Материал: ЛБ4 МОКр Исследование способов представления информации
Способы представления. Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
UTF-8. UTF-8 – это представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байтов (на деле, только до 4 байт, поскольку в Юникоде нет символов с кодом больше 10FFFF и вводить их в будущем не собираются), в которых первый байт всегда имеет вид 11xxxxxx, а остальные – 10xxxxxx.
UTF-16
— один из способов кодирования символов
из Unicode в виде последовательности
16-битных слов. Символы с кодами меньше
0x10000 (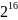 )
представляются как есть, а символы с
кодами 0x10000-0x10FFFE – в виде последовательности
двух 16-битных слов, первое из которых
лежит в диапазоне 0xD800-0xDBFF, а второе –
0xDC00-0xDFFF. Легко видеть, что имеется как
раз
)
представляются как есть, а символы с
кодами 0x10000-0x10FFFE – в виде последовательности
двух 16-битных слов, первое из которых
лежит в диапазоне 0xD800-0xDBFF, а второе –
0xDC00-0xDFFF. Легко видеть, что имеется как
раз
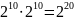 таких комбинаций.
таких комбинаций.
В потоке данных UTF-16 старший байт может записываться либо перед младшим (UTF-16 Big Endian), либо после младшего (UTF-16 Little Endian). Иногда кодировку Юникода Big Endian (UTF-16BE) называют Юникодом с обратным порядком байтов. Аналогично существует два варианта четырёхбайтной кодировки – UTF-32BE и UTF-32LE.
Способы кодирования информации
Равномерное
кодирование.
Для алфавита с
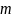 символами используются кодовые слова
с длиной
символами используются кодовые слова
с длиной
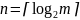 .
В этом случае неиспользованными остаются
.
В этом случае неиспользованными остаются
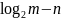 кодовых слов, а остальным проставляются
в соответствие символы первичного
алфавита.
кодовых слов, а остальным проставляются
в соответствие символы первичного
алфавита.
Коды переменной длины. Первое правило построения кодов с переменной длиной вполне очевидно. Короткие коды следует присваивать часто встречающимся символам, а длинные – редко встречающимся. Однако есть другая проблема. Эти коды нужно назначать так, чтобы их было возможно декодировать однозначно, а не двусмысленно. Рассмотрим пример.
Пусть
имеются четыре символа
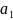 ,
,
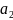 ,
,
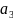 и
и
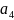 .
Если они появляются в последовательности
данных с равной вероятностью (=0.25 каждая),
то им просто присвоим четыре двухбитовых
кода 00, 01, 10 и 11. Все вероятности равны,
и поэтому коды переменной длины не
сожмут эти данные. Для каждого символа
с коротким кодом найдется символ с
длинным кодом и среднее число битов на
символ будет не меньше 2. Избыточность
данных с равновероятными символами
равна нулю, и строку таких символов
невозможно сжать с помощью кодов
переменной длины (или любым иным методом).
.
Если они появляются в последовательности
данных с равной вероятностью (=0.25 каждая),
то им просто присвоим четыре двухбитовых
кода 00, 01, 10 и 11. Все вероятности равны,
и поэтому коды переменной длины не
сожмут эти данные. Для каждого символа
с коротким кодом найдется символ с
длинным кодом и среднее число битов на
символ будет не меньше 2. Избыточность
данных с равновероятными символами
равна нулю, и строку таких символов
невозможно сжать с помощью кодов
переменной длины (или любым иным методом).
Символ |
Вероятность |
Code1 |
Code2 |
|
0.49 |
1 |
1 |
|
0.25 |
01 |
01 |
|
0.25 |
010 |
000 |
|
0.01 |
001 |
001 |
Предположим теперь, что эти четыре символа появляются с разными вероятностями, указанными в таблице, т.е. появляется в строке данных в среднем почти в половине случаев, и имеют равные вероятности, а возникает крайне редко. В этом случае имеется избыточность, которую можно удалить с помощью переменных кодов и сжать данные так, что потребуется меньше 2 битов на символ. На самом деле, теория информации говорит нам о том, что наименьшее число требуемых битов на символ в среднем равно 1.57, т.е., энтропии этого множества символов.
В
таблице предложен код Code1,
который присваивает самому часто
встречающемуся символу самый короткий
код. Если закодировать множество символов
с помощью Code1,
то среднее число битов на символ будет
равно
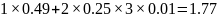 .
Это число весьма близко к теоретическому
минимуму. Рассмотрим последовательность
из 20 символов
.
Это число весьма близко к теоретическому
минимуму. Рассмотрим последовательность
из 20 символов
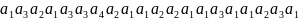 ,
,
в которой четыре символа появляются, примерно, с указанными частотами. Этой строке будет соответствовать кодовая строка кода Code1 длины 37 битов
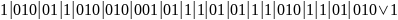 ,
,
которая для удобства разделена черточками. Здесь требуется 37 битов, чтобы закодировать 20 символов, т.е. в среднем 1.85 битов на символ, что не слишком отличается от вычисленной ранее средней величины (строка является короткой, и для того, чтобы получить результат, близкий к теоретическому, необходимо взять входной файл размером хотя бы несколько тысяч символов).
Однако,
если теперь декодировать эту двоичную
последовательность, то обнаруживается,
что Code1 совершенно не годен. Первый бит
последовательности равен 1, поэтому
первым символом может быть только
,
так как никакой другой код в таблице
для Code1
не начинается с 1. Следующий бит равен
0, но коды для
,
и
все начинаются с 0 и поэтому декодер
должен читать следующий бит. Он равен
1, однако коды для
и
оба имеют в начале 01. Декодер не знает,
как ему поступить. Возможно декодирование
строки как
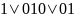 …,
то есть
…,
то есть
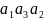 …,
то ли как
…,
то ли как
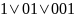 …,
то есть
…,
то есть
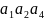 …
При этом анализ поступающих позже битов
последовательности не поможет исправить
положение. Код Code1 является двусмысленным.
В отличие от него, код Code2 дает при
декодировании всегда однозначный
результат.
…
При этом анализ поступающих позже битов
последовательности не поможет исправить
положение. Код Code1 является двусмысленным.
В отличие от него, код Code2 дает при
декодировании всегда однозначный
результат.
Code2 имеет одно важное свойство, которое делает его лучше, чем Code1, которое называется свойством префикса. Это свойство можно сформулировать так: если некоторая последовательность битов выбрана в качестве кода какого-то символа, то ни один код другого символа не может иметь в начале эту последовательность (не может быть префиксом). Если строка «1» же была выбрана в качестве целого кода для , то ни один другой код не может начинаться с 1 (то есть, все они должны начинаться на 0). Если строка «01» является кодом для , то другие коды не должны начинаться с 01. Вот почему коды для и должны начинаться с 00. Естественно, они будут «000» и «001».
Значит, выбирая множество кодов переменной длины, необходимо соблюдать два принципа:
следует назначать более короткие коды часто встречающимся символам;
коды должны удовлетворять свойству префикса.
Следуя этим принципам, можно построить короткие, однозначно декодируемые коды, но не обязательно наилучшие (самые короткие) коды. В дополнение к этим принципам необходим алгоритм, который всегда порождает множество самых коротких кодов (которые в среднем имеют наименьшую длину).
Декодирование. Предположим, что некоторый файл был сжат с помощью кодов переменной длины (префиксных кодов). Для того, чтобы сделать декомпрессию, декодер должен знать префиксный код каждого символа. Эту проблему можно решить тремя способами.
Множество префиксных кодов один раз выбрано и используется всеми кодерами и декодерами. Такой метод используется в факсимильной связи.
Кодер делает свою работу в два прохода. На первом проходе он читает сжимаемый файл и собирает статистические сведения. На втором проходе происходит собственно сжатие. В перерыве между проходами декодер на основе собранной информации создает наилучший префиксный код именно для этого файла. Такой метод дает замечательные результаты по сжатию, но он, обычно, слишком медлителен для практического использования. Также нужно добавлять таблицу построенных префиксных кодов в сжатый файл, чтобы ее знал декодер. Это ухудшает общую производительность алгоритма. Такой подход в статистическом сжатии принято называть полуадаптивной компрессией.
Адаптивное сжатие применяется как кодером, так и декодером. Кодер начинает работать, не зная статистических свойств объекта сжатия. Поэтому первая часть данных сжимается не оптимальным образом, однако, по мере сжатия и сбора статистики, кодер улучшает используемый префиксный код, что приводит к улучшению компрессии.
Алгоритм Шеннона-Фано . Алгоритм Шеннона-Фано – один из первых алгоритмов сжатия, который впервые сформулировали американские ученые Шеннон и Фано. Данный метод сжатия имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины.
Основные этапы:
Символы первичного алфавита
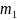 выписывают в порядке убывания
вероятностей.
выписывают в порядке убывания
вероятностей.Символы полученного алфавита делят на две части, суммарные вероятности символов которых максимально близки друг другу.
В префиксном коде для первой части алфавита присваивается двоичная цифра «0», второй части – «1».
Полученные части рекурсивно делятся и их частям назначаются соответствующие двоичные цифры в префиксном коде.
Код Шеннона-Фано строится с помощью дерева. Построение этого дерева начинается от корня. Все множество кодируемых элементов соответствует корню дерева (вершине первого уровня). Оно разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Эти подмножества соответствуют двум вершинам второго уровня, которые соединяются с корнем. Далее каждое из этих подмножеств разбивается на два подмножества с примерно одинаковыми суммарными вероятностями. Им соответствуют вершины третьего уровня. Если подмножество содержит единственный элемент, то ему соответствует концевая вершина кодового дерева; такое подмножество разбиению не подлежит. Подобным образом поступаем до тех пор, пока не получим все концевые вершины.
Пример: код (частота встречаемости): A (50), B (39), C (18), D (49), E (35), F (24).
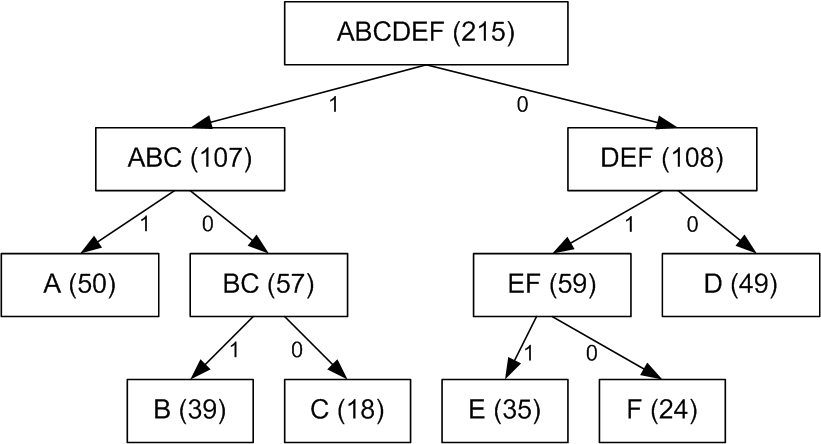
Полученный код: A – 11, B – 101, C – 100, D – 00, E – 011, F – 010.
При
построении кода Шеннона-Фано разбиение
множества элементов может быть
произведено, вообще говоря, несколькими
способами. Выбор разбиения на уровне
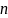 может ухудшить варианты разбиения на
следующем уровне
может ухудшить варианты разбиения на
следующем уровне
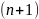 и привести к неоптимальности кода в
целом. Другими словами, оптимальное
поведение на каждом шаге пути еще не
гарантирует оптимальности всей
совокупности действий. Поэтому код
Шеннона-Фано не является оптимальным
в общем смысле, хотя и дает оптимальные
результаты при некоторых распределениях
вероятностей. Для одного и того же
распределения вероятностей можно
построить, вообще говоря, несколько
кодов Шеннона-Фано, и все они могут дать
различные результаты.
и привести к неоптимальности кода в
целом. Другими словами, оптимальное
поведение на каждом шаге пути еще не
гарантирует оптимальности всей
совокупности действий. Поэтому код
Шеннона-Фано не является оптимальным
в общем смысле, хотя и дает оптимальные
результаты при некоторых распределениях
вероятностей. Для одного и того же
распределения вероятностей можно
построить, вообще говоря, несколько
кодов Шеннона-Фано, и все они могут дать
различные результаты.
Кодирование Хаффмана. Кодирование Хаффмана является простым алгоритмом для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот весьма популярный алгоритм служит основой многих компьютерных программ сжатия текстовой и графической информации. В криптографии такой тип кодирования может быть использован для предварительного сжатия исходного текста с целью увеличения эффективной скорости преобразования данных. Многие программы используют непосредственно алгоритм Хаффмана, а другие берут его в качестве одной из ступеней многоуровневого процесса сжатия. Метод Хаффмана производит идеальное сжатие (т.е. сжимает данные до уровня их энтропии) если вероятности символов точно равны отрицательным степеням числа 2. Алгоритм начинает строить кодовое дерево снизу вверх, затем скользит вниз по дереву, чтобы построить каждый индивидуальный код справа налево (от самого младшего бита к самому старшему).
Алгоритм начинается составлением списка символов алфавита в порядке убывания их вероятностей. Затем от корня строится дерево, листьями которого служат эти символы. Это делается по шагам, причем на каждом шаге выбираются два символа с наименьшими вероятностями, добавляются наверх частичного дерева, удаляются из списка и заменяются вспомогательным символом, представляющим эти два символа. Вспомогательному символу приписывается вероятность, равная сумме вероятностей, выбранных на этом шаге символов. Когда список сокращается до одного вспомогательного символа, представляющего весь алфавит, дерево объявляется построенным. Завершается алгоритм спуском по дереву и построением кодов всех символов.
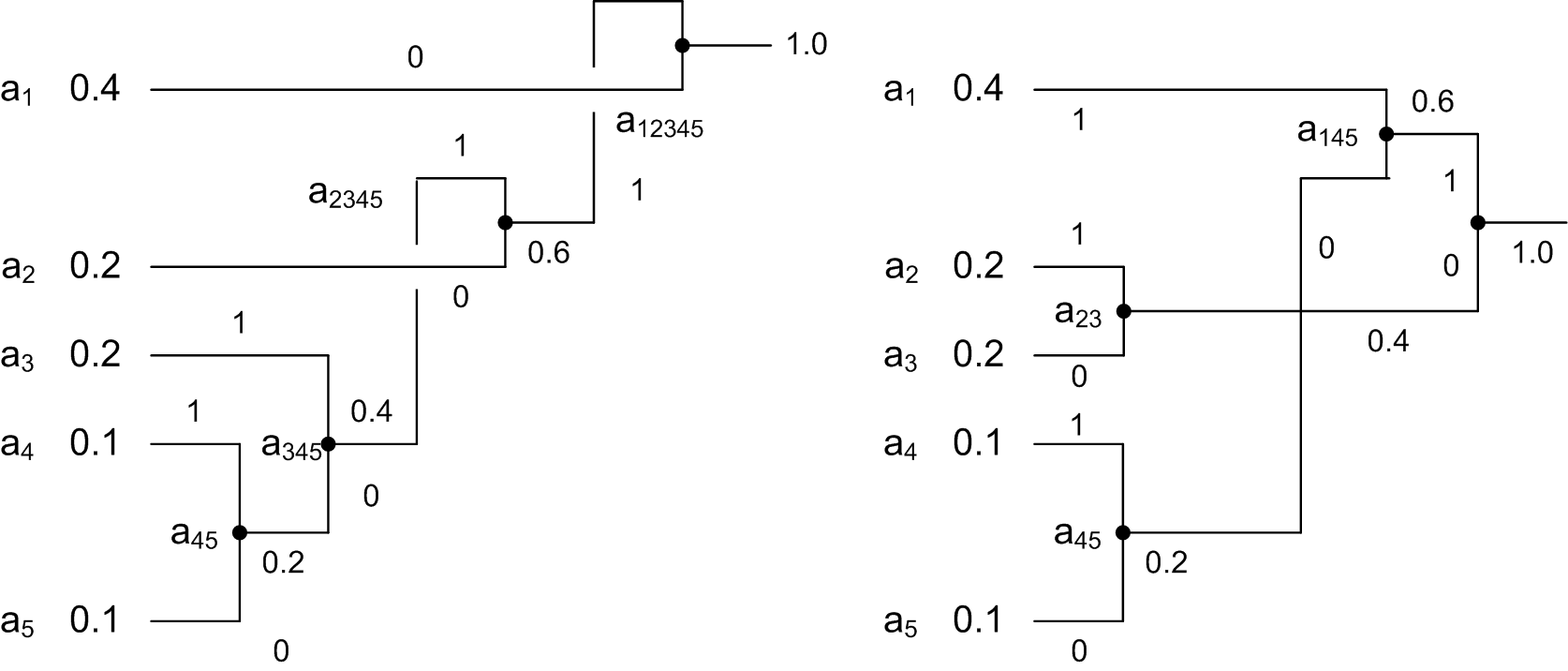
Проиллюстрируем этот алгоритм на простом примере. Пусть имеются пять символов с заданными вероятностями.
Символы объединяются в пары в следующем порядке:
объединяется с
 ,
и оба заменяются комбинированным
символом
,
и оба заменяются комбинированным
символом
 с вероятностью 0.2;
с вероятностью 0.2;Осталось четыре символа, с вероятностью 0.4, а также , и с вероятностями по 0.2. Произвольно выбираем и , объединяем их и заменяем вспомогательным символом
 с вероятностью 0.4.
с вероятностью 0.4.Теперь имеется три символа , и с вероятностями 0.4, 0.2 и 0.4, соответственно. Выбираем и объединяем символы и во вспомогательный символ
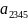 с вероятностью 0.6.
с вероятностью 0.6.Наконец, объединяем два оставшихся символа и и заменяем на
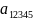 с вероятностью 1.
с вероятностью 1.Дерево построено. Для назначения кодов мы произвольно приписываем бит 1 верхней ветке и бит 0 нижней ветке дерева для каждой пары. В результате получаем следующие коды: 0, 10, 111, 1101 и 1100. Распределение битов по краям – произвольное.
Средняя
длина этого кода равна
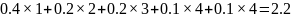 бит/символ. Очень важно, что кодов
Хаффмана бывает много. Некоторые шаги
алгоритма выбирались произвольным
образом, поскольку было больше символов
с минимальной вероятностью. На рис. ХХХб
показано, как можно объединить символы
по-другому и получить иной код Хаффмана
(11, 01, 00, 101 и 100). Средняя длина равна
бит/символ. Очень важно, что кодов
Хаффмана бывает много. Некоторые шаги
алгоритма выбирались произвольным
образом, поскольку было больше символов
с минимальной вероятностью. На рис. ХХХб
показано, как можно объединить символы
по-другому и получить иной код Хаффмана
(11, 01, 00, 101 и 100). Средняя длина равна
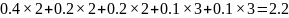 бит/символ как и предыдущего кода.
бит/символ как и предыдущего кода.
Декодирование Хаффмана. Перед тем как начать сжатие потока данных, кодер должен построить коды. Это делается с помощью вероятностей (или частот) появления символов. Вероятности или частоты следует записать в файл, содержащий преобразованные данные, чтобы декодер Хаффмана мог произвести процесс декодирования. Это легко сделать, так как частоты являются целыми числами, а вероятности также можно представить целыми числами. Обычно это приводит к добавлению нескольких сотен байтов в сжатый файл.
Алгоритм декодирования очень прост. Следует начать с корня и прочитать первый бит сжатого файла. Если это нуль, следует двигаться по нижней ветке дерева; если это единица, то двигаться нужно по верхней ветке дерева. Далее читается второй бит и происходит движение по следующей ветке по направлению к листьям. Когда декодер достигнет листа дерева, он узнает код первого несжатого символа. Процедура повторяется для следующего бита, начиная опять из корня дерева.
Арифметическое
кодирование.
Метод Хаффмана является простым и
эффективным, однако он порождает
наилучшие коды переменной длины тогда,
когда вероятности символов алфавита
являются степенями числа 2, т.е. равны
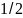 ,
,
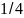 ,
,
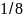 и т.д. Это связано с тем, что метод Хаффмана
присваивает каждому символу алфавита
код с целым числом битов.
и т.д. Это связано с тем, что метод Хаффмана
присваивает каждому символу алфавита
код с целым числом битов.