UNICODE, а также способы преобразования строк символов в числа.
Исследовать различные порядки следования байтов в машинных словах и зафиксировать их отличия для слов различного размера.
Провести кодирование информации с помощью метода равномерного кодирования. Подсчитать количество информации, необходимое для хранения текста, закодированного подобным образом.
Провести кодирование информации с помощью метода кодирования по Шеннону-Фано. Подсчитать количество информации, необходимое для хранения текста, закодированного подобным образом.
Провести кодирование информации с помощью метода кодирования по Хаффману. Подсчитать количество информации, необходимое для хранения текста, закодированного подобным образом. С помощью программы Huffman.exe проверить результаты и сделать выводы.
Исследовать возможности метода арифметического кодирования. Зафиксировать сложности реализации данного метода кодирования.
Обосновать методы декодирования информации для каждого из четырех видов кодирования.
Теория:
Код — правило (алгоритм) сопоставления каждому конкретному сообщению строго определённой комбинации символов (знаков) (или сигналов). Кодом также называется отдельная комбинация таких символов (знаков) — слово. Для различия этих терминов, код в последнем значении ещё называется кодовым словом.
Процесс преобразования сообщения в комбинацию символов в соответствии с кодом называется кодированием, процесс восстановления сообщения из комбинации символов называется декодированием. Для наглядного описания кодов используются кодовые деревья.
Представление байтов в машинных словах
Порядок байтов в информатике — метод записи байтов многобайтовых чисел.
В
общем случае, когда нужно компактно
записать число, большее 255 (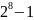 — максимальное целое число, записываемое
одним байтом (октетом)) необходимо
использовать несколько байтов. Число
— максимальное целое число, записываемое
одним байтом (октетом)) необходимо
использовать несколько байтов. Число
 факторизуется по основанию 256:
факторизуется по основанию 256:
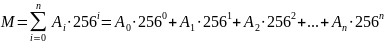
Набор
чисел
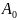 ,…,
,…,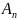 и является последовательностью байтов
для записи.
и является последовательностью байтов
для записи.
|
Порядок от младшего к старшему. Порядок от младшего к старшему или «остроконечный» (англ. little-endian): ,…, , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем, иногда, его называют интеловский порядок байтов (по названию фирмы-создателя архитектуры x86).
|
|
|
|
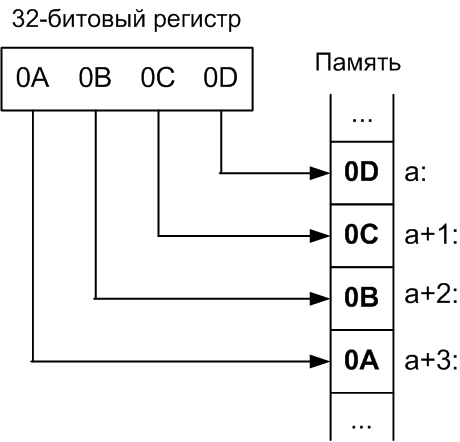
Порядок от старшего к младшему. Порядок от старшего к младшему или «тупоконечный» (англ. big-endian): ,…, , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байтов от старшего к младшему часто называют сетевым порядком следования байтов (англ. network byte order). |
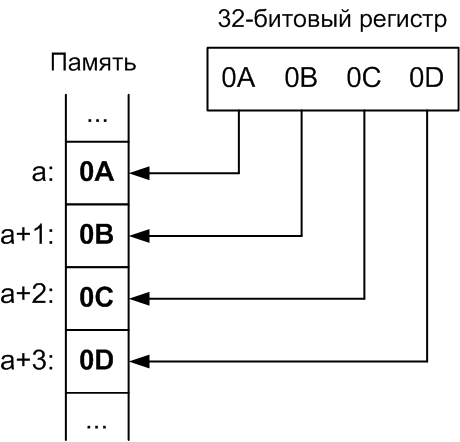
Этот порядок байтов используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байтов Motorola, Motorola byte order).
Порядок байтов от старшего к младшему применяется в многих форматах файлов – например, PNG.
Переключаемый порядок. Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байтов выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байтов операционной системы. Переключаемый порядок байтов иногда называют англ. bi-endian.
|
Смешанный порядок. Смешанный порядок байтов (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Производится факторизация числа на машинные слова, которые записываются в формате, естественном для данной архитектуры, но сами слова записываются в обратном порядке.
|
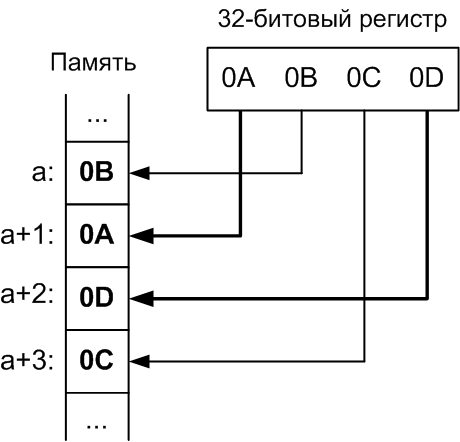
Классический пример middle-endian — представление 4-байтных целых чисел на 16-битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но 4-хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Сравнение. Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число 0x00000022, то прочитав его как int16 (два байта) мы получим число 0x0022, прочитав один байт — число 0x22.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байтов памяти при отладке (последовательность байтов (33, 44, 55, 12) на самом деле значит 0x12554433, для big-endian эта последовательность (33, 44, 55, 12) читалась бы «естественным» для арабской записи чисел образом: 0x33445512). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байтов в слове — обычный для данной архитектуры.
Кодирование символов в информационных системах
На сегодняшний день используются две основные системы для представления символьной информации в вычислительных машинах: это системы ASCII и UNICODE. Они используются совместно, не конфликтуя, а дополняя друг друга в практических задачах.
ASCII
ASCII (англ. American Standard Code for Information Interchange — американский стандартный код для обмена информацией; по-американски произносится [э́ски], тогда как в Великобритании чаще произносится [а́ски]; по-русски также произносится [а́ски]).
ASCII представляет собой 7-битную кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов. В компьютерах обычно используют 8-битные расширения ASCII.
|
.0 |
.1 |
.2 |
.3 |
.4 |
.5 |
.6 |
.7 |
.8 |
.9 |
.A |
.B |
.C |
.D |
.E |
.F |
0. |
NUL |
SOH |
STX |
ETX |
EOT |
ENQ |
ACK |
BEL |
BS |
TAB |
LF |
VT |
FF |
CR |
SO |
SI |
1. |
DLE |
DC1 |
DC2 |
DC3 |
DC4 |
NAK |
SYN |
ETB |
CAN |
EM |
SUB |
ESC |
FS |
GS |
RS |
US |
2. |
|
! |
" |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
— |
. |
/ |
3. |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
4. |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
5. |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\ |
] |
^ |
_ |
6. |
` |
a |
b |
c |
d |
e |
f |
g |
h |
i |
j |
k |
l |
m |
n |
o |
7. |
p |
q |
r |
s |
t |
u |
v |
w |
x |
y |
z |
{ |
| |
} |
~ |
DEL |
Национальные варианты ASCII. Стандарт ISO 646 (ECMA-6) предусматривает возможность размещения национальных символов на месте @ [ \ ] ^ ` { | } ~. В дополнение к этому, на месте # может быть размещён £, а на месте $ — ¤. Такая система хорошо подходит для европейских языков, где нужны лишь несколько дополнительных символов. Вариант ASCII без национальных символов называется US-ASCII, или «International Reference Version».
Для некоторых языков с нелатинской письменностью (русского, греческого, арабского, иврита) существовали более радикальные модификации ASCII. Одним из вариантов был отказ от строчных латинских букв — на их месте размещались национальные символы (для русского и греческого — только заглавные буквы). Другой вариант — переключение между US-ASCII и национальным вариантом «на лету» с помощью символов SO (Shift Out) и SI (Shift In) — в этом случае в национальном варианте можно полностью устранить латинские буквы и занять всё пространство под свои символы.
Впоследствии оказалось удобнее использовать 8-битные кодировки (кодовые страницы), где нижнюю половину кодовой таблицы (0—127) занимают символы US-ASCII, а верхнюю (128—255) — дополнительные символы, включая набор национальных символов. В UNICODE первые 128 символов тоже совпадают с соответствующими символами US-ASCII.
Верхняя половина таблицы в настоящее время активно используется для представления кириллических символов, и её вариации (КОИ-8, Windows-1251 и другие) доставляют основные проблемы с кодировками.
Кириллица
КОИ-7 — семибитная кодировка для русского языка, основанная на ASCII. КОИ-7 описана вместе с КОИ-8 в ГОСТ 19768-74 (сейчас недействителен). КОИ-7 включает в себя 3 «набора» — Н0, Н1, Н2. Н0 — это просто US-ASCII; в Н1 все латинские буквы заменены на русские; в Н2 заглавные латинские буквы оставлены, а строчные заменены на заглавные русские (наличие только заглавных букв в Н2 не создавало особых проблем, поскольку до начала 90-х гг. существовала традиция использовать в текстах программ только заглавные буквы; большинство печатающих устройств также могло печатать только заглавные буквы). На практике использовался либо набор Н2 сам по себе, либо Н0/Н1 с переключением.
CP866. «Альтернативная кодировка» – основанная на CP437 кодовая страница, где все специфические европейские символы во второй половине заменены на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портит вид программ, использующих для работы текстовые окна, а также обеспечивает использование в них символов кириллицы.
Исторически существовало много вариантов альтернативной кодировки, но все различия касаются только области 0xF0 — 0xFF (240—255). Использовались всевозможные русификаторы-самоделки, писавшиеся независимо частными программистами, распространяясь по знакомству и через редкие компьютерные центры.
Окончательным стандартом стала кодировка IBM CP866, поддержка которой была добавлена в MS-DOS версии 6.22. В этой кодировке записываются имена файлов в системе FAT (и короткие имена в VFAT). Поныне является популярной стандартной кодировкой Microsoft в среде DOS и OS/2, используется в консоли русифицированных систем семейства Windows NT. Вне среды MS-DOS в Microsoft Windows заменена стандартной кодировкой CP1251, а в операционных системах Windows NT и следующих за ней (Windows 2000, Windows XP, Windows Server 2003, Windows Vista, Windows Server 2008) – кодировкой UNICODE.
Windows CP1251. Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990-1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»).
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UNICODE
Юнико́д, или Унико́д (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.), объединяющей крупнейшие IT-корпорации. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становятся ненужными кодовые страницы.
Стандарт состоит из двух основных разделов: универсальный набор символов (UCS, Universal Character Set) и семейство кодировок (UTF, Unicode Transformation Format). Универсальный набор символов задаёт однозначное соответствие символов кодам – элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.