Материал: Лабы
Program – программа awk. Программа должна быть заключена в одинарные кавычки.
File – полный путь к файлу, являющемуся источником данных для программируемого фильтра. Если файл не указан, данные будут браться из стандартного потока ввода/вывода.
Awk воспринимает поступающие к нему данные в виде набора записей. Записи представляют собой наборы полей. Упрощенно, если не учитывать возможности настройки awk и говорить о некоем вполне обычном тексте, строки которого разделены символами перевода строки, запись — это строка. Поле — это слово в строке
Рассмотрим наиболее часто используемые ключи командной строки awk:
-Ffs — позволяет указать символ-разделитель для полей в записи.
-ffile — указывает имя файла, из которого нужно прочесть awk-скрипт.
-vvar=value — позволяет объявить переменную и задать её значение по умолчанию, которое будет использовать awk.
-mfN — задаёт максимальное число полей для обработки в файле данных.
-mrN — задаёт максимальный размер записи в файле данных.
-Wkeyword — позволяет задать режим совместимости или уровень выдачи предупреждений awk.
Чтение awk-скриптов из командной строки
Скрипты awk, которые можно писать прямо в командной строке, оформляются в виде текстов команд, заключённых в фигурные скобки. Кроме того, так как awk предполагает, что скрипт представляет собой текстовую строку, его нужно заключить в одинарные кавычки:
awk '{print "Welcome to awk command tutorial"}'
Запустим эту команду… И ничего не произойдёт. Дело тут в том, что мы, при вызове awk, не указали файл с данными. В подобной ситуации awk ожидает поступления данных из STDIN. Поэтому выполнение такой команды не приводит к немедленно наблюдаемым эффектам, но это не значит, что awk не работает — он ждёт входных данных из STDIN.
Если теперь ввести что-нибудь в консоль и нажать Enter, awk обработает введённые данные с помощью скрипта, заданного при его запуске. Awk обрабатывает текст из потока ввода построчно, этим он похож на команду sed. В нашем случае awk ничего не делает с данными, он лишь, в ответ на каждую новую полученную им строку, выводит на экран текст, заданный в команде print.

Первый запуск awk, вывод на экран заданного текста
Что бы мы ни ввели, результат в данном случае будет одним и тем же — вывод текста. Для того, чтобы завершить работу awk, нужно передать ему символ конца файла (EOF, End-of-File). Сделать это можно, воспользовавшись сочетанием клавиш CTRL + D.
Позиционные переменные, хранящие данные полей
Одна из основных функций awk заключается в возможности манипулировать данными в текстовых файлах. Делается это путём автоматического назначения переменной каждому элементу в строке. По умолчанию awk назначает следующие переменные каждому полю данных, обнаруженному им в записи:
$0 — представляет всю строку текста (запись).
$1 — первое поле.
$2 — второе поле.
$n — n-ное поле.
Поля выделяются из текста с использованием символа-разделителя. По умолчанию — это пробельные символы вроде пробела или символа табуляции.
Рассмотрим использование этих переменных на простом примере. А именно, обработаем файл, в котором содержится несколько строк (этот файл показан на рисунке ниже) с помощью такой команды:
awk '{print $1}' myfile
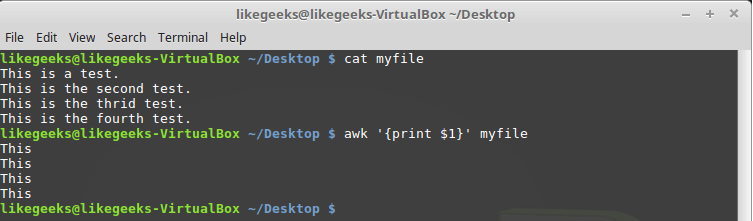
Вывод в консоль первого поля каждой строки
Здесь использована переменная $1, которая позволяет получить доступ к первому полю каждой строки и вывести его на экран.
Иногда в некоторых файлах в качестве разделителей полей используется что-то, отличающееся от пробелов или символов табуляции. Выше мы упоминали ключ awk -F, который позволяет задать необходимый для обработки конкретного файла разделитель:
awk -F: '{print $1}' /etc/passwd
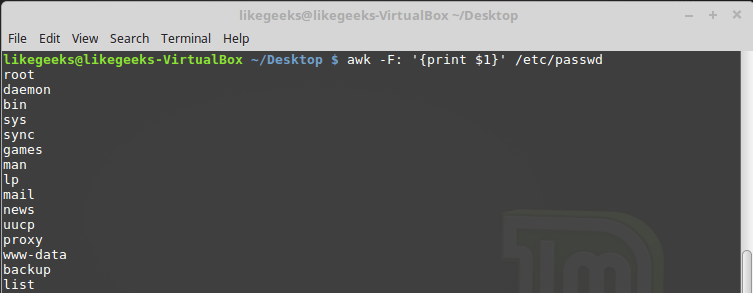
Указание символа-разделителя при вызове awk
Эта команда выводит первые элементы строк, содержащихся в файле /etc/passwd. Так как в этом файле в качестве разделителей используются двоеточия, именно этот символ был передан awk после ключа -F.
Использование нескольких команд
Вызов awk с одной командой обработки текста — подход очень ограниченный. Awk позволяет обрабатывать данные с использованием многострочных скриптов. Для того, чтобы передать awk многострочную команду при вызове его из консоли, нужно разделить её части точкой с запятой:
echo "My name is Tom" | awk '{$4="Adam"; print $0}'

Вызов awk из командной строки с передачей ему многострочного скрипта
В данном примере первая команда записывает новое значение в переменную $4, а вторая выводит на экран всю строку.
Чтение скрипта awk из файла
Awk позволяет хранить скрипты в файлах и ссылаться на них, используя ключ -f. Подготовим файл testfile, в который запишем следующее:
{print $1 " has a home directory at " $6}
Вызовем awk, указав этот файл в качестве источника команд:
awk -F: -f testfile /etc/passwd
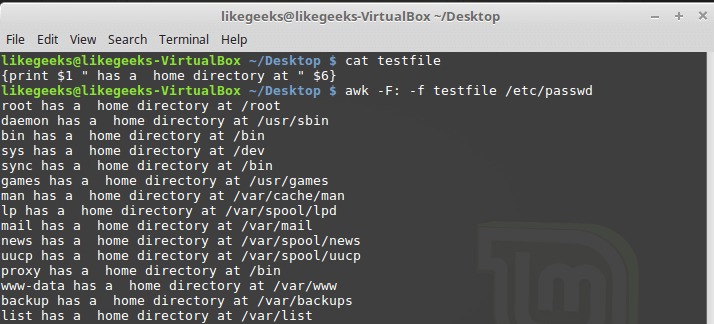
Вызов awk с указанием файла скрипта
Тут мы выводим из файла /etc/passwd имена пользователей, которые попадают в переменную $1, и их домашние директории, которые попадают в $6. Обратите внимание на то, что файл скрипта задают с помощью ключа -f, а разделитель полей, двоеточие в нашем случае, с помощью ключа -F
В файле скрипта может содержаться множество команд, при этом каждую из них достаточно записывать с новой строки, ставить после каждой точку с запятой не требуется.
Вот как это может выглядеть:
{
text = " has a home directory at "
print $1 text $6
}
Тут мы храним текст, используемый при выводе данных, полученных из каждой строки обрабатываемого файла, в переменной, и используем эту переменную в команде print. Если воспроизвести предыдущий пример, записав этот код в файл testfile, выведено будет то же самое.
Выполнение команд до начала обработки данных
Иногда нужно выполнить какие-то действия до того, как скрипт начнёт обработку записей из входного потока. Например — создать шапку отчёта или что-то подобное.
Для этого можно воспользоваться ключевым словом BEGIN. Команды, которые следуют за BEGIN, будут исполнены до начала обработки данных. В простейшем виде это выглядит так:
awk 'BEGIN {print "HelloWorld!"}'
А вот — немного более сложный пример:
awk 'BEGIN {print "The File Contents:"}
{print $0}' myfile
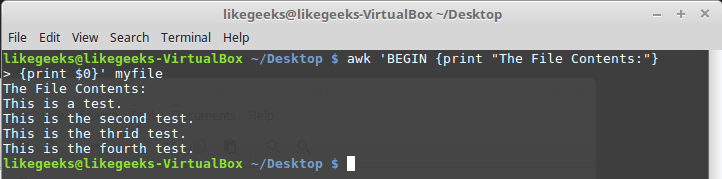
Выполнение команд до начала обработки данных
Сначала awk исполняет блок BEGIN, после чего выполняется обработка данных. Будьте внимательны с одинарными кавычками, используя подобные конструкции в командной строке. Обратите внимание на то, что и блок BEGIN, и команды обработки потока, являются в представлении awk одной строкой. Первая одинарная кавычка, ограничивающая эту строку, стоит перед BEGIN. Вторая — после закрывающей фигурной скобки команды обработки данных.
Выполнение команд после окончания обработки данных
Ключевое слово END позволяет задавать команды, которые надо выполнить после окончания обработки данных:
awk 'BEGIN {print "The File Contents:"}
{print $0}
END {print "End of File"}' myfile
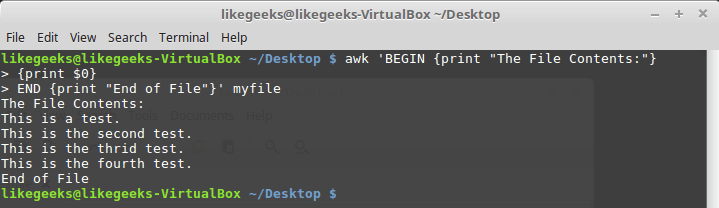
Результаты работы скрипта, в котором имеются блоки BEGIN и END
После завершения вывода содержимого файла, awk выполняет команды блока END. Это полезная возможность, с её помощью, например, можно сформировать подвал отчёта. Теперь напишем скрипт следующего содержания и сохраним его в файле myscript:
BEGIN {
print "The latest list of users and shells"
print " UserName \t HomePath"
print "-------- \t -------"
FS=":"
}
{
print $1 " \t " $6
}
END {
print "The end"”b
}
Тут, в блоке BEGIN, создаётся заголовок табличного отчёта. В этом же разделе мы указываем символ-разделитель. После окончания обработки файла, благодаря блоку END, система сообщит нам о том, что работа окончена.
Запустим скрипт:
awk -f myscript /etc/passwd
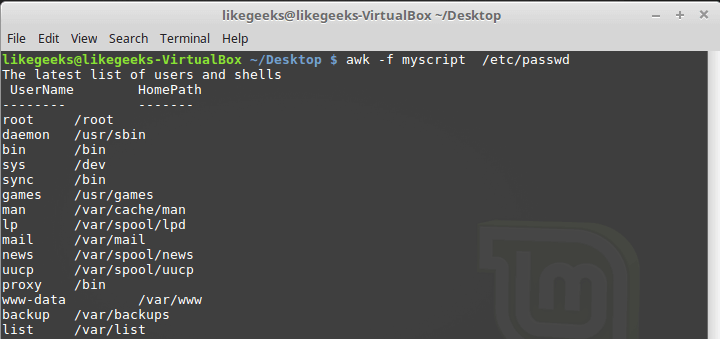
Обработка файла /etc/passwd с помощью awk-скрипта