Материал: Диплом магистратура
Рис. 5.2 – Кількість записів та ознак у таблиці
Отже метод буде працювати з 483 557 записами, що є заявками на кредити, а також з 18 ознаками. Обробимо дані, та відсічемо не унікальні дані (рисунок 5.3).

Рис. 5.3 – Кількість унікальних заявок
Також до тестового набору даних йде додаткова таблиця з результатами кредитування по заявці. Завантажимо ці дані та розглянемо їх (лістинг 5.2, рисунок 5.4).
Лістинг 5.2 – Програмний код отримання результуючих даних
credit_record =
pd.read_csv('/kaggle/input/credit-card-approval-prediction/credit_record.csv')
credit_record.head()
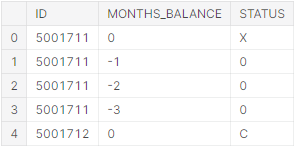
Рис. 5.4 – Приклад результуючих даних
Детально про сприйняття даних цієї таблиці проводився огляд у пункті 2.3 даної атестаційної роботи. Переглянемо загальну кількість заявок, та скільки унікальних клієнтів всього (рисунки 5.5-5.6).
![]()
Рис. 5.5 – Кількість заявок клієнтів, що мають статуси

Рис. 5.6 – Кількість унікальних клієнтів, у результуючій вибірці
Змінимо осі представлення для відображення всіх ознак заявки на кредит (рисунок 5.7).
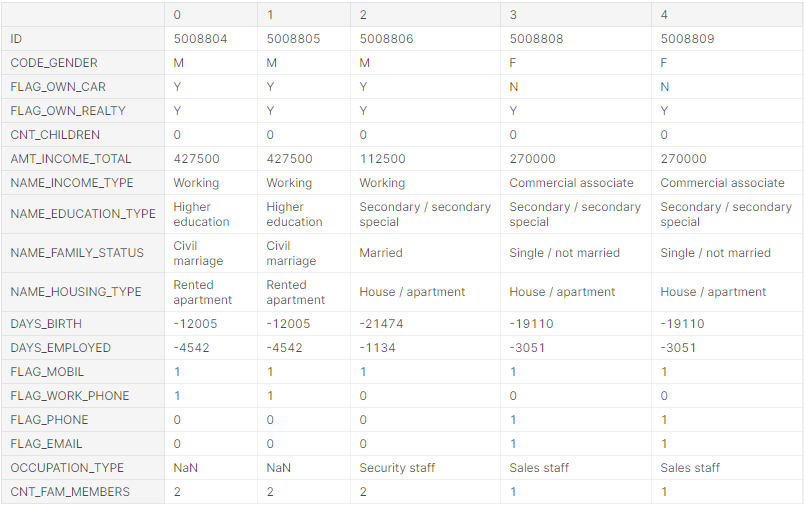
Рис. 5.7 – Приклад даних з відображенням усіх ознак
Далі слідуючи алгоритму навчання роботи методу, розробленому у пункті 2.3 даної атестаційної роботи, необхідно перевірити дані на наявність пропущених значень (рисунок 5.7).
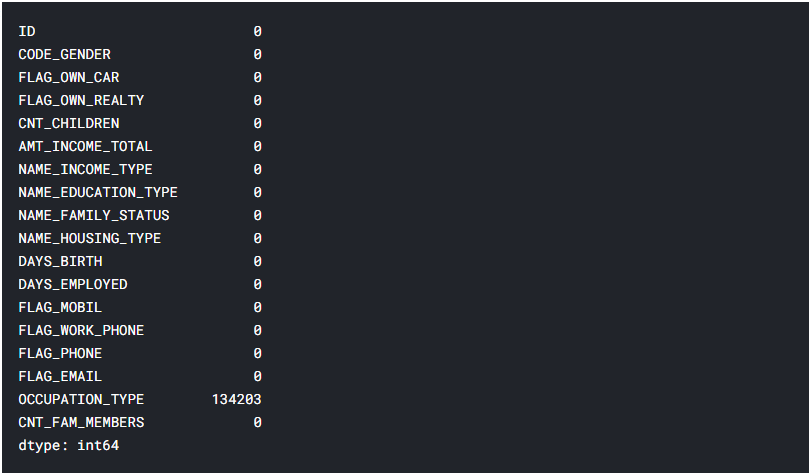
Рис. 5.7 – Кількість пропущених даних кожної ознаки
Виявилось що тип професії не вказаний у 134203 заявках, якщо підрахувати відсоткову кількість від всіх заявок, це близько 30%. Проаналізуємо цю ознаку, щоб дізнатися її корисність та необхідність у даній вибірці (рисунок 5.8). Виявилось, що в ознаці використовуються дуже різні дані, та якщо заповнити їх середнім значенням то вибірка може втратити свою репрезентативність, тож щоб не зіпсувати кінцевий результат, краще видалити ознаку (лістинг 5.3).
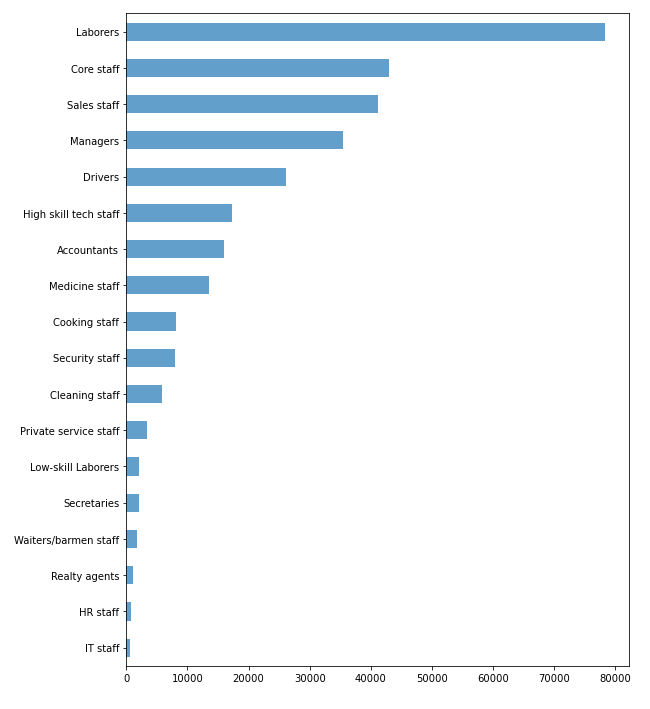
Рис. 5.8 – Діаграма співвідношення ознаки «тип професії» до її кількості
Лістинг 5.3 – Програмний код видалення стовпця з вибірки
application_record.drop('OCCUPATION_TYPE', axis=1, inplace=True)
Таким чином, вибірка залишилась без пропущених значень, а отже можна переходити до нормалізації даних. Скористаймося рішенням прийнятим у пункті 2.3, та розіб’ємо результуючі заявки за 2 класами, де 0 – надійний клієнт , 1 - боржника боржник (лістинг 5.4, рисунок 5.9).
Лістинг 5.4 – Програмний код для розбиття заявок на класи
defaulter_codes= ['0','1','2','3','4','5']
credit_record['Label']= np.where(credit_record.STATUS.isin(defaulter_codes), 1, 0)
credit_record.head(10)
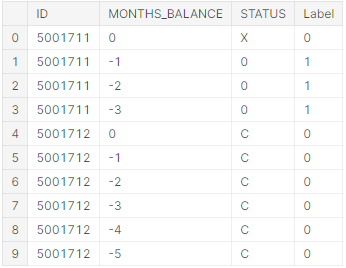
Рис. 5.9 – Результуючі дані з поділом на класи
Тепер ознака STATUS у результуючій вибірці нам не потрібна, її можна видалити, а також проаналізуймо дані (лістинг 5.5, рисунок 5.10).
Лістинг 5.5 – Програмний код видалення ознаки та виводу даних
credit_record.drop('STATUS', axis=1, inplace=True)
credit_record['Label'].value_counts()

Рис. 5.10 – Кількість заявок кожного класу
Після проведених перетворень видно, що успішних заявок більше ніж неуспішних, проте близько 38% неуспішних заявок – доволі багато. Отже провівши перетворення, відсіявши пропущені значення, виділивши класи, в рамках тестових даних тепер необхідно з’єднати дві таблиці, по ознаці ID, а також виведемо дані і перевіримо, чи є пропущені значення після злиття таблиць (лістинг 5.6, рисунок 5.11).
Лістинг 5.6 – Програмний код з’єднання таблиць та виведення даних
record = pd.merge(credit_record, application_record, on='ID', how='left')
record.head()
record.isnull().sum()
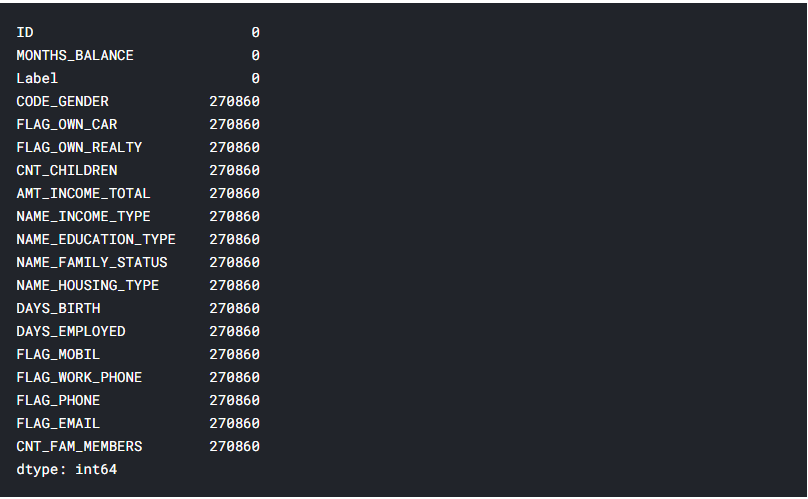
Рис. 5.11 – Кількість пропущених даних після злиття таблиць для кожної ознаки
Виявилось, що дані з 2 таблиць співпадають не до кінця, і 270860 заявок на кредити залишились без статусу. Для навчання моделі, необхідно щоб всі заявки мали свої класи, тож видалимо рядки, що не мають класу і виведемо кількість заявок, що мають всі ознаки і приналежність до класу (лістинг 5.7, рисунок 5.12).
Лістинг 5.7 – Програмний код видалення рядків з пустими значеннями і виведення даних
record.dropna(inplace=True)
record['Label'].value_counts()

Рис. 5.12 – Кількість заявок кожного класу, з описом всіх ознак
Оглянувши дані, можна зробити висновок, що після видалення пустих рядків статистична ситуація не змінилась відношення і залишилось приблизно 62:38. Представимо це графіком (рисунок 5.12)
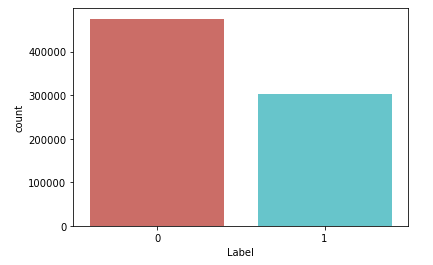
Рис. 5.13 – Співвідношення вдалих класів заявок до кількості
Далі, змінимо дані таким чином, щоб алгоритм використав їх правильно. Загалом, з усіх ознак виділимо нові, для того щоб значення ознак змінились з номінальних на порядкові або індикаторні (лістинг 5.8, рисунок 5.14).
Лістинг 5.9 – Програмний код спрощення номінальних даних
record = pd.get_dummies(record, columns=['CODE_GENDER','FLAG_OWN_CAR','FLAG_OWN_REALTY','NAME_INCOME_TYPE', 'NAME_EDUCATION_TYPE','NAME_FAMILY_STATUS','NAME_HOUSING_TYPE'], drop_first = False)
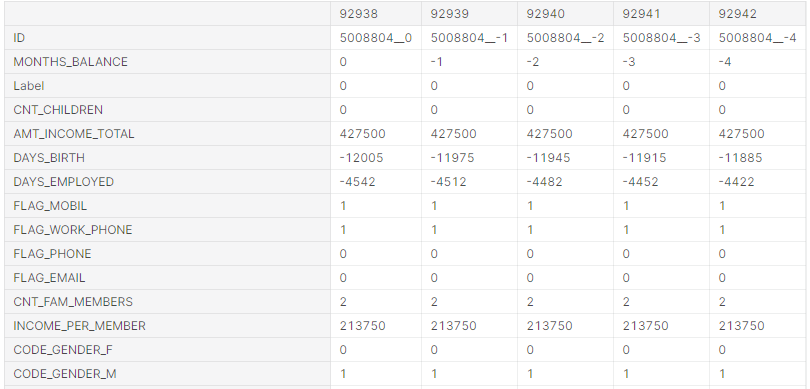
Рис. 5.14 – Спрощення номінальних даних
Після того як дані були оброблені, відсіяні пропущені значення, таблиці об’єднані, виділення класів було здійснено тепер є можливість проводити навчання моделей. Для початку проведемо навчання простої моделі дерева рішень CART (лістинг 5.10).
Лістинг 5.10 – Програмний код навчання моделі CART
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(random_state=0, max_depth=25)
tree.fit(features_train, label_train)
# predict train set
pred_train=tree.predict(features_train)
# predict test set
pred_test=tree.predict(features_test)
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(pred_train,label_train)
accuracy_test = accuracy_score(pred_test,label_test)
Тепер подивимось результати класифікації, та проаналізуймо їх (рисунок 5.15).
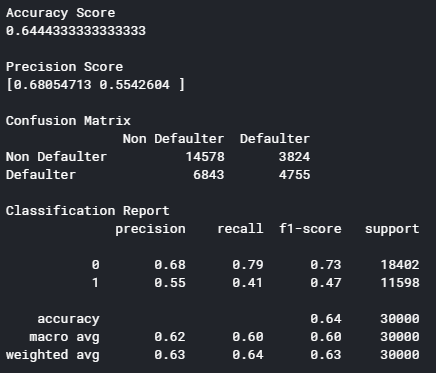
Рис 5.15 – Класифікаційний звіт роботи методу CART
Перевіряючи на тестових даних, виявилось що точність моделі дорівнює близько 64%. Користуючись алгоритмом, що описаний у пункті 2.3 розглянемо як модель зробила оцінку ознак (рисунок 5.16). Після цього, необхідно підібрати мінімальну оцінку ознак Wmin для навчання наступної моделі на основі алгоритму SVM.
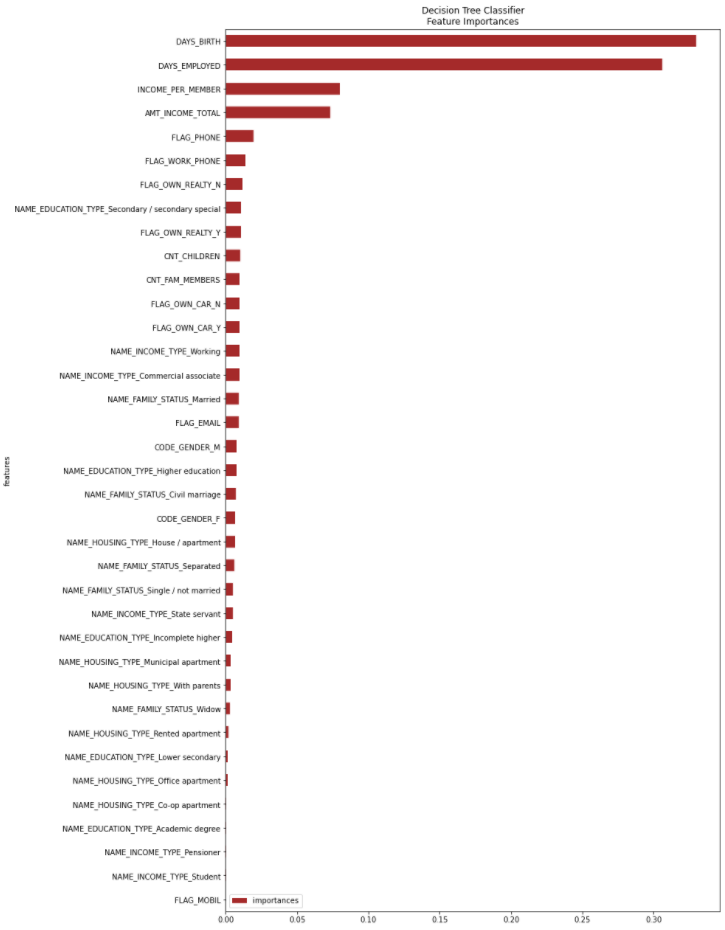
Рис. 5.16 – Оцінка ознак за допомогою моделі CART
Далі проаналізуємо цифри, для того щоб підібрати Wmin (рисунок 5.17).
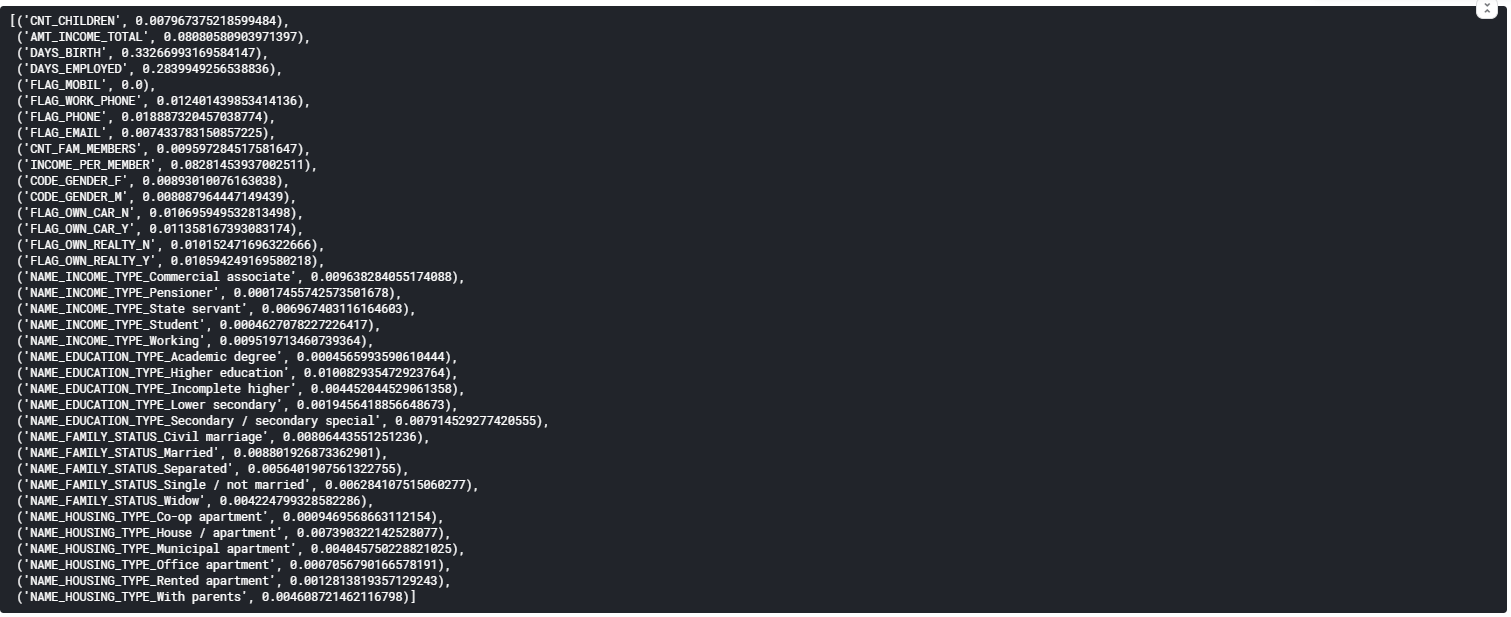
Рис. 5.17 – Важливість ознак
Отже можна побачити, що деякі ознаки мають більший вплив на те, чи буде виданий кредит чи ні, а деякі майже не грають ролі. Тож, відсіємо зовсім неважливі ознаки, задавши значення Wmin = 0.00125 (рисунок 5.18).

Рис. 5.18 – Ознаки, що мають W > Wmin
Далі відбувається фільтрація стовпців вибірки, та дані подаються для навчання моделі SVM (лістинг 5.11).
Лістинг 5.11 – Подання даних для навчання алгоритму SVM
from sklearn import svm classification_svm = svm.SVC(kernel='linear')
classification_svm.fit(features_train, label_train)
pred_train = classification_svm.predict(features_train)
pred_test=classification_svm.predict(features_test)
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(pred_train,label_train)
accuracy_test = accuracy_score(pred_test,label_test)
Тепер проаналізуємо результат роботи комбінованого методу, за допомогою класифікаційного звіту (рисунок 5.19).
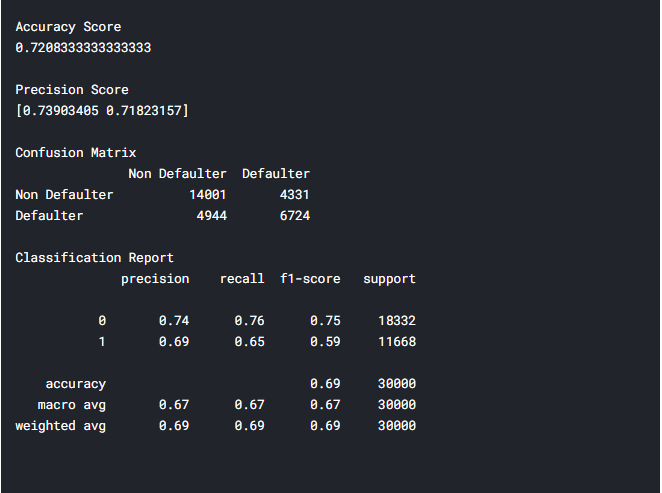
Рис. 5.19 – Класифікаційний звіт для комбінованого методу
Отже, класифікаційний звіт показує оцінку точності – 72%. В порівнянні з використанням чистого методу CART різниця майже у 8%. Чи можна сказати, що даний метод на будь-яких даних буде показувати кращі результати? Ні, не можна, дуже часто результати залежать від самих даних, та методик їх обробки, нормалізації. Щодо предметної області, та проектованої системи 72% – і досить непоганий результат, проте недосконалий. Для покращення методу, можливо, потрібно використати інші методи в ансамблі, спробувати техніки Stacking, Boosting.
Загалом, таку модель можна використовувати у реальній системі, так як комбінований метод буде виконувати роль лише підтримки рішення співробітника банку, а видавати, чи не видавати кредит буде його рішенням.
Висновки перелік посилань
Косова Т. Д. Аналіз банківської діяльності: навч. посіб. / Т. Д. Косова. – К.: Центр учбової літератури, 2010. – 486 с.
Лагутін В. Д. Кредитування: теорія і практика: навч. посібн. / В. Д. Лагутін. – К.: ТОВ "Знання", КОО, 2010. – 215 с.
Г. Н. Белоглазова Банковское дело. Организация деятельности коммерческого банка. / Белоглазова Г. Н., Кроливецкая Л. П. – М.: Высшее образование, 2011. – 422 с.
Пшик М.І. Етапи становлення і розвитку фінансово-кредитних відносин в Україні // Проблеми і перспективи розвитку банківської системи України: Зб. тез доп. ІХ Всеукр. наук.-практ. конф. – Суми: УАБС НБУ, 2011. – 188 с.
Мельник П. В. Банківські системи зарубіжних країн – банківські системи зарубіжних країн : підручник / П. В Мельник. – К. : Вид-во ЦУЛ ; Алерта. – 2010. – 574 с.
Холодна Ю. Є. Банківська система : навчальний посібник / Ю. Є. Холодна, О. М. Рац. – Х. : Вид. ХНЕУ, 2013. – 316 с. (Укр. мов.)
Варцаба В.І. Сучасне банківництво: теорія і практика: Навч. посібник. / В.І. Варцаба, О.І. Заславська— Ужгород: Видавництво УжНУ «Говерла», 2018. — 364 с.
Копилюк О.І. Банківські операції : навч. посібник / О.І. Копилюк, Г.В. БоднарчукГрита. – К.: Знання, 2010. – 447 с.
Маркетинг у банку : навчальний посібник / [Т. А. Васильєва, С. М. Козьменко, І. О. Школьник та ін.] ; за заг. ред. Т. А. Васильєвої ; Державний вищий навчальний заклад “Українська академія банківської справи Національного банку України”. – Суми : ДВНЗ “УАБС НБУ”, 2014. – 353 с.
Економічний ризик: методи оцінки та управління / За заг. ред..Васильєвої Т.А., Кривич Я.М. Суми :ДВНЗ «УАБС НБУ», 2015. – 208 с.
Винник Т. Переваги та вигоди мобільноF го банкінгу / Т. Винник, О. Пастущин // МатеF ріали міжнародної науковоFпрактичної конфеF ренції студентів і молодих учених "СоціальноF економічні аспекти розвитку економіки", 27— 28 квітня 2017 року. — Т.: ТНТУ. — 2017. — С. 46—47.
Азаренкова Г. М. Аналіз моделювання і управління ризиком (у схемах та прикладах) : навч. посібн. / Г. М. Азаренкова. – Львів : Новий Світ – 2010. – 240 с.
Кожухівська О. А. Прогнозування ризиків кредитування фізичних осіб за математичними моделями [Електронний ресурс] / О. А. Кожухівська // Вісник Національного університету «Львівська політехніка». Інформаційні системи та мережі. – 2013. – № 770. – С. 177-185. – Режим доступу: http://nbuv.gov.ua/UJRN/VNULPICM_2013_770_23.
Ильясов С. М. Об оценке кредитоспособности банковского заемщика / С. М. Ильясов // Деньги и кредит. – 2015. – № 9. – С. 28–34.
Кузнєцова Н. В. Порівняльний аналіз характеристик моделей оцінювання ризиків кредитування / Н. В. Кузнєцова, П. І. Бідюк // Наукові вісті НТУУ «КПІ». – 2010. – №1. – C. 42-53.
Васильчак С. В. Оцінка кредитоспроможності позичальника як один із методів економічної безпеки / С. В. Васильчак, Л. Р. Демус // Науковий вісник НЛТУ України. - 2012. - Вип. 22.1. - С. 154-161.
Бондаренко Ю.В. Порівняльний аналіз підходів щодо оцінки кредитоспроможності позичальника – юридичної особи / Ю.В. Бондаренко // Молодіжний науковий вісник УАБС НБУ. Серія: Економічні науки. – 2012. - № 1. – С. 18-25.
Бучко І. Є.Скоринг як метод зниження кредитного ризику банку [Електронний ресурс] / І. Є. Бучко // Вісник Університету банківської справи Національного банку України. – 2013. – № 2. – Режим доступу: http://nbuv.gov.ua/UJRN/VUbsNbU_2013_2_37 .
Самойлова С. С. Скоринговые модели оценки кредитного риска [Электронный ресурс] / С. С. Самойлова, М. А. Курочка // Социальноэкономические явления и процессы. – 2014. – № 3 (61). – Режим доступа: http://cyberleninka.ru/article/n/skoringovye-modeli-otsenkikreditnogo-riska.
Виговський В.Г. Методичні підходи до оцінки кредитоспроможності суб'єктів господарювання комерційними банками [Текст] / В.Г. Виговський // Облік і фінанси АПК. – 2012. – №3. – С.125-128.
Кожухівська О. А. Прогнозування ризиків кредитування фізичних осіб за математичними моделями [Електронний ресурс] / О. А. Кожухівська // Вісник Національного університету «Львівська політехніка». Інформаційні системи та мережі. – 2013. – № 770. – С. 177-185. – Режим доступу: http://nbuv.gov.ua/UJRN/VNULPICM_2013_770_23.
Банківська система України : становлення і розвиток в умовах глобалізації економічних процесів : монографія / О. В. Дзюблюк, Б. П. Адамик, Г. Р. Балянт [та ін.] ; за ред. О. В. Дзюблюка. – Тернопіль : Астон, 2012. – С. 358 - 372.
Christopher Pal, Mark Hall, Eibe Frank, Ian Witten. Data Mining: Practical Machine Learning Tools and Techniques, 4rd ed. / Morgan Kaufmann, 2016.
Sudhakar M and Dr. C. V. Krishna Reddy, "CREDIT EVALUATION MODEL OF LOAN PROPOSALS FOR BANKS USING DATA MINING," International Journal of Latest Research in Science and Technology, pp. 126-131, july 2014.
Zurada, Jozef, and Martin Zurada. "How Secure Are “Good Loans”: Validating Loan-Granting Decisions And Predicting Default Rates On Consumer Loans."Review of Business Information Systems (RBIS) 6.3 (2011): 65-84.
Abhijit A. Sawant and P. M. Chawan, "Comparison of Data Mining Techniques used for Financial Data Analysis," International Journal of Emerging Technology and Advanced Engineering, june 2013