Материал: Лабы
Порядок выполнения работы
Все этапы выполнения работы необходимо фиксировать.
Войти в систему от имени своей учетной записи. В случае, если вход осуществлен в графическую оболочку, переключиться на текстовую консоль или запустить терминал. Вся дальнейшая работа выполняется исключительно в терминале. Использование root прав запрещено.
Создать родительский каталог. В качестве имени каталога задать свою фамилию. Все остальные действия данной лабораторной работы будут выполняться внутри данного каталога.
Внутри каталога, созданного на 2-м шаге создать структуру каталогов, представленную на рисунке. Вывести на экран содержимое текущего каталога и убедиться, что все созданные каталоги созданы без ошибок. Для отображения используйте утилиту tree. При необходимости произведите обновление компонентов и установите утилиту tree вручную.
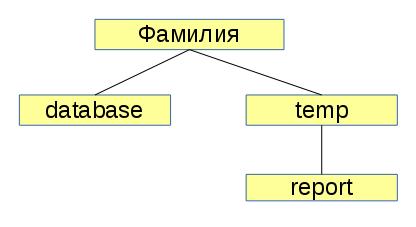
Перейти в каталог temp. Убедиться, что он является текущим. Вывести на экран содержимое каталога.
С помощью встроенного текстового редактора внутри каталога temp создать файл базы данных dataset1.txt. Заполнить файл данными в соответствии с номером варианта задания. В качестве разделителя столбцов данных в файле использовать символ “;” без пробелов. Файл должен содержать не менее 3-х строк.
С помощью конвеера команд внутри каталога temp создать файл базы данных dataset2.txt. Заполнить файл данными в соответствии с номером варианта задания. В качестве разделителя столбцов данных в файле использовать символ “;” без пробелов. Файл должен содержать не менее 4-х строк. Данные должны отличаться от введенных ранее.
С помощью перенаправления вывода в файл, либо используя команду echo создать файл базы данных dataset3.txt. Заполнить файл данными в соответствии с номером варианта задания. В качестве разделителя столбцов данных в файле использовать символ “;” без пробелов. Файл должен содержать не менее 3-х строк. Данные должны отличаться от введенных ранее.
Вывести на экран содержимое всех созданных файлов базы данных.
Объединить содержимое всех созданных файлов базы данных в один файл data.txt и поместить его в каталог /database.
Перейти в каталог /database. Убедиться, что он является текущим. Вывести на экран содержимое каталога. Убедиться, что созданный файл data.txt содержит все необходимые данные.
Подсчитать количество строк файла data.txt. Результат подсчета вывести на экран и в файл отчета output.txt, расположенный в каталоге report (см. рисунок).
С помощью любого из использованных выше способов дополнить файл data.txt 2-я строками данных в соответствии с номером варианта задания. В качестве разделителя столбцов данных в файле использовать символ “;” без пробелов. Убедиться, что файл data.txt содержит все необходимые данные.
Повторно подсчитать количество строк файла data.txt. Результат подсчета вывести на экран и дописать в конец файла отчета output.txt, расположенного в каталоге report.
Осуществить фильтрацию данных файла data.txt в соответствии с номером варианта задания. Результат фильтрации вывести на экран и в файл отчета filtered.txt, расположенный в каталоге report. Повторить фильтрацию с различными значениями фильтра. Результаты фильтрации выводить на экран и дописывать в файл отчета filtered.txt.
Выполнить сортировку содержимого файла data.txt в соответствии с номером варианта задания. Результат сортировки вывести на экран и в файл отчета sorted.txt, расположенный в каталоге report.
Выполнить фильтрацию содержимого файла data.txt с сортировкой результата фильтрации. Фильтрацию и сортировку выполнить в соответствии с номером варианта задания. Результат вывести на экран и в файл отчета filteredsorted.txt, расположенный в каталоге report.
Исследовать самостоятельно команды: date, cal, pwd, who, clear, exit.
Выполнить команду вывода календаря на экран и любым известным способом записать значение в файл calendar.txt, находящийся в каталоге /database. Результат вывести на экран.
Выводы
В данной лабораторной работе мы приобрели навыки работы с файлами и каталогами, познакомились с некоторыми командами манипулирования данными на примере текстовой базы данных. Рассмотренные в лабораторной работе команды shell могут применяться при выполнении рутинных операций по управлению и обслуживанию операционных систем, а также для автоматизации некоторых задач (администрирование, программирование и т.п.)
Варианты заданий
1 Автомобили (ФИО владельца, модель, год выпуска, место регистрации). Поиск по модели автомобиля. Сортировка по году выпуска. |
2 Библиотека (ФИО автора, название произведения, год издания, издательство). Поиск по издательству. Сортировка по году издания. |
3 Поликлиника (Номер поликлиники, специалисты, ФИО, дни приема). Поиск по специалистам. Сортировка по дням приема. |
4 Бухгалтерия (ФИО сотрудников, год поступления на работу, зарплата, номер отдела). Поиск по зарплате. Сортировка по отделам. |
5 Цветы (название цветка, окраска, месяц цветения, место произрастания). Поиск по название цветка. Сортировка по месту произрастания. |
6 Институт (ФИО студента, курс, группа, размер стипендии). Поиск по ФИО. Сортировка по размеру стипендии. |
7 Преподаватель (ФИО преподавателя, должность, название кафедры, факультет). Поиск по ФИО преподавателя. Сортировка по факультету. |
8 Спортивная команда (ФИО спортсмена, возраст, рост, вид спорта). Поиск по виду спорта. Сортировка по возрасту. |
9 Воинская часть (ФИО военнослужащего, звание, подразделение, возраст). Поиск по подразделению. Сортировка по возрасту. |
10 Экспорт (наименование товара, объем поставки, стоимость единицы продукции, страна экспорта). Поиск по наименованию товара. Сортировка по объемам поставки. |
11 Телефонный справочник (ФИО абонента, номер телефона, место работы, город). Поиск ФИО. Сортировка по месту работы. |
12 Авиакомпания (номер рейса, дата вылета, время вылета, пункт назначения). Поиск по пункту назначения. Сортировка по дате вылета. |
13 Автосервис. (Название, тип выполняемых работ, сроки, цены). Поиск по типу работ. Сортировка цене инверсно. |
14 Футбольные команды (название команды, ФИО тренера, количество забитых мячей, количество набранных очков). Поиск по названию команды. Сортировка по ФИО тренера. |
15 Вокзал (номер поезда, тип поезда, количество вагонов, пункт назначения). Поиск по типу поезда. Сортировка по количеству вагонов. |
16 Квартиросъемщики (ФИО, название улицы, номер дома, номер квартиры). Поиск по названию улицы. Сортировка по номеру дома. |
17 Порт (название корабля, год постройки, место постройки, тип корабля). Поиск по названию корабля. Сортировка по году постройки. |
18 Страна (название страны, количество жителей, площадь, столица). Поиск по названию страны. Сортировка по площади инверсно. |
19 Газета (название газеты, периодичность, тематика, год основания). Поиск по названию тематике. Сортировка по периодичности. |
20 Фотоаппарат (название фотоаппарата, год выпуска, количество мегапикселей, характеристика зума). Поиск по названию фотоаппарата. Сортировка по количеству мегапикселей. |
21 Фильмы (название фильма, жанр, год выхода, название студии). Поиск по названию жанру. Сортировка по году выхода инверсно. |
Лабораторная работа №3
Использование программируемого фильтра awk
Введение
AWK — это интерпретируемый скриптовый C-подобный язык построчного разбора и обработки входного потока (например, текстового файла) по заданным шаблонам (регулярным выражениям). Используется в bash (SH) скриптах.
Благодаря AWK в нашем распоряжении оказывается язык программирования, а не довольно скромный набор команд, отдаваемых редактору. С помощью языка программирования AWK можно выполнять следующие действия:
объявлять переменные для хранения данных;
использовать арифметические и строковые операторы для работы с данными;
использовать структурные элементы и управляющие конструкции языка, такие, как условные операторы и циклы;
реализовать сложные алгоритмы обработки данных;
создавать форматированные отчёты.
AWK может запоминать контекст, делать сравнения, создавать форматированные отчёты, которые удобно читать и анализировать. Это оказывается очень кстати при работе с лог-файлами, которые могут содержать миллионы записей. При надлежащей сноровке, она может объединять множество строк. Awk – это инструмент, предоставляющий несколько очень удобных способов обработки текстовых данных, которые могут пригодиться в повседневной жизни.
Цель лабораторной работы
Лабораторная работа выполняется в среде, установленной и настроенной в процессе выполнения лабораторной работы №1 или в среде, установленной в компьютерном классе.
Целью данной лабораторной работы является изучение возможностей программируемого фильтра AWK при обработке текстовой информации.
В результате выполнения лабораторной работы студенты получат практические навыки манипулирования данными средствами awk, составления правил обработки потоков информации, формирования отчетов и извлечения требуемой информации из большого массива данных.
Структура awk-программы
В общем виде программа awk состоит из операторов (правил), имеющих вид:
шаблон {действие} шаблон {действие} . . . |
Шаблон задает правила для отбора обрабатываемых строк в потоке данных. Строки не соответствующие шаблону не обрабатываются. При составлении шаблона используется синтаксис схожий с синтаксисом регулярных выражений языка программирования PERL.
В случае, если шаблон не задан, обрабатываются все строки потока данных.
Например:
awk '{print}' f-awk # выдает весь текст;
awk '/до/ {print}' f-awk # выдает строки, где есть "до".
awk '/до/ {}' f-awk # выдает строки, где есть "до"
awk '/до/ {print("Привет!")}' f-awk
Действие – последовательность команд манипулирования с данными, заключенная в фигурные скобки. Команды разделяются точкой с запятой, переводом строки или закрывающей скобкой.
Внутри awk проограммы возможны комментарии (как в shell "#.........").
Схема вызова awk
Программируемый фильтр awk может быть вызван из командной строки, командного файла, программы. В общем виде строка вызова awk выглядит следующим образом:
awkoptionsprogramfile
Options – список параметров, позволяющих получить доступ к дополнительным функциям программируемого фильтра. Для просмотра описания всех возможных параметров можно воспользоваться встроенной справкой по команде awk (выполнив команду awk --help) или вызвать подробное руководство (команда manawk).