Материал: 2329
Лабораторная работа №5. Поиск ассоциативных правил
5.1. Основная цель
Научиться выявлять ассоциативные правила с помощью АП
«Deductor».
5.2.Теоретическая часть
Впоследнее время неуклонно растет интерес к методам «обнаружения знаний в базах данных». Объемы современных баз данных, которые весьма внушительны, вызвали устойчивый спрос на новые масштабируемые алгоритмы анализа данных. Одним из популярных методов обнаружения знаний стали алгоритмы поиска ассоциативных правил.
Ассоциативные правила позволяют находить закономерности между связанными событиями. Примером такого правила, служит утверждение, что покупатель, приобретающий хлеб, приобретет и молоко с вероятностью 75 %. Первый алгоритм поиска ассоциативных правил, называвшийся AIS, был разработан в 1993 году сотрудниками исследовательского центра IBM Almaden. На середину 90-х годов прошлого века пришелся пик исследовательских работ в этой области.
Ассоциативные правила (Association Rules)
Впервые эта задача поиска ассоциативных правил была предложена для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины.
Пусть имеется база данных, состоящая из покупательских транзакций. Каждая транзакция - это набор товаров, купленных покупателем за один визит. Такую транзакцию еще называют рыночной корзиной.
Покажем на конкретном примере: «75 % транзакций, содержащих хлеб, также содержат молоко. 3 % от общего числа всех транзакций содержат оба товара». 75 % - это достоверность правила, 3 % - это поддержка, или хлеб, молоко с вероятностью 75 %.
43
Другими словами, целью анализа является установление следующих зависимостей: если в транзакции встретился некоторый набор элементов x, то на основании этого можно сделать вывод о том, что другой набор элементов y также должен появиться в этой транзакции. Установление таких зависимостей дает нам возможность находить очень простые и интуитивно понятные правила.
Алгоритмы поиска ассоциативных правил предназначены для нахождения всех правил x y, причем поддержка и достоверность этих правил должны быть выше некоторых наперед определенных порогов, называемых соответственно минимальной поддержкой и минимальной достоверностью.
Задача нахождения ассоциативных правил разбивается на две подзадачи:
1.Нахождение всех наборов элементов, которые удовлетворяют порогу минимальной поддержки. Такие наборы элементов называются часто встречающимися.
2.Генерация правил из наборов элементов, найденных согласно п.1 с достоверностью, удовлетворяющей порогу минимальной достоверности.
Один из первых алгоритмов, эффективно решающих подобный класс задач, – это алгоритм APriori. Кроме этого алгоритма в последнее время был разработан ряд других алгоритмов: DHP, Partition, DIC и другие.
Значения для параметров минимальная поддержка и минимальная достоверность выбираются таким образом, чтобы ограничить количество найденных правил. Если поддержка имеет большое значение, то алгоритмы будут находить правила, хорошо известные аналитикам или настолько очевидные, что нет никакого смысла проводить такой анализ. С другой стороны, низкое значение поддержки ведет к генерации огромного количества правил, что, конечно, требует существенных вычислительных ресурсов. Тем не менее большинство интересных правил находится именно при низком значении порога поддержки. Хотя слишком низкое значение поддержки ведет к генерации статистически необоснованных правил.
Поиск ассоциативных правил совсем не тривиальная задача, как может показаться на первый взгляд. Одна из проблем - алгоритмическая сложность при нахождении часто встречающихся наборов элементов, т.к. с ростом числа элементов в I (| I |) экспоненциально растет число потенциальных наборов элементов.
44
Рассмотрим еще некоторые понятия.
Транзакция - множество событий, произошедших одновременно. В нашем случае, каждая транзакция - набор товаров, купленных покупателем за один визит.
Минимальная и максимальная поддержка. Ассоциативные правила ищутся только в некотором множестве всех транзакций. Для того чтобы транзакция вошла в это множество, она должна встретиться в исходной выборке количество раз, большее минимальной поддержке и меньше максимальной.
Уменьшение минимальной поддержки приводит к тому, что увеличивается количество потенциально интересных правил, однако это требует существенных вычислительных ресурсов. Одним из ограничений уменьшения порога минимальной поддержки является то, что слишком маленькая поддержка правила делает его статистически необоснованным.
Правило со слишком большой поддержкой с точки зрения статистики представляет собой большую ценность, но с практической точки зрения это, скорее всего, означает то, что, либо правило всем известно, либо товары, присутствующие в нем, являются лидерами продаж, откуда следует их низкая практическая ценность.
Если значение верхнего предела поддержки имеет слишком большое значение, то в правилах основную часть будут составлять товары - лидеры продаж. При таком раскладе не представляется возможным уменьшить минимальный порог поддержки до того значения, при котором могут появляться интересные правила. Причиной тому является просто огромное число правил и, как следствие, нехватка системных ресурсов. Причем получаемые правила процентов на 95 содержат товары - лидеры продаж.
Минимальная и максимальная достоверность. Это процентное отношение количества транзакций, содержащих все элементы, которые входят в правило, к количеству транзакций, содержащих элементы, которые входят в условие. Если транзакция - это заказ, а элемент - товар, то достоверность характеризует, насколько часто покупаются товары, входящие в следствие, если заказ содержит товары, вошедшие во всё правило.
Уменьшение порога достоверности также приводит к увеличению количества правил. Значение минимальной достоверности также не должно быть слишком маленьким, так как
45
ценность правила с достоверностью 5 % настолько мала, что это правило и правилом считать нельзя.
Правило со слишком большой достоверностью практической ценности в контексте решаемой задачи не имеет, т.к. товары, входящие в следствие, покупатель, скорее всего, уже купил.
Максимальная мощность искомых часто встречающихся множеств. Если данный параметр указан (флажок установлен), то максимальная мощность (количество элементов) часто встречающихся множеств будет не больше значения этого параметра. Следовательно, любое результирующее правило будет состоять не больше чем из <максимальная мощность> элементов.
Если задать значение параметра максимальная мощность, то можно искать правила, которые состоят не более чем из <максимальная мощность> количества элементов. Например, если нужны только простые правила для оценочного анализа, то значение максимальной мощности следует установить либо в 2, либо в 3. При этом если максимальная мощность равна 2, то все найденные правила будут иметь вид: «Если ТоварI, то ТоварJ». Ограничение поиска часто встречающихся множеств по мощности (количеству элементов в множестве) может также понадобиться, если при указанном значении минимальной поддержки количество часто встречающихся множеств, имеющих большую мощность, слишком велико.
5.3. Практическая часть
Импортируйте в АП «Deductor» данные файла C:\Program Files\BaseGroup\Deductor\Samples\Supermarket.txt, изменив при этом вид данных столбца «Номер чека» на дискретный.
46
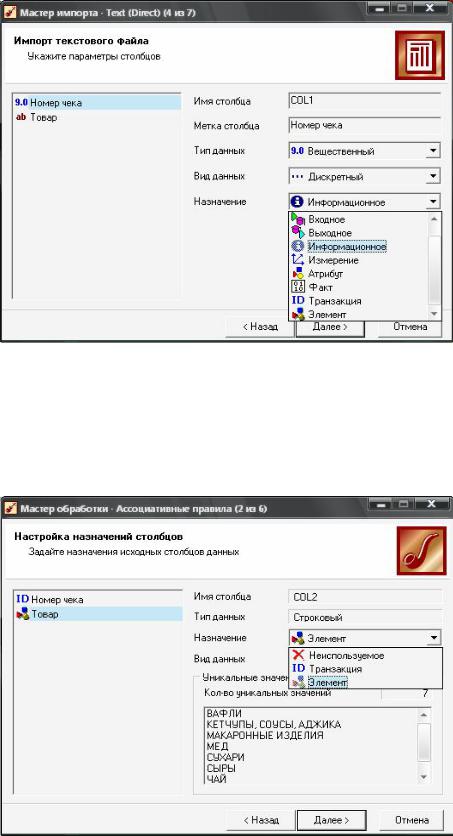
Изменение параметров импорта данных
В разделе “Data Mining” мастера обработки выберите пункт «Ассоциативные правила».
Установите назначение поля «Номер чека» - транзакция, а поля «Товар» - элемент.
Настройка назначения полей
47