Материал: 6593
101
Кодирующее устройство должно удовлетворять двум основным требованиям:
1)обеспечивать безошибочную передачу информации, т.е. взаимно однозначное соответствие между Х(t) и А(t) (см. рис.
4.1.1);
2)осуществлять кодирование наиболее экономным образом (с минимальной избыточностью).
Для выполнения первого требования необходимо, во-пер- вых, чтобы различным буквам алфавита источника соответст-
вовали различные кодовые слова и, во-вторых, была предусмотрена возможность разделения кодовых слов при их последовательной передаче.
Для осуществления возможности разделения кодовых слов применяется одна из следующих мер:
1)использование специальной буквы;
2)применение кодовых слов одинаковой длины без разделительных букв – равномерное кодирование;
3)кодовая таблица составляется так, чтобы никакое кодовое слово не являлось началом другого, более длинного.
Требование экономичности заключается в том, что необходимо добиваться при кодировании минимальной средней длины
кодового слова
s |
|
L = ∑lk p(xk ) , |
(4 |
k =1 |
.2.3) |
|
где lk – длина k-го кодового слова с учетом разделительной
буквы, если таковая используется.
Средняя длина кодового слова ограничена снизу, так как для безошибочной передачи информации необходимо выполнение соотношения Н<С. Это обстоятельство сформулировано в теореме Шеннона о кодировании в дискретных каналах без шумов.
Теорема Шеннона. При кодировании множества сигналов с энтропией Н(Х) при условии отсутствия шумов средняя длина
кодового слова не может быть меньше чем Нlog(Хm) , где m –
основание кода. Если вероятности сигналов не являются цело-
102
численными отрицательными степенями числа m, то точное достижение указанной нижней границы невозможно, но при кодировании достаточно длинными блоками к ней можно cколь угодно приблизиться.
Существует несколько способов, позволяющих получать коды с малой избыточностью, причем все они обладают следующими свойствами.
1) Более вероятным буквам источника соответствуют более короткие кодовые слова (принцип статистического кодирования).
2)Никакое кодовое слово не является началом другого, более длинного.
3)Все буквы алфавита, используемого для передачи по ка-
налу, приблизительно равновероятны.
4) Символы в последовательности на выходе кодера практически независимы.
Наилучшим среди этих кодов является код, предложенный Д.А. Хафманом.
Код Хафмана. Кодирование алфавита, состоящего из s букв, по методу Хафмана осуществляется следующим образом.
1)Буквы алфавита источника располагаем в порядке убывания их вероятностей.
2)Выбираем целое число m0, такое, что
2 ≤ m0 ≤ m и (s −m0 )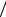 (m −1) = a ,
(m −1) = a ,
где а – целое положительное число.
При кодировании в двоичном канале m0 = m = 2. Производим первое сжатие алфавита, т.е. группируем вмес-
те m0 букв алфавита источника, имеющих наименьшие вероятности, и обозначаем новой буквой. Вычисляем общую вероятность такого сгруппированного подмножества букв.
3)Буквы нового алфавита, полученного в результате первого сжатия, снова располагаем в порядке убывания вероятностей.
4)Производим второе сжатие этого алфавита, т.е. снова
группируем вместе m букв, имеющих наименьшие вероятности, и обозначаем новой буквой. Вычисляем общую вероятность сгруппированного подмножества букв.
103
5)Буквы нового алфавита, полученного на 4-м шаге, располагаем в порядке убывания вероятностей.
6)Осуществляем последовательные сжатия алфавита путем повторения операций 4 и 5, пока в новом алфавите не останется единственная буква.
7)Проводим линии, которые соединяют буквы, образующие последовательные вспомогательные алфавиты. Получается дерево, в котором отдельные сообщения являются концевыми узлами. Соответствующие им кодовые слова получаем, если
приписать различные буквы m-ичного алфавита ветвям, исходящим из каждого промежуточного узла.
Код Хафмана имеет среднюю длину кодового слова, не большую чем любой другой код.
Код Шеннона-Фано. Кодирование осуществляется следующим образом.
1)Буквы алфавита источника располагаем в порядке убывания вероятностей.
2)Делим алфавит источника на m групп так, чтобы общие вероятности букв в каждой из групп были примерно равны. В качестве первого символа кодового слова выбираем 0,1, ..., m-1 в зависимости от того, в которой из групп оказалась кодируемая
буква.
3) Каждую из групп снова разбиваем на m примерно равновероятных подгрупп и в качестве второго символа кодового слова выбираем 0,1, …, m-1 в зависимости от того, в которой из подгрупп оказалась кодируемая буква.
4) Такое разбиение на все более мелкие группы проводится до тех пор, пока в каждой из групп не окажется по одной букве.
Блоковое кодирование. Выше были рассмотрены способы побуквенного кодирования, когда каждой букве на выходе источника приписывалось свое кодовое слово. Такой способ кодирования позволяет достигнуть минимальной средней длины ко-
дового слова, равной Í (Õ)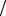 log m , только в том случае, когда
log m , только в том случае, когда
вероятности букв являются отрицательными целочисленными степенями числа m. Если вероятности не удовлетворяют этому требованию, избыточность при побуквенном кодировании может оказаться недопустимо большой. В таком случае применяют
104
блоковое кодирование.
При кодировании блоками по k букв прежде всего строят вспомогательный алфавит, состоящий из N=sk букв, так что каждой букве этого алфавита соответствует своя комбинация (блок) из k букв алфавита источника. Вероятность буквы zij…q вспомогательного алфавита, соответствующей комбинации xixj…xq, в простейшем случае вычисляется по формуле
p(zij...q ) = p(xi ) p(xj )...p(xq ) . |
(4 |
|
.2.4) |
Далее буквы вспомогательного алфавита располагаются в порядке убывания вероятностей, и осуществляется кодирование методом Шеннона-Фэно или Хафмана.
Таким образом, кодирующее устройство при блоковом кодировании разбивает последовательность букв на выходе ис - точника на блоки длиной в k букв каждый и генерирует последовательность кодовых слов, соответствующих каждому из блоков.
Главный недостаток обоих кодов заключаются в том, что для их применения нужно знать вероятности появления букв
(или их комбинаций при кодировании блоками).
Код Лемпела–Зива свободен от этого недостатка. Здесь кодовая таблица, изначально почти пустая, заполняется одновременно в пунктах передачи и приема в процессе кодирования (декодирования), причем в эту таблицу вносятся лишь такие все более длинные отрезки передаваемого сообщения, которые еще не встречались ранее. Каждому отрезку в таблице присваивается n-разрядный номер. При внесении очередной записи (строки) в таблицу передается блок, содержащий:
1)номер отрезка, уже имеющегося в таблице;
2)символ, следующий в передаваемом сообщении за этим отрезком.
РЕШЕНИЕ ТИПОВЫХ ПРИМЕРОВ Пример 4.2.1. Закодировать сообщения источника, при-
веденные в табл 4.2.1, двоичным кодом Хафмана. Оценить эффективность полученного кода.

105
|
|
|
|
Таблица |
4.2.1 |
Решение. В |
|
uk |
u1 |
u2 |
u3 |
u4 |
u5 |
u6 |
|
|
|
|
|
|
|
|
соответствии с ал- |
p(uk) |
0,1 |
0,2 |
0,25 |
0,05 |
0,25 |
0,15 |
|
горитмом построения кода Хафмана делаем последовательно следующие шаги:
1)располагаем сообщения источника в порядке убывания вероятностей;
2)образуем вспомогательный алфавит, объединяя наиболее
маловероятные буквы u1 и u4 (m0=2), тогда вероятность новой буквы равна p1=р(u1)+р(u4)=0,1+0,05=0,15. Оставляем эту букву
на месте, так как p1=р(u6);
3)объединяем первую вспомогательную букву и букву u6, тогда вероятность второй вспомогательной буквы равна р2=р1+р(u6)=0,15+0,15=0,3; перемещаем ее вверх в соответствии
сэтой вероятностью;
4)объединение продолжаем до тех пор, пока в ансамбле не останется единственное сообщение с вероятностью единица.
Построение кода Хафмана приведено на рис. 4.3.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,55 |
1 |
|
||
|
|
|
|
|
|
|
|
|
|
|
0,45 |
|
|
|
|
|
|
|
|
|
1,00 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
Комби- |
uj |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
0 |
|
|||||||
нация |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,30 |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
10 |
u3 |
|
|
0,25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
01 |
u5 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
0,25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
00 |
u2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
0,20 |
|
0 |
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
111 |
u6 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
0,15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
1101 |
u1 |
|
|
0,10 |
|
0,15 |
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
||||
1100 |
u4 |
|
|
|
|
|
|
|
|
|
|
|
|||||||||||
|
0,05 |
|
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 4.3
Сообщения источника являются теперь концевыми узлами кодового дерева. Приписав концевым узлам значения символов