Материал: Диплом магистратура
Опис 2-шарової клієнт-серверної архітектури
У 2-шаровій клієнт-серверній архітектурі робоче навантаження розділено між клієнтським додатком, на якому розміщений інтерфейс користувача, та серверним додатком, на якому знаходяться основні сервіси та база даних. В дійсності ж, обидва додатки можуть бути розміщені на одному комп’ютері. На рис. 4.3 зображена схема 2-шарової архітектури.
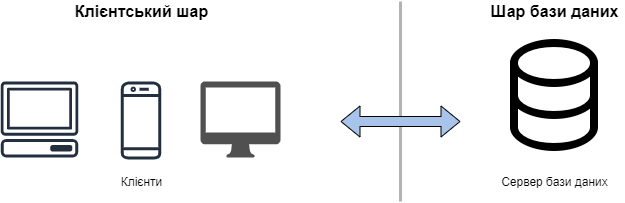
Рис. 4.3 – Схема 2-шарової клієнт-серверної архітектури
У такому типі архітектури, сервер та база даних знаходяться у одному шарі. Вибір архітектури 2-шарового типу, може підійти для систем, що будуть витримувати навантаження від невеликої кількості користувачів. Також, можна використовувати 2-шаровий тип, для створення прототипів, та якщо додаток буде працювати з невеликою кількістю даних. Рекомендується використовувати системи на такій архітектурі, при обмеженні, що кількість одночасних підключень користувачів буде меншою за 100.
Опис 3-шарової клієнт-серверної архітектури
Для того, щоб покрити деякі обмеження 2-шарової архітектури, була розроблена 3-шарова архітектура, яка дозволяє розгортувати клієнтський додаток, серверний додаток та сервер бази даних на різних ізольованих платформах. Звісно, якщо необхідно, можна все розгорнути на одному комп’ютері, проте це рекомендовано лише для тестування чи розробки. Схема 3-шарової архітектури зображена на рисунку 4.4.
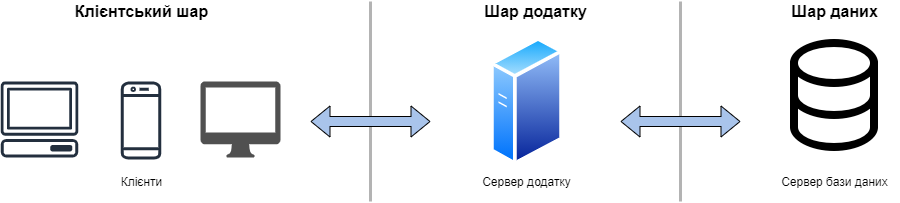
Рис. 4.4 – Схема 3-шарової архітектури
Кожен з рівнів такої архітектури виконує свої обов’язки. Клієнтський шар у свою чергу виконує запити до серверу додатку, який у свою чергу викликає потрібні сервіси і, якщо необхідно, звертається до серверу бази даних. Інформація з шару даних повертається до серверу додатку, оброблюється та повертається до клієнта. Для розробки додатків, на такому типі архітектури, необхідно витратити більше часу на розробку, а це означає і більше коштів. Проте, коли річ йде про великі об’єми даних та про безпеку цих даних, то 3-шарова архітектура дозволяє досягти бажаного результату.
Опис n-шарової клієнт-серверної архітектури
Архітектура додатку вважається N-шаровою тоді, коли в ній присутні всі шари, що описані у 3-шаровій, та додаткові. Архітектури такого типу, використовуються для розробки складних високонавантажених систем. Звісно, такими системами легко керувати, вони гнучкі та гарно масштабуються. Проте, найголовнішим мінусом є ціна, кожен шар має розроблюватися різними командами, необхідні аналітики та менеджери. На рисунку 4.5 зображено схему N-шарової архітектури.
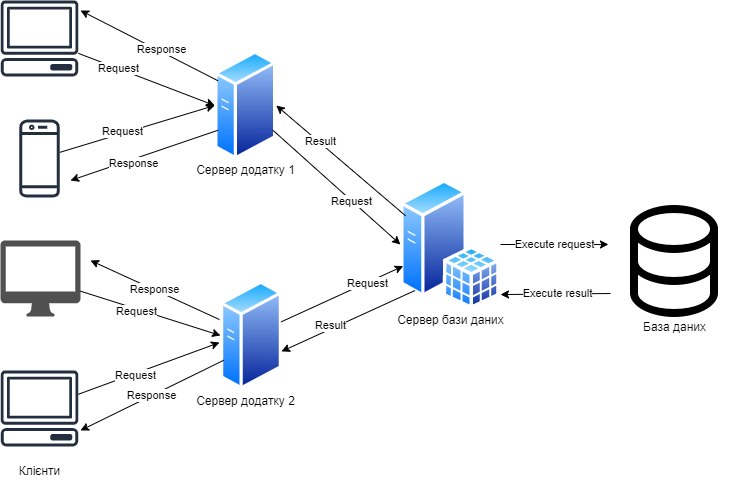
Рис. 4.5 – Схема N-шарової архітектури
При порівнянні архітектурних рішень для проектованої системи підтримки рішень, щодо видачі банківських кредитів, було обрано 3-шарову клієнт-серверну архітектуру. Зважаючи на ціну та час розробки, архітектура N-шарового типу – не підходить. Оцінюючи навантаження даних та силу виділених обчислювальних ресурсів, стало зрозуміло, що 2-шарова архітектура не зможе витримати навантаження.
В рамках атестаційної роботи, проектується прототип системи, отже була обрана 3-шарова архітектура. Для подальшого розвитку системи, можливе додавання додаткових шарів та переходу до N-шарового типу.
Обґрунтування вибору субд
Для розробки системи, було обрано СУБД Oracle. Ця СУБД має велику кількість переваг, що і вплинуло на цей вибір, деякий перелік яких приведений нижче:
Oracle підтримує найбільші бази даних;
забезпечує підтримку великої кількості користувачів;
підтримка великої кількості одночасних запитів;
забезпечує якісну обробку транзакцій;
велика швидкість транзакцій;
велика швидкість роботи з даними;
передбачена робота з критичними ситуаціями;
відкат БД чи системний збій не приведе до припинення роботи БД;
легко встановлювати на будь-яку ОС.
СУБД Oracle дає можливість скористатися якісним ПО для розробки системи. Також вважається, що дана СУБД гарно підходить для роботи Big Data, що у випадку з нашою системою є великим плюсом.
Логічне та фізичне моделювання бази даних
Для моделювання схеми бази даних був використаний CASE-засіб «Allfusion ErWin Data Modeler». Даний засіб дає можливість змоделювати повноцінні логічну та фізичні моделі даних системи, розділити дані на сутності, визначити зв’язки та обрати структуру сховища даних.
Для почату було розроблено логічну модель, а потім на її основі фізичну. На рисунку 4.6 представлена логічна модель бази даних.
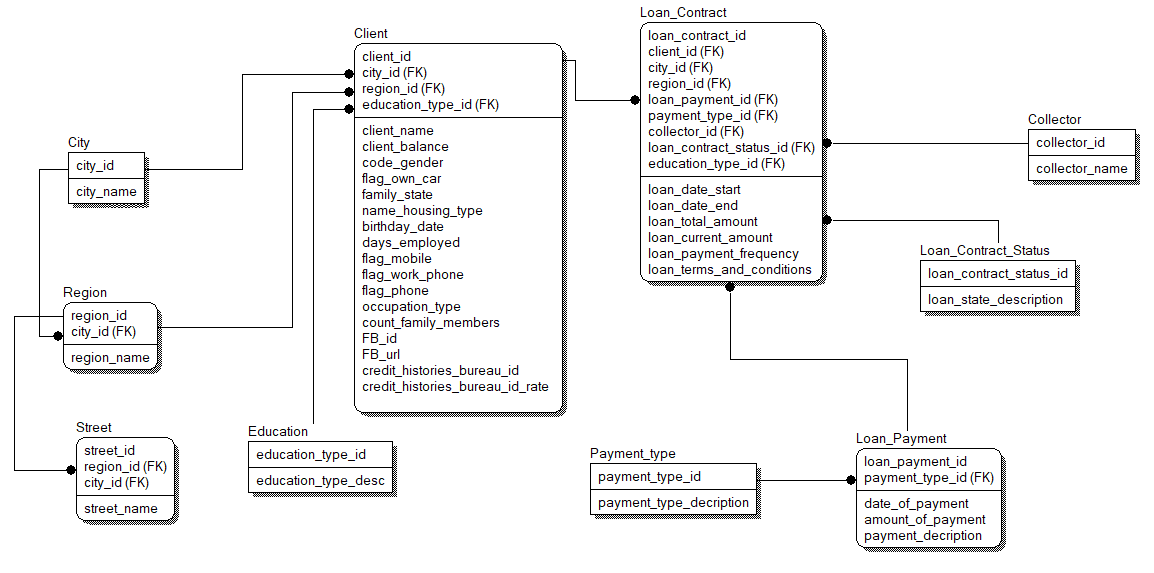
Рис. 4.6 – Логічне моделювання бази даних системи
Сутності, що увійшли до моделі та відповідають предметній області, описані у таблиці 4.1.
Таблиця 3.1 – Сутності БД та опис їх атрибутів
№ |
Назва сутності |
Назва атрибуту |
Опис |
Тип |
1 |
Client |
client_id |
Ідентифікатор клієнта |
PK |
city_id |
Ідентифікатор міста |
FK |
||
region_id |
Ідентифікатор району |
FK |
||
education_type_id |
Ідентифікатор типу освіти |
FK |
||
client_name |
Ім’я клієнта |
|
||
client_balance |
Баланс клієнта |
|
||
code_gender |
Стать клієнта |
|
||
flag_own_car |
Флаг наявності авто |
|
||
family_state |
Сімейний статус |
|
||
name_housing_type |
Тип проживання |
|
||
birthday_date |
Дата народження |
|
||
days_employed |
Днів праці |
|
||
flag_mobile |
Флаг наявності мобільного |
|
||
flag_work_phone |
Флаг наявності робочого телефону |
|
||
flag_phone |
Флаг наявності телефону |
|
||
occupation_type |
Тип професії |
|
||
count_family_members |
Кількість членів родини |
|
||
fb_id |
Facebook ідентифікатор |
|
||
fb_url |
Facebook посилання |
|
||
credit_histories_bureau_id |
Ідентифікатор користувача в Бюро Кредитних Історій |
|
||
credit_histories_bureau_rate |
Рейтинг користувача в Бюро кредитних історій |
|
||
2 |
Loan_Contract |
loan_contract_id |
Ідентифікатор контракту позики |
PK |
client_id |
Ідентифікатор клієнта |
FK |
||
city_id |
Ідентифікатор міста |
FK |
||
region_id |
Ідентифікатор району |
FK |
||
loan_payment_id |
Ідентифікатор оплати |
FK |
||
payment_type_id |
Ідентифікатор типу оплати |
FK |
||
collector_id |
Ідентифікатор колектору |
FK |
||
loan_contract_status_id |
Ідентифікатор статусу контракту |
FK |
||
education_type_id |
Ідентифікатор типу освіти |
FK |
||
loan_date_start |
Дата укладення контракту |
|
||
loan_date_end |
Дата закінчення дії контракту |
|
||
loan_total_amount |
Повна сума позики |
|
||
loan_current_amount |
Сума, що залишилось повернути |
|
||
loan_payment_frequency |
Термін повторності платежів |
|
||
loan_terms_and_conditions |
Інформація та умови кредитування |
|
||
3 |
Loan_Contract_Status |
loan_contract_status_id |
Ідентифікатор статусу контракту |
PK |
loan_state_description |
Опис статусу |
|
||
4 |
Loan_Payment |
loan_payment_id |
Ідентифікатор платежу |
PK |
payment_type_id |
Ідентифікатор типу платежу |
FK |
||
amount_of_payment |
Сума платежу |
|
||
payment_decription |
Інформація про платіж |
|
||
date_of_payment |
Дата платежу |
|
||
5 |
Payment_type |
payment_type_id |
Ідентифікатор типу платежу |
PK |
payment_type_decription |
Опис типу платежу |
|
||
6 |
Collector |
collector_id |
Ідентифікатор колектору |
PK |
collector_name |
Ім’я колектору |
|
||
7 |
Education |
education_type_id |
Ідентифікатор типу освіти |
|
education_type_desc |
Опис типу освіти |
|
||
8 |
City |
city_id |
Ідентифікатор міста |
PK |
city_name |
Назва міста |
|
||
9 |
Region |
region_id |
Ідентифікатор району |
PK |
city_id |
Ідентифікатор міста |
FK |
||
region_name |
Назва району |
|
||
10 |
Street |
street_id |
Ідентифікатор вулиці |
PK |
region_id |
Ідентифікатор району |
FK |
||
city_id |
Ідентифікатор міста |
FK |
||
street_name |
Назва вулиці |
|
Також за допомогою CASE засобу була згенерована фізична модель бази даних, на основі логічної, шо представлена на рисунку 4.7.
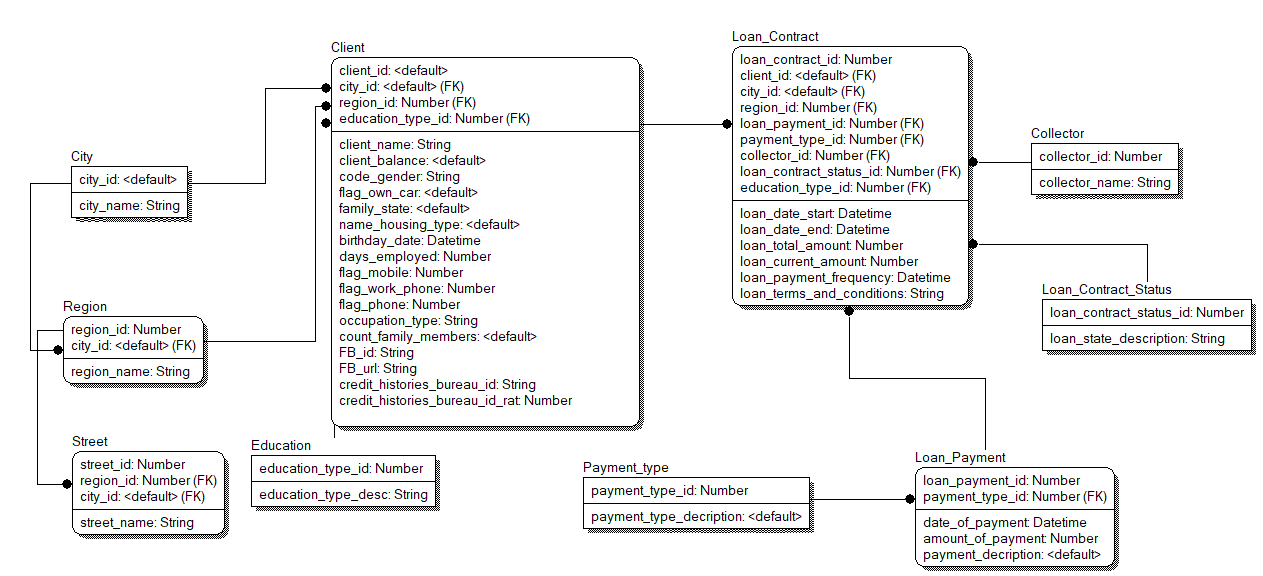
Рис.4.7 – Фізична модель бази даних
Отже було проведено логічне та фізичне моделювання бази даних, що буде використовуватися у системі, виділені сутності та зв’язки. Також, так як Oracle – реляційний тип БД, з метою усунення недоліків структури, було проведено нормалізацію відношень до 3-ої нормальної форми.
Вибір мови програмування
Для розробки клієнтської частини системи було обрано мову JavaScript, та фреймворк для роботи – Angular 2+. JavaScript популярна мова високого рівня доступу, що використовується для написання клієнтських інтерфейсів. Прямим напрямом використання цієї мови є побудова динамічних веб-сайтів. JavaScript може додавати, змінювати та видаляти різний контент з веб-сторінки, а також відправляти асинхронні запити до серверу та обробляти відповіді на ці запити. Також JavaScript приймає специфікації ECMAScript, що означає, що він відповідає загальноприйнятим стандартам програмування у всьому світі. Спілкування з серверною частиною буде відбуватися за протоколом HTTP, та використовувати його методи GET, PUT, DELETE, POST, OPTIONS, HEAD. Всі запити будуть відправлятися до API, у форматі JSON, що написані на серверній частині додатку, та оброблятися асинхронно. За допомогою фреймворку Angular 2+, час розробки клієнтської частини буде менший ніж, якби розробка велась на чистому JavaScript.
Для розробки серверної частини системи, було обрано мову Node.js, з огляду її переваг та недоліків. Node.js підтримує асинхронну обробку запитів, двигун V8 та використовує модель подій, яка підвищує швидкість обробки запитів у реальному часі. Однією з найбільших переваг цієї мови є масштабованість, що дозволяє розгортувати додаткові мікросервіси, для того щоб розвивати архітектуру і робити систему більш гнучкою. Також однією з переваг можна вважати, що мова JavaScript використовується для написання і клієнтської частини і серверної, що зменшує поріг входження у розробку системи.
Також потрібно взяти до уваги метод для аналізу клієнтських заявок на отримання банківського кредиту, який найкраще розроблювати на мові Python, та використовувати його найпопулярніші пакети такі як: pandas, numpy та інші. Також мають велике значення алгоритми класифікації, що були обрані для розробки методу, та які мають імплементацію у пакеті sklearn. Отже для розробки методу було обрано мову Python.
Тестування та оцінка отриманих результатів методу
Основним завданням методу є вирішення задачі класифікації за допомогою аналізу даних. У контексті предметної області завдання методу – це класифікація заявок клієнтів банку на отримання банківських кредитів.
Аналізуючи предметну область, та аналізуючи методи інтелектуального аналізу даних, в рамках атестаційної роботи було прийнято рішення застосувати поєднати 2 методи інтелектуального аналізу, а саме CART та SVM для створення нового ансамблевого методу аналізу.
Можливості перевірити роботу методу на справжніх даних не було, тож набір даних був взятий з популярного сервісу Kaggle для Data Mining. Набір даних призначений для аналізу та класифікації, щодо отримання банківських кредитів, який повністю підходить під предметну область у атестаційній роботі.
Для початку необхідно подати дані до методу, програмний код отримання вхідних даних знаходиться у лістингу 5.1, та зразок даних з набору на рисунку 5.1.
Лістинг 5.1 – Програмний код отримання вхідних даних
import pandas as pd
application_record =
pd.read_csv('/kaggle/input/credit-card-approvalprediction/application_record.csv')
application_record.head()

Рис. 5.1 – Приклад даних з набору
Далі проаналізуємо масштаби даних, рисунок 5.2 показує кількість записів та ознак в цілому.
![]()