J.B. Broekaert, et al. Cognitive Psychology 117 (2020) 101262
MGamble = |
1 |
0 |
0 |
0 |
|
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
0 |
(28) |
|
0 |
0 |
0 |
0 |
to produce the gamble probability |
|
p(gamble X, Cond) |
= |
|Mgamble T ( /2) (0, C)|1 , |
(29) |
where · 1 is shorthand notation for summing of the (absolute) values of the vector components. We have fixed the time of measurement to the conventional choice t =  /2, which is a standard procedure that is also applied in the quantum-like model as well (Busemeyer & Bruza, 2012). This procedure –of setting a conventional time of measurement– is typically applied in a Markov dynamical approach in order to avoid independence of the final belief-action state on the initial belief-action state. (One can easily check this independence from initial conditions at larger time scales, Eq. (21).)
/2, which is a standard procedure that is also applied in the quantum-like model as well (Busemeyer & Bruza, 2012). This procedure –of setting a conventional time of measurement– is typically applied in a Markov dynamical approach in order to avoid independence of the final belief-action state on the initial belief-action state. (One can easily check this independence from initial conditions at larger time scales, Eq. (21).)
For each of the two periods for decision making in each flow order (K-to-U and U-to-K in Fig. 2) a separate evolved belief-action state will be obtained. Each of these evolved states will differ due to their respective initial belief-action states. Therefore, even if the transition rate matrix K is the same in both flow orders and for all outcome conditions, the theoretical gamble probabilities will be different.
In the first period, the initial belief-action state on a Win and Lose condition of the first-stage outcome are formally given by the vectors;
0,W = 2 , 2 , (1 |
2 |
) , (1 |
2 |
) , |
0,L = (1 |
2 |
) , (1 |
2 |
) , 2 , 2 |
(30) |
where  is a weight parameter, 0
is a weight parameter, 0 

 1. Should
1. Should  = 1 then the states
= 1 then the states  0,W and
0,W and  0,L are precisely allocated to their Win and Lose components respectively, while at the same time for both states a uniform probability to Gamble or Stop is assumed. Due to the context effect from the other gambles in the block, regulated by
0,L are precisely allocated to their Win and Lose components respectively, while at the same time for both states a uniform probability to Gamble or Stop is assumed. Due to the context effect from the other gambles in the block, regulated by  , these belief-action states respectively express that Win or Lose information only partially determines the belief state in the block where the outcome is Known. This ambiguous belief-action state reflects incompletely registered information notwithstanding unambiguous Win, or Lose, information in the gamble description. This belief-action state occurs because of its embedding in the mixed context of the Win-outcome and Lose-outcome block. It implements an effect of contextual anchoring which leads to compounding information of the present gamble outcome condition and outcome conditions of previously taken gambles within the same block.
, these belief-action states respectively express that Win or Lose information only partially determines the belief state in the block where the outcome is Known. This ambiguous belief-action state reflects incompletely registered information notwithstanding unambiguous Win, or Lose, information in the gamble description. This belief-action state occurs because of its embedding in the mixed context of the Win-outcome and Lose-outcome block. It implements an effect of contextual anchoring which leads to compounding information of the present gamble outcome condition and outcome conditions of previously taken gambles within the same block.
The initial belief-action state –in first period– on Unknown outcome of the first-stage gamble is
0,U = |
1 |
, |
1 |
, |
1 |
, |
1 |
(31) |
4 |
4 |
4 |
4 |
which expresses the belief-action state with uniformly weighted Win and Lose outcomes and is similarly indifferent to either Gamble and Stop decisions due to lack of previously experienced gambles. The state is caused by the uncertainty due to missing information on the first-stage outcome in the Unknown-outcome condition in first period.
In the second period similar effects of context are at play, but now due to the carry-over effect the initial state in the second period will depend also on the participant’s history of gambling in the first period. The initial belief-action states for Win and Lose first-stage outcome conditions will also contain residual belief support for the opposite condition. The magnitude of the context effect will be changed by the carry-over effect
00,W = |
µ µ |
(1 |
µ) |
|
(1 |
µ) |
|
00,L = |
(1 |
µ) |
|
(1 |
µ) |
|
µ µ |
|
2 , 2 , |
|
2 |
, |
|
2 |
, |
|
2 |
, |
|
2 |
, |
2 , 2 |
(32) |
where µ is a weight parameter, 0 |
µ |
1. The weighting parameter µ in the second period differs from |
in first period. |
Because of previous exposure to Known outcome conditioned first-stage gambles, the initial belief-action state on Unknown
conditioned first-stage gambles is not uniform anymore |
|
00,U = 0,W ( ) + (1 |
) 0,L ( ). |
(33) |
This is a belief-action state weighted by  , 0
, 0 

 1, on Win and Lose states of the first period, which is caused by a carry-over effect of the belief tendencies about the two possible outcomes of Win and Lose in first period.
1, on Win and Lose states of the first period, which is caused by a carry-over effect of the belief tendencies about the two possible outcomes of Win and Lose in first period.
The Markov model processes the belief-action state for each outcome condition, payoff and period by evolving from the appropriate initial state. Each time a new second-stage gamble is proposed the participant will thus first regain a dedicated initial beliefaction state. In our experimental paradigm, the participant is assumed to do so, Eqs. (32) and (33), for each of the five payoff values and for each of the three types of first-stage outcome condition {W , L, U}. During the experiment each participant thus produces fifteen final belief-action states which lead up to the appropriate gamble decisions according to the first-stage gamble outcome condition, payoff size and flow order.
Parametrization. The Markov model requires four dynamical parameters for the utility expression of the second-stage gambles. Two parameters - intercept and slope - for each condition of Win and Lose express the different motivational utility of the two conditions, denoted by {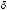 0W , 1W } and {
0W , 1W } and {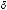 0L, 1L}. The effect of this utility difference on the decision is controlled by the sensitivity parameter {s} in the logistic form, Eqs. (23). The ‘coupled-switching’ dynamics that implements the attention switching from Win to Lose and its reversal of related Gamble or Stop decision is controlled by the strength of the mixing parameter {
0L, 1L}. The effect of this utility difference on the decision is controlled by the sensitivity parameter {s} in the logistic form, Eqs. (23). The ‘coupled-switching’ dynamics that implements the attention switching from Win to Lose and its reversal of related Gamble or Stop decision is controlled by the strength of the mixing parameter {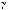 }. The context effect on
}. The context effect on
 0, and where in each column all rows need to add up to zero for the conservation of probability. Depending on the magnitude of
0, and where in each column all rows need to add up to zero for the conservation of probability. Depending on the magnitude of  , these transition rate matrices will either increase action potential for Gamble (
, these transition rate matrices will either increase action potential for Gamble (

 , between the vector components is made to depend on the utility, Eqs.
, between the vector components is made to depend on the utility, Eqs.  [.5, 1
[.5, 1 0.
0.
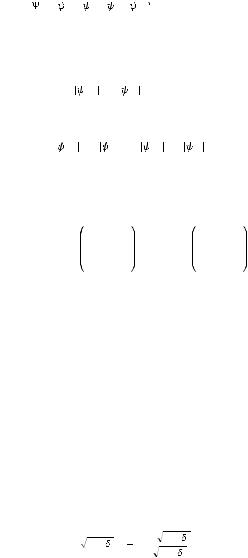
 ,
,  }.
}.


 . The encompassing Hamiltonian, with
. The encompassing Hamiltonian, with  [.5, 1
[.5, 1 /2, corresponding to the choice of measurement time in the Markov model, Eq.
/2, corresponding to the choice of measurement time in the Markov model, Eq. 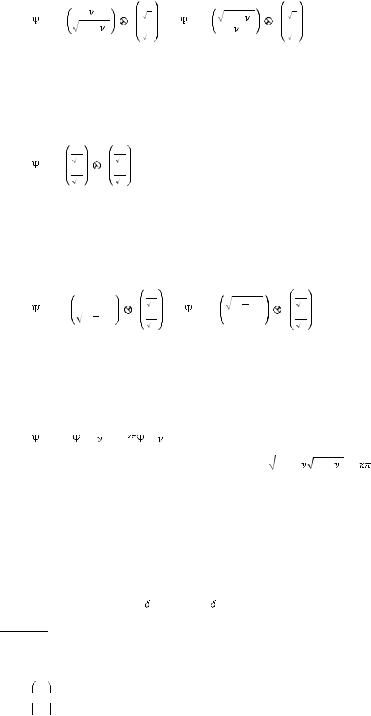
 is a weight parameter, 0
is a weight parameter, 0 

 1. Should
1. Should 

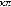 between the two states for Win and Lose. The sign and amplitude of this phase allows for constructive or destructive interference between the two states and thus brings about a subjective tendency towards either of the known outcome beliefs
between the two states for Win and Lose. The sign and amplitude of this phase allows for constructive or destructive interference between the two states and thus brings about a subjective tendency towards either of the known outcome beliefs
 ad
ad