Материал: 6593
106
1 и 0, записываем кодовые обозначения, пользуясь следующим правилом: чтобы получить кодовое слово, соответствующее сообщению u4, проследим переход u4 в группировку с наибольшей вероятностью, кодовые символы записываем справа налево (от младшего разряда к старшему), получим 1100.
Для сообщения u1 – 1101 и т.д. (см. рис. 4.3). Оценим эффективность полученного кода. Энтропия источника сообщений:
6
Í (U ) = −∑p(uk )log p(uk ) =
k =1
2η(0,25) +η(0,2) +η(0,15) +η(0,1) +η(0,05) = 2,4232 áèò
на одну букву на выходе источника.
Средняя длина кодового слова (формула (4.2.3))
6
L = ∑lk p(uk ) = 2 0,25 + 2 0,25 +
k =1
2 0,2 +3 0,15 + 4 0,1+ 4 0,05 = 2,45 дв. сим в/букву.
Для оценки эффективности кода используем коэффициент эффективности γ = Í (U )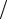 (L log m).
(L log m).
Для оптимального двоичного кода Н(U) = L и γ =1. Полученный нами код имеет γ = 2,4232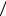 2,45 = 0,9891,
2,45 = 0,9891,
избыточность R=0,0109, т.е. код близок к оптимальному. Пример 4.2.2. Сообщение источника X составляется из
статистически независимых букв, извлекаемых из алфавита А, В, С с вероятностями 0,7; 0,2; 0,1. Произвести двоичное кодирование по методу Шеннона-Фано отдельных букв и двухбуквенных блоков. Сравнить коды по их эффективности.
Решение. Производим побуквенное кодирование методом Шеннона-Фано.
1)Располагаем буквы алфавита источника в порядке убывания вероятностей.
2)Делим алфавит источника на две (m=2) примерно рав-
новероятные группы. Всем сообщениям верхней группы (буква А) приписываем в качестве первого кодового символа 1, всем сообщениям нижней группы приписываем символ 0.
3) Производим второе разбиение на две группы (буквы В и
107
С) и снова букве в верхней группе (В) приписываем символ 1, а в нижней (С) в качестве второго символа кодового слова приписываем 0. Так как в каждой группе оказалось по одной букве, кодирование заканчиваем. Результат приведен в табл. 4.2.2.
Таблица 4.2.2 Оценим эффективность полученного кода. Энтропия
xj |
p(xj) |
Разби- |
Кодовое |
источника |
|
|
|
ения |
слово |
s |
|
A |
0,7 |
______ |
1 |
||
Í (Õ) = −∑p(xk )log2 p(xk ) = |
|||||
B |
0,2 |
__ |
01 |
||
C |
0,1 |
|
00 |
k =1 |
|
|
|
η(0,7) +η(0,2) +η(0,1) =1,1568 бит/букву.
Средняя длина кодового слова
s
L = ∑lk p(xk ) = 0,7 1+0,2 2 +0,1 2 =1,3 бит/букву.
k =1
Видим, что L>H(X), и коэффициент эффективности
γ1 =1,1568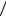 1,3 = 0,8898, а избыточность R1=0,1102.
1,3 = 0,8898, а избыточность R1=0,1102.
Покажем, что кодирование блоками по 2 буквы (k=2) увеличивает эффективность кода. Строим вспомогательный алфавит из N=32 блоков. Вероятности блоков находим по формуле (4.2.4), считая буквы исходного алфавита независимыми. Располагаем блоки в порядке убывания вероятностей и осуществляем кодирование методом Шеннона-Фано. Все полученные двухбуквенные блоки, вероятности их и соответствующие кодовые обозначения сведены в табл. 4.2.3.
При блоковом кодировании средняя длина кодового слова на одну букву
L2 = L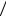 2 = 0,5(1 0,49 +3 2 0,14 + 4 2 0,07 + 4 0,04 + 5 0,02 +6 0,02 +6 0,01) =1,165 бит/букву.
2 = 0,5(1 0,49 +3 2 0,14 + 4 2 0,07 + 4 0,04 + 5 0,02 +6 0,02 +6 0,01) =1,165 бит/букву.
При этом коэффициент эффективности
γ2 = Í (Õ) L2 =1,1568
L2 =1,1568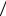 1,165 = 0,9955.
1,165 = 0,9955.
Избыточность при двухбуквенном кодировании R2=0,0045. Получили γ2 > γ1, R2 <<R1, что и требовалось показать.
108
Таблица 4.2.3
Двухбук- |
Вероят- |
|
Кодовые |
венные |
ности |
Разбиения |
слова |
блоки |
|
|
|
АА |
0,49 |
______________ |
1 |
АВ |
0,14 |
__________ |
0 1 1 |
ВА |
0,14 |
____________ |
0 1 0 |
АС |
0,07 |
________ |
0 0 1 1 |
СА |
00,7 |
__________ |
0 0 1 0 |
ВВ |
0,04 |
________ |
0 0 0 1 |
ВС |
0,02 |
______ |
0 0 0 0 1 |
СВ |
0,02 |
____ |
0 0 0 0 0 1 |
СС |
0,01 |
|
0 0 0 0 0 0 |
Пример 4.2.3. Закодировать двоичным кодом Лемпела– Зива двоичное сообщение 0010101000101. Номера комбинаций в кодовой таблице состоят из трех битов.
Решение.
На рис. 4.4 показаны двоичные последовательности на входе и выходе кодера, причем ради наглядности они разбиты на части, соответствующие отдельным шагам. Сплошные линии указывают, какие номера извлекаются из кодовой таблицы и подаются на выход кодера. Штриховые линии показывают путь внесения очередных записей в кодовую таблицу (первая запись
Вход |
0 |
01 |
010 |
1 |
00 |
0101 |
Выход |
0000 |
0011 |
0100 |
0001 |
0010 |
0111 |
Отрезок Номер
-000
0 |
001 |
01 |
010 |
010 |
011 |
1 |
100 |
00 |
101 |
0101 |
110 |
Рис. 4.4 – Пример кодирования кодом Лемпела–Зива
109
“пробел” и его номер 000 внесены в таблицу заранее). Убедитесь, что по передаваемой последовательности в пункте приема можно в том же порядке заполнять кодовую таблицу и декодировать сигнал.
ЗАДАЧИ
4.2.1. Убедиться в том, что при кодировании двоичным кодом Шеннона-Фано сообщений источника, заданного табл. 4.2.4, может быть достигнута длина кодового слова, удовлетво-
ряющая условию Lmin = H (X )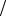 log m .
log m .
Сравнить полученный код с равномерным кодом.
Таблица 4.2.4
|
|
xj |
|
|
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
|
|
x8 |
|
|
|
|
р(хj) |
1/2 |
1/4 |
1/8 |
1/16 |
1/32 |
1/64 |
1/128 |
|
1/128 |
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
4.2.2. |
Источник статистически независимых сообщений за- |
|||||||||||||
дан табл. 4.2.5. |
|
|
|
|
|
Таблица 4.2.5 |
||||||||||
|
|
|
|
|
|
|
|
|
|
|
||||||
|
xj |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
x8 |
|
x7 |
x7 |
|
|||
|
р(хj) |
1/4 |
1/ |
1/ |
1/ |
1/1 |
1/1 |
1/1 |
1/3 |
1/6 |
1/6 |
|
||||
|
|
|
|
|
4 |
8 |
8 |
6 |
6 |
6 |
2 |
4 |
4 |
|
||
Закодировать сообщения источника двоичным кодом так, чтобы средняя длина кодового слова была минимальна. Оценить эффективность полученного кода.
4.2.3. Ансамбль сообщений задан табл. 4.2.6.
|
|
|
|
|
|
|
Таблица 4.2.6 |
||
xj |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
x8 |
|
р(хj) |
0,2 |
0,25 |
0,15 |
0,1 |
0,05 |
0,05 |
0,14 |
0,06 |
|
Сообщения источника статистически независимы. Передача производится по двоичному каналу. Длительности символов кодированного сигнала одинаковы τ0=τ1=τ. Определить скорость передачи информации при использовании равномерного кода и кода Шеннона-Фано. Сравнить коды по их эффективности.
4.2.4. Закодировать статистически независимые сообщения источника (табл. 4.2.7) двоичным кодом Хафмана. Найти вероятности появления нулей и единиц в полученной последо-

110
вательности.
Таблица 4.2.7
xj |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
р(хj) |
0,25 |
0,23 |
0,15 |
0,12 |
0,1 |
0,08 |
0,07 |
4.2.5. Закодировать двоичным кодом Шеннона-Фано алфавит источника, состоящий из четырех букв (А, В, С, Д) с ве - роятностями 0,28; 0,14; 0,48 и 0,1 соответственно. Оценить эффективность полученного кода.
4.2.6. Сколько вопросов в среднем надо задать, чтобы отгадать задуманное собеседником целое положительное число, не превосходящее 10, если спрашиваемый на все вопросы отвечает лишь «да» или «нет»?
4.2.7. Известно, что жители некоторого города А всегда говорят правду, а жители соседнего города Б всегда обманывают. Наблюдатель Н знает, что он находится в одном из этих двух городов, но не знает, в каком именно. Путем опроса встречного ему требуется определить: а) в каком городе он находится, б) в каком городе живет его собеседник (в каждом пункте можно с одинаковой вероятностью встретить жителей обоих городов), в) то и другое вместе.
Каково наименьшее число вопросов, которые должен задать Н, если на все вопросы Н встречный отвечает лишь «да» или
«нет»?
4.2.8. Сообщение на выходе источника без памяти состоит из букв, принимающих значение А и В с вероятностями 0,7 и 0,3. Произвести кодирование по методу Шеннона-Фано отдельных букв, двух- и трехбуквенных блоков. Сравнить коды по их эффективности.
4.2.9. Имеются три города (А, Б и В), причем жители А всех случаях говорят правду, жители Б – только неправду, а жители В через раз отвечают на вопросы верно и неверно. Наблюдатель Н хочет выяснить, в каком городе он находится и в каком городе живет встреченный им человек. Сколько вопросов ему потребуется задать этому встречному, если на все вопросы он отвечает лишь «да» или «нет»?
4.2.10. Некто задумал два различных целых положительных числа, не превосходящих четырех. Сколько в среднем надо за-