Материал: Лабы
Встроенные переменные: настройка процесса обработки данных
Утилита awk использует встроенные переменные, которые позволяют настраивать процесс обработки данных и дают доступ, как к обрабатываемым данным, так и к некоторым сведениям о них.
Мы уже рассматривали позиционные переменные — $1, $2, $3, которые позволяют извлекать значения полей, работали мы и с некоторыми другими переменными. На самом деле, их довольно много. Вот некоторые из наиболее часто используемых:
FIELDWIDTHS — разделённый пробелами список чисел, определяющий точную ширину каждого поля данных с учётом разделителей полей;
FS — уже знакомая вам переменная, позволяющая задавать символ-разделитель полей;
RS — переменная, которая позволяет задавать символ-разделитель записей;
OFS — разделитель полей на выводе awk-скрипта;
ORS — разделитель записей на выводе awk-скрипта.
По умолчанию переменная OFS настроена на использование пробела. Её можно установить так, как нужно для целей вывода данных:
awk 'BEGIN{FS=":"; OFS="-"} {print $1,$6,$7}' /etc/passwd
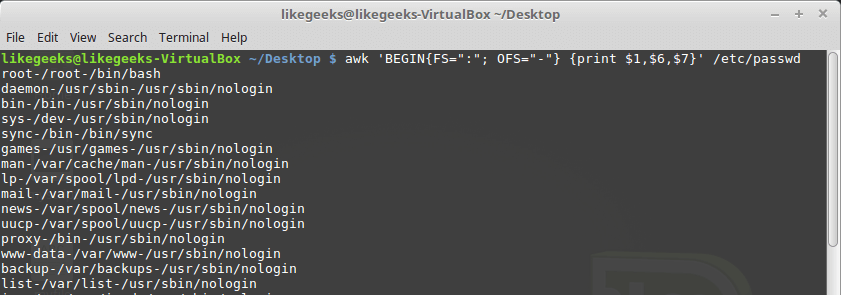
Установка разделителя полей выходного потока
Переменная FIELDWIDTHS позволяет читать записи без использования символа-разделителя полей.
В некоторых случаях, вместо использования разделителя полей, данные в пределах записей расположены в колонках постоянной ширины. В подобных случаях необходимо задать переменную FIELDWIDTHS таким образом, чтобы её содержимое соответствовало особенностям представления данных.
При установленной переменной FIELDWIDTHS awk будет игнорировать переменную FS и находить поля данных в соответствии со сведениями об их ширине, заданными в FIELDWIDTHS.
Предположим, имеется файл testfile, содержащий такие данные:
1235.9652147.91
927-8.365217.27
36257.8157492.5
Известно, что внутренняя организация этих данных соответствует шаблону 3-5-2-5, то есть, первое поле имеет ширину 3 символа, второе — 5, и так далее. Вот скрипт, который позволит разобрать такие записи:
awk 'BEGIN{FIELDWIDTHS="3 5 2 5"}{print $1,$2,$3,$4}' testfile
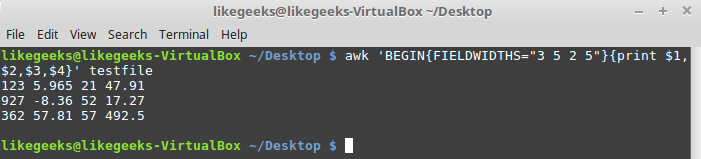
Использование переменной FIELDWIDTHS
Посмотрим на то, что выведет скрипт. Данные разобраны с учётом значения переменной FIELDWIDTHS, в результате числа и другие символы в строках разбиты в соответствии с заданной шириной полей.
Переменные RS и ORS задают порядок обработки записей. По умолчанию RS и ORS установлены на символ перевода строки. Это означает, что awk воспринимает каждую новую строку текста как новую запись и выводит каждую запись с новой строки.
Иногда случается так, что поля в потоке данных распределены по нескольким строкам. Например, пусть имеется такой файл с именем addresses:
Person Name
123 High Street
(222) 466-1234
Another person
487 HighStreet
(523) 643-8754
Если попытаться прочесть эти данные при условии, что FS и RS установлены в значения по умолчанию, awk сочтёт каждую новую строку отдельной записью и выделит поля, опираясь на пробелы. Это не то, что нам в данном случае нужно.
Для того, чтобы решить эту проблему, в FS надо записать символ перевода строки. Это укажет awk на то, что каждая строка в потоке данных является отдельным полем.
Кроме того, в данном примере понадобится записать в переменную RS пустую строку. Обратите внимание на то, что в файле блоки данных о разных людях разделены пустой строкой. В результате awk будет считать пустые строки разделителями записей. Вот как всё это сделать:
awk 'BEGIN{FS="\n"; RS=" "} {print $1,$3}' addresses
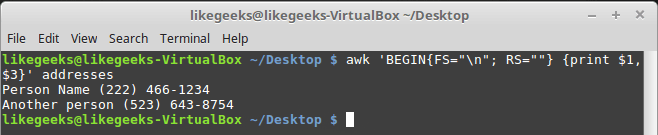
Результаты настройки переменных RS и FS
Как видите, awk, благодаря таким настройкам переменных, воспринимает строки из файла как поля, а разделителями записей становятся пустые строки.
Встроенные переменные: сведения о данных и об окружении
Помимо встроенных переменных, о которых мы уже говорили, существуют и другие, которые предоставляют сведения о данных и об окружении, в котором работает awk:
ARGC — количество аргументов командной строки;
ARGV — массив с аргументами командной строки;
ARGIND — индекс текущего обрабатываемого файла в массиве ARGV;
ENVIRON — ассоциативный массив с переменными окружения и их значениями;
ERRNO — код системной ошибки, которая может возникнуть при чтении или закрытии входных файлов;
FILENAME — имя входного файла с данными;
FNR — номер текущей записи в файле данных;
IGNORECASE — если эта переменная установлена в ненулевое значение, при обработке игнорируется регистр символов;
NF — общее число полей данных в текущей записи;
NR — общее число обработанных записей.
Переменные ARGC и ARGV позволяют работать с аргументами командной строки. При этом скрипт, переданный awk, не попадает в массив аргументов ARGV. Напишем такой скрипт:
awk 'BEGIN{printARGC,ARGV[1]}' myfile
После его запуска можно узнать, что общее число аргументов командной строки — 2, а под индексом 1 в массиве ARGV записано имя обрабатываемого файла. В элементе массива с индексом 0 в данном случае будет «awk».

Работа с параметрами командной строки
Переменная ENVIRON представляет собой ассоциативный массив с переменными среды. Опробуем её:
awk '
BEGIN{
print ENVIRON["HOME"]
print ENVIRON["PATH"]
}'
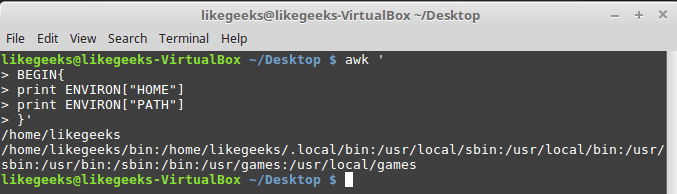
Работа с переменными среды
Переменные среды можно использовать и без обращения к ENVIRON. Сделать это, например, можно так:
echo | awk -v home=$HOME '{print "My home is " home}'

Работа с переменными среды без использования ENVIRON
Переменная NF позволяет обращаться к последнему полю данных в записи, не зная его точной позиции:
awk 'BEGIN{FS=":"; OFS=":"} {print $1,$NF}' /etc/passwd
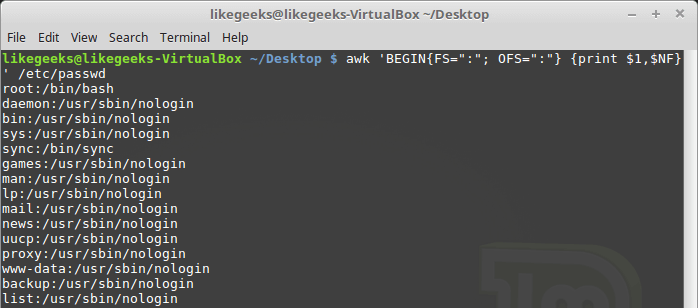
Пример использования переменной NF
Эта переменная содержит числовой индекс последнего поля данных в записи. Обратиться к данному полю можно, поместив перед NF знак $.
Переменные FNR и NR, хотя и могут показаться похожими, на самом деле различаются. Так, переменная FNR хранит число записей, обработанных в текущем файле. Переменная NR хранит общее число обработанных записей. Рассмотрим пару примеров, передав awk один и тот же файл дважды:
awk 'BEGIN{FS=","}{print $1,"FNR="FNR}' myfile myfile
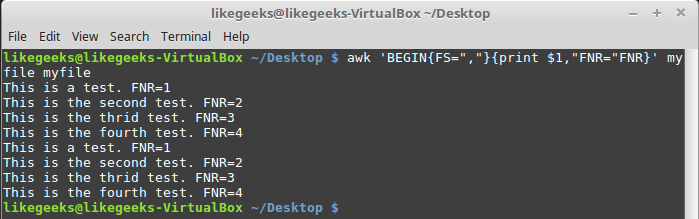
Исследование переменной FNR
Передача одного и того же файла дважды равносильна передаче двух разных файлов. Обратите внимание на то, что FNR сбрасывается в начале обработки каждого файла.
Взглянем теперь на то, как ведёт себя в подобной ситуации переменная NR:
awk '
BEGIN {FS=","}
{print $1,"FNR="FNR,"NR="NR}
END{print "There were",NR,"records processed"}' myfile myfile
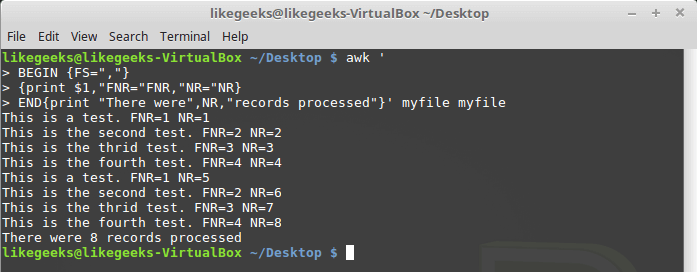
Различие переменных NR и FNR
Как видно, FNR, как и в предыдущем примере, сбрасывается в начале обработки каждого файла, а вот NR, при переходе к следующему файлу, сохраняет значение.
Пользовательские переменные
Как и любые другие языки программирования, awk позволяет программисту объявлять переменные. Имена переменных могут включать в себя буквы, цифры, символы подчёркивания. Однако, они не могут начинаться с цифры. Объявить переменную, присвоить ей значение и воспользоваться ей в коде можно так:
awk '
BEGIN{
test="This is a test"
print test
}'
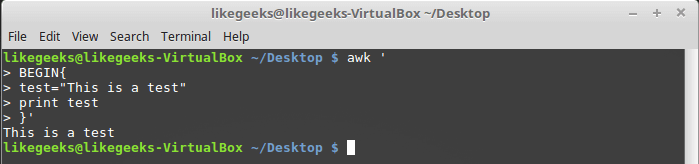
Работа с пользовательской переменной
Условный оператор
Awk поддерживает стандартный во многих языках программирования формат условного оператора if-then-else. Однострочный вариант оператора представляет собой ключевое слово if, за которым, в скобках, записывают проверяемое выражение, а затем — команду, которую нужно выполнить, если выражение истинно.
Например, есть такой файл с именем testfile:
10
15
6
33
45
Напишем скрипт, который выводит числа из этого файла, большие 20:
awk '{if ($1 > 20) print $1}' testfile

Однострочный оператор if
Если нужно выполнить в блоке if несколько операторов, их нужно заключить в фигурные скобки:
awk '{
if ($1 > 20)
{
x = $1 * 2
print x
}
}' testfile
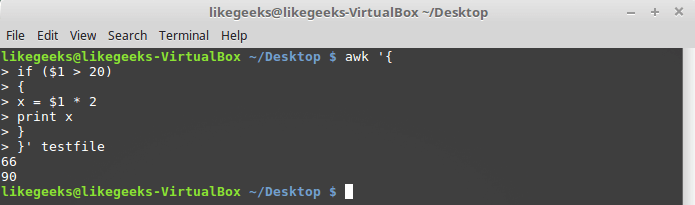
Выполнение нескольких команд в блоке if
Как уже было сказано, условный оператор awk может содержать блок else:
awk '{
if ($1 > 20)
{
x = $1 * 2
print x
} else
{
x = $1 / 2
print x
}}' testfile
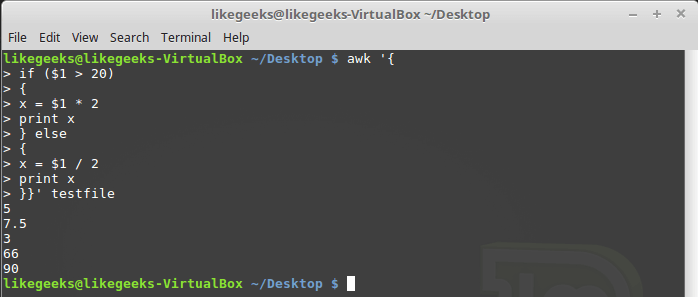
Условный оператор с блоком else
Ветвь else может быть частью однострочной записи условного оператора, включая в себя лишь одну строку с командой. В подобном случае после ветви if, сразу перед else, надо поставить точку с запятой:
awk '{if ($1 > 20) print $1 * 2; else print $1 / 2}' testfile
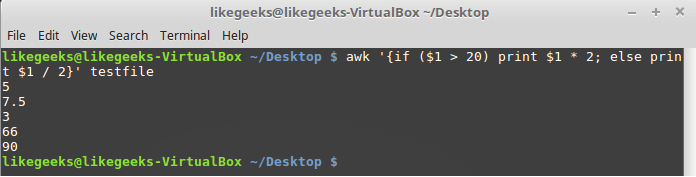
Условный оператор, содержащий ветви if и else, записанный в одну строку
Цикл while
Цикл while позволяет перебирать наборы данных, проверяя условие, которое остановит цикл. Вот файл myfile, обработку которого мы хотим организовать с помощью цикла:
124 127 130
112 142 135
175 158 245
Напишем такой скрипт:
awk '{
total = 0
i = 1
while (i < 4)
{
total += $i
i++
}
avg = total / 3
print "Average:",avg
}' testfile
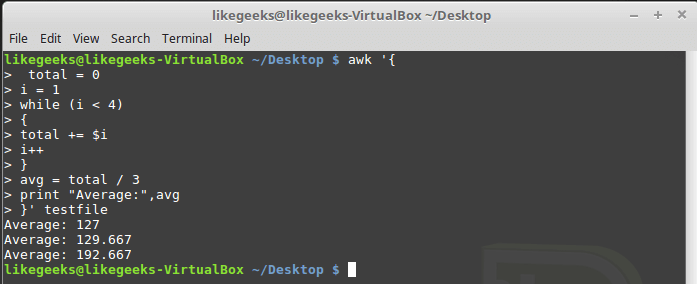
Обработка данных в цикле while
Цикл while перебирает поля каждой записи, накапливая их сумму в переменной total и увеличивая в каждой итерации на 1 переменную-счётчик i. Когда i достигнет 4, условие на входе в цикл окажется ложным и цикл завершится, после чего будут выполнены остальные команды — подсчёт среднего значения для числовых полей текущей записи и вывод найденного значения.