Материал: 2488
|
|
|
|
|
Таблица 4 |
|
Сравнение характеристик и аналогичных систем |
||||||
|
|
|
|
|
|
|
|
|
Название информационной системы |
||||
|
|
|
|
|
|
|
|
АИПС |
Справочная |
АС |
ГИС |
Комплексная |
|
Характе- |
«Отчет |
информаци- |
«Учет |
«Доро- |
АС управления |
|
БДД и |
онно- |
ДТП» в |
ги Юг- |
автомобиль- |
||
ристики систем |
||||||
ГАИ |
аналитическая |
г. Санкт- |
ры» |
ными дорогами |
||
|
КРАЙ» |
с-ма гос. ин- |
Петер- |
|
|
|
|
|
спекции по |
бурге |
|
|
|
|
|
БДД |
|
|
|
|
Совместимость |
+ |
- |
- |
- |
+ |
|
с СУБД Oracle |
|
|
|
|
|
|
|
|
|
|
|
|
|
Формирование |
4 |
4 |
4 |
4 |
5 |
|
|
|
|
|
|||
обобщенных |
|
|
|
|
|
|
сведений по за- |
|
|
|
|
|
|
просам |
|
|
|
|
|
|
|
|
|
|
|
|
|
Формирование |
4 |
4 |
4 |
4 |
5 |
|
|
|
|
|
|||
пакетов отчет- |
|
|
|
|
|
|
ности в выше- |
|
|
|
|
|
|
стоящие орга- |
|
|
|
|
|
|
ны |
|
|
|
|
|
|
|
|
|
|
|
|
|
Интерфейс |
4 |
5 |
4 |
5 |
4 |
|
|
|
|
|
|||
пользователя |
|
|
|
|
|
|
|
|
|
|
|
|
|
Поиск темати- |
4 |
5 |
4 |
4 |
3 |
|
|
|
|
|
|||
ческих рубрик |
|
|
|
|
|
|
|
|
|
|
|
|
|
Возможность |
4 |
4 |
3 |
5 |
5 |
|
|
|
|
|
|||
представления |
|
|
|
|
|
|
информации в |
|
|
|
|
|
|
графическом |
|
|
|
|
|
|
виде |
|
|
|
|
|
|
|
|
|
|
|
|
|
Функциональ- |
5 |
4 |
4 |
4 |
5 |
|
|
|
|
|
|||
ные возможно- |
|
|
|
|
|
|
сти |
|
|
|
|
|
|
|
|
|
|
|
|
|
Были внедрены |
+ |
+ |
+ |
+ |
+ |
|
|
|
|
|
|||
в подобных ор- |
|
|
|
|
|
|
ганизациях |
|
|
|
|
|
|
|
|
|
|
|
|
|
Итого |
25 |
26 |
23 |
26 |
27 |
|
|
|
|
|
|||
|
|
|
|
|
|
|
116
Это можно объяснить тем, что информационно-аналитические системы (ИАС) объединяют, анализируют и хранят как единое целое информацию, извлекаемую как из учетных баз данных организации, так и из внешних источников. Входящие в состав информационноаналитических систем хранилища данных обеспечивают преобразование больших объемов сильно детализированных данных в обобщенную выверенную информацию, которая пригодна для принятия обоснованных решений. В отличие от обычных баз данных хранилища содержат обработанное, упорядоченное и понятное руководителям представление данных. Хранилище данных является сборочным конвейером по подготовке информации в интегрированном, непротиворечивом, наглядном виде для поддержки принятия управленческих решений.
Современные СППР, построенные на основе хранилищ данных, предполагают организацию анализа на основе единого информационного пространства, в которое стекаются данные из действующих систем оперативной обработки информации (СОД). При этом информация в хранилище пополняется регулярно и располагается в хронологическом порядке. В основе поддержки принятия решений на основе технологии хранилища данных лежат три концепции:
1)гибкая навигация по хранилищу данных с целью генерации нерегламентированных запросов и представление результатов в виде различных отчетов, а также в случае необходимости отображение их через геоинформационный интерфейс на топологической основе;
2)многомерный анализ данных, позволяющий организовать агрегированную информацию из хранилища в виде гиперкубической модели и обеспечить ее удобный просмотр и анализ, включая формирование кросс-табличных отчетов, диаграмм деловой графики, раскрашенных определенным образом карт. При этом в ячейках гиперкуба хранятся числовые значения агрегированных показателей, а измерения позволяют упорядочить данные в соответствии с хронологической, географической и другими классификациями на основе справочников хранилища;
3)поиск зависимостей в накопленной информации на основе алгоритмов интеллектуального анализа данных.
Используя средства поддержки принятия решений, можно решать такие задачи, как мониторинг состояния ресурсов области, проверка гипотез, анализ и прогнозирование событий, поиск зависимостей, из которых можно извлекать новые сведения, выявлять аномалии, моде-
117
лировать процессы. Современные системы поддержки принятия решений обеспечивают удобный пользовательский интерфейс, ориентированный на комплексный анализ накопленной информации.
Хранилище данных (англ. Data Warehouse) – очень большая предметно-ориентированная информационная корпоративная база данных, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес-процессов с целью поддержки принятия решений в организации. Хранилище данных строится на базе клиентсерверной архитектуры, реляционной СУБД и утилит поддержки принятия решений. При разработке КСППР важное значение играет выбор модели хранилища данных. Хранилище данных существует на основе реляционной СУБД, следовательно, можно говорить о КСППР как о ROLAP-системе. В этой структуре можно хранить очень большие объемы данных.
Принципиальное отличие КСППР на основе хранилищ данных от интегрированной системы управления предприятием состоит в обязательном наличии метаданных. Метаданные в КСППР, как правило, помещаются в централизованно управляемый репозиторий, в который включаются информация о структуре данных хранилища, структурах данных, импортируемых из различных источников, методы загрузки и агрегирования данных, сведения о средствах доступа, а также правила оценки и представления информации.
При создании системы управления метаданными необходимо решать следующие задачи:
1)анализ процессов возникновения, изменения и использования метаданных;
2)проектирование структуры хранения метаданных (например, в составе реляционной базы данных);
3)организация прав доступа к метаданным;
4)разделение метаданных между витринами данных;
5)согласование метаданных ХД с репозиториями;
6)реализация пользовательского интерфейса с репозиторием.
В дальнейшем необходимо заполнить хранилище данными. Для этого необходимо провести сбор, очистку и агрегирование данных. При детальном изучении структуры КСППР можно сказать, что для решения задач учета и анализа ДТП необходимо использовать двухуровневое хранилище данных. Информация поступает из источников данных в хранилище, где обрабатывается. На рис. 17 представлена схема двухуровневого хранилища данных.
118
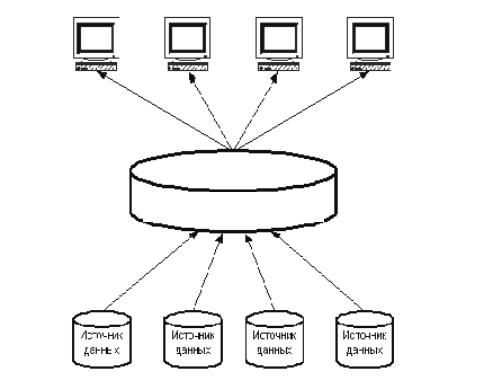
Хранилище данных
Источник |
|
Источник |
|
Источник |
|
Источник |
данных |
|
данных |
|
данных |
|
данных |
|
|
|
|
|
|
|
Рис. 17. КСППР как двухуровневое хранилище данных
При реализации данного вида хранилища данных в КСППР может возникнуть проблема с разграничением прав доступа пользователей на доступ к информации.
В качестве источников данных для информационно-анали- тической системы выступают операционные данные, то есть данные, обрабатываемые существующими автоматизированными системами. Эти системы собирают огромные количества детализированных данных, необходимых для ежедневной работы. Можно выделить следующие характеристики операционных данных:
-данные структурируются для оптимизации производительности
ихранения, а не для нестандартных запросов или аналитических отчетов;
-данные распределены между различными доставшимися по наследству разнородными системами, разработанными в разное время;
-при разработке информационных систем применялись различные технологии хранения данных, которые не могут обеспечить быстрый и прозрачный доступ к ним;
-отсутствие единой стратегии в проектировании хранилищ данных часто приводит к тому, что на каждом отрезке времени принимаются различные обозначения для одних и тех же элементов дан-
119
ных.
Метаданные – это буквально данные о данных. Метаданные не несут информации, но описывают атрибуты данных, содержащих сведения. Метаданные размещаются в репозитории в форме таблиц базы данных, и их сопровождение осуществляется централизованно. Их назначение – контроль непротиворечивости атрибутов данных в процессе функционирования системы и облегчение управления данными путем корректировки атрибутов централизованно в одном месте. При этом результаты корректировки будут автоматически распространены на все необходимые приложения.
В совокупности метаданные в КСППР нужны двум категориям пользователей: разработчикам и конечным пользователям. Метаданные на уровне конечного пользователя в явном виде представляют описание данных в хранилище в терминах предметной области. Одно из основных назначений метаданных – повышение эффективности поиска. Поисковые запросы, использующие метаданные, делают возможным выполнение достаточно сложных операций по фильтрации и отбору данных, что немаловажно при решении задач анализа и учета ДТП.
Для того чтобы построить структуру хранилища данных, необходимо воспользоваться OLAP технологией. Входные данные разбиваются на потоки информации и играют важную роль при формировании данной системы. Рассмотрим каждый поток и выделим конкретные данные, необходимые для решения поставленной проблемы.
Для потока «Вид, место и схема ДТП» необходимо сформировать следующие данные: значение дороги (федеральная, территориальная, ведомственная, частная, иная, другие места); категория дороги; расстояние (километры, метры); статус населенного пункта (областной центр, райцентр, иной населенный пункт, вне городов или населенных пунктов); населенный пункт; район, улица; категория улицы (магистральная дорога, магистральная улица, улица районного значения, прочие улицы, иные места); вид ДТП (столкновение, опрокидывание, наезд на стоящее транспортное средство, наезд на препятствие, наезд на пешехода, наезд на велосипедиста, иной вид ДТП); количество транспортных средств, участвующих в ДТП; количество участников ДТП; количество погибших, количество раненых; схема ДТП; дополнительные сведения о ДТП.
Для потока «Дорожные условия» необходимо сформировать следующие данные: элементы плана и профиля дороги (прямая в плане,
120