Материал: Разработка веб-приложения для прогнозирования временных рядов методом фрактального анализа
б) Логистическая функция (сигмоида, функция Ферми, Рисунок 1.14):
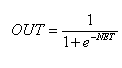
Применяется очень часто для многослойных персептронов и других сетей с непрерывными сигналами. Гладкость, непрерывность функции - важные положительные качества. Непрерывность первой производной позволяет обучать сеть градиентными методами (например, метод обратного распространения ошибки).
Функция симметрична относительно точки (NET=0, OUT=1/2), это делает равноправными значения OUT=0 и OUT=1, что существенно в работе сети. Тем не менее, диапазон выходных значений от 0 до 1 несимметричен, из-за этого обучение значительно замедляется. Данная функция - сжимающая, т.е. для малых значений NET коэффициент передачи K=OUT/NET велик, для больших значений он снижается. Поэтому диапазон сигналов, с которыми нейрон работает без насыщения, оказывается широким.
Значение производной легко выражается через саму функцию. Быстрый расчет производной ускоряет обучение.
в) Гиперболический тангенс (Рисунок 1.15):
![]()
Тоже применяется часто для сетей с непрерывными сигналами. Функция симметрична относительно точки (0,0), это преимущество по сравнению с сигмоидой.
г) Пологая ступенька (Рисунок 1.16):
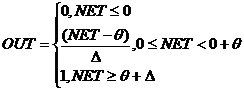
Рассчитывается легко, но имеет разрывную первую производную в точках NET
= Ө , NET = Ө + Δ что усложняет алгоритм обучения.
Выбор функции активации определяется:
а) Спецификой задачи.
б) Удобством реализации на ЭВМ, в виде электрической схемы или другим способом.
в) Алгоритмом обучения: некоторые алгоритмы накладывают ограничения на вид функции активации, их нужно учитывать.
Чаще всего вид нелинейности не оказывает принципиального влияния на решение задачи. Однако удачный выбор может сократить время обучения в несколько раз.
Формальные нейроны могут объединяться в сети различным
образом. Самым распространенным видом сети стал многослойный перcептрон
(Рисунок 1.18 ).
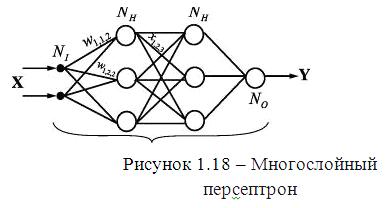
Сеть состоит из произвольного количества слоев нейронов. Нейроны каждого слоя соединяются с нейронами предыдущего и последующего слоев по принципу "каждый с каждым". Первый слой (слева) называется сенсорным или входным, внутренние слои называются скрытыми или ассоциативными, последний (самый правый, на рисунке 1.18 состоит из одного нейрона) - выходным или результативным. Количество нейронов в слоях может быть произвольным. Обычно во всех скрытых слоях одинаковое количество нейронов.
Обозначим количество слоев и нейронов в слое. Входной
слой: NI нейронов; NH нейронов в каждом скрытом слое; NO выходных нейронов. х - вектор входных
сигналы сети, у - вектор выходных сигналов.
Существует путаница с подсчетом количества слоев в сети. Входной слой не
выполняет никаких вычислений, а лишь распределяет входные сигналы, поэтому
иногда его считают, иногда - нет. Обозначим через NL полное количество слоев в сети,
считая входной.
Работа многослойного перcептрона (МСП) описывается формулами:
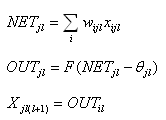
где индексом i всегда будем обозначать номер входа, j - номер нейрона в слое, l - номер слоя.
Xijl - й входной сигнал j-го нейрона в слое l;
Wijl - весовой коэффициент i-го входа нейрона номер j в слое l;jl - сигнал NET j-го нейрона в слое l; jl - выходной сигнал нейрона;
Өjl - пороговый уровень нейрона j в слое l;
Введем обозначения: Wjl - вектор-столбец весов для всех входов нейрона j в слое l; Wl - матрица весов всех нейронов в слое l. В столбцах матрицы расположены вектора Wjl. Аналогично Xjl - входной вектор-столбец слоя l.
Каждый слой рассчитывает нелинейное преобразование от линейной комбинации
сигналов предыдущего слоя. Отсюда видно, что линейная функция активации может
применяется только для тех моделей сетей, где не требуется последовательное
соединение слоев нейронов друг за другом. Для многослойных сетей функция
активации должна быть нелинейной, иначе можно построить эквивалентную
однослойную сеть, и многослойность оказывается ненужной. Если применена
линейная функция активации, то каждый слой будет давать на выходе линейную
комбинацию входов. Следующий слой даст линейную комбинацию выходов предыдущего,
а это эквивалентно одной линейной комбинации с другими коэффициентами, и может
быть реализовано в виде одного слоя нейронов.
Многослойная сеть может формировать на выходе произвольную многомерную функцию
при соответствующем выборе количества слоев, диапазона изменения сигналов и
параметров нейронов. Как и ряды, многослойные сети оказываются универсальным
инструментом аппроксимации функций.
В многослойном перcептроне нет обратных связей. Такие модели называются сетями прямого распространения. Они не обладают внутренним состоянием и не позволяют без дополнительных приемов моделировать развитие динамических систем.
Среди различных структур нейронных сетей (НС) одной из наиболее известных является многослойная структура, в которой каждый нейрон произвольного слоя связан со всеми нейронов предыдущего слоя или, в случае первого слоя, со всеми входами НС. Такие НС называются полносвязными. Когда в сети только один слой, алгоритм ее обучения с учителем довольно очевиден, так как правильные выходные состояния нейронов единственного слоя заведомо известны, и подстройка синаптических связей идет в направлении, минимизирующем ошибку на выходе сети. По этому принципу строится, например, алгоритм обучения однослойного перcептрона. В многослойных же сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, не известны, и двух или более слойный перcептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах НС. Один из вариантов решения этой проблемы - разработка наборов выходных сигналов, соответствующих входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией и не всегда осуществимо. Второй вариант - динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети. Очевидно, что данный метод, несмотря на свою кажущуюся простоту, требует громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант - распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Этот алгоритм обучения НС получил название процедуры обратного распространения.
Согласно методу наименьших квадратов, минимизируемой целевой функцией
ошибки НС является величина:
![]() (1)
(1)
где
![]() - реальное выходное состояние нейрона j выходного
слоя N нейронной сети при подаче на ее входы p-го образа; djp -
идеальное (желаемое) выходное состояние этого нейрона.
- реальное выходное состояние нейрона j выходного
слоя N нейронной сети при подаче на ее входы p-го образа; djp -
идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым
сетью образам. Минимизация ведется методом градиентного спуска, что означает
подстройку весовых коэффициентов следующим образом:
![]() (2)
(2)
Здесь wij - весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, h - коэффициент скорости обучения, 0<h<1.
Как показано в [17],
![]() (3)
(3)
Здесь под yj, , подразумевается выход нейрона j, а под sj
- взвешенная сумма его входных сигналов, то есть аргумент активационной
функции. Так как множитель dyj/dsj является производной
этой функции по ее аргументу, из этого следует, что производная активационной
функция должна быть определена на всей оси абсцисс. В связи с этим функция
единичного скачка и прочие активационные функции с неоднородностями не подходят
для рассматриваемых НС. В них применяются такие гладкие функции, как
гиперболический тангенс или классический сигмоид с экспонентой. В случае
гиперболического тангенса
![]() (4)
(4)
Третий множитель ¶sj/¶wij, очевидно, равен
выходу нейрона предыдущего слоя yi(n-1).
Что касается первого множителя в (3), он легко раскладывается следующим
образом[17]:
![]() (5)
(5)
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
![]() (6)
(6)
мы получим рекурсивную формулу для расчетов величин dj(n) слоя n из величин dk(n+1) более старшего слоя n+1.
![]() (7)
(7)
Для выходного же слоя
![]() (8)
(8)
Теперь мы можем записать (2) в раскрытом виде:
![]() (9)
(9)
Иногда для придания процессу коррекции весов некоторой инерционности,
сглаживающей резкие скачки при перемещении по поверхности целевой функции, (9)
дополняется значением изменения веса на предыдущей итерации
![]() (10)
(10)
где m - коэффициент инерционности, t - номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
а) Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам, рассчитать значения последних.
![]() (11)
(11)
где M - число нейронов в слое n-1 с учетом нейрона с постоянным выходным
состоянием +1, задающего смещение; yi(n-1)=xij(n)
- i-ый вход нейрона j слоя n.
yj(n) = f(sj(n)), где f() -
сигмоид (12)q(0)=Iq,(13)
где Iq - q-ая компонента вектора входного образа.
б) Рассчитать d(N) для выходного слоя по формуле (8).
Рассчитать по формуле (9) или (10) изменения весов Dw(N) слоя N.
в) Рассчитать по формулам (7) и (9) (или (7) и (10)) соответственно d(n) и Dw(n) для всех остальных слоев, n=N-1,...1.
г) Скорректировать все веса в НС
![]() (14)
(14)
д) Если ошибка сети существенна, перейти на шаг 1. В противном случае - конец.
Рассматриваемая НС имеет несколько нюансов. Во-первых, в процессе обучения может возникнуть ситуация, когда большие положительные или отрицательные значения весовых коэффициентов сместят рабочую точку на сигмоидах многих нейронов в область насыщения. Малые величины производной от логистической функции приведут в соответствие с (7) и (8) к остановке обучения, что парализует НС. Во-вторых, применение метода градиентного спуска не гарантирует, что будет найден глобальный, а не локальный минимум целевой функции. Эта проблема связана еще с одной, а именно - с выбором величины скорости обучения. Доказательство сходимости обучения в процессе обратного распространения основано на производных, то есть приращения весов и, следовательно, скорость обучения должны быть бесконечно малыми, однако в этом случае обучение будет происходить неприемлемо медленно. Кроме того, для исключения случайных попаданий в локальные минимумы иногда, после того как значения весовых коэффициентов стабилизируются, h кратковременно сильно увеличивают, чтобы начать градиентный спуск из новой точки. Если повторение этой процедуры несколько раз приведет алгоритм в одно и то же состояние НС, можно более или менее уверенно сказать, что найден глобальный максимум, а не какой-то другой.
2.1 Фреймворк Yii
История Yii началась 1 января 2008 года, как проект по исправлению некоторых изъянов в фреймворке PRADO (PHP Rapid Application Development Object-oriented), ставшего в 2004 победителем «Zend PHP 5 coding contest».
Фреймворк PRADO был попыткой перенести ASP.NET на платформу PHP, включая ViewState, PostBacks, Page_Load и OnClick. Если посмотреть исходный код, то можно увидеть что некоторые куски кода просто скопированы из ASP.NET (например, разделение на Rare Fields и Occasional Fields в классе Control с целью оптимизации по памяти, которое имеет смысл в .NET, но представляет сомнительную ценность в PHP).унаследовал от ASP.NET почти все отрицательные стороны: медленно обрабатывал сложные страницы, имел крутую кривую обучения и был довольно труден в настройке.
В определенный момент автор (Qiang Xue) понял, что PHP-фреймворк должен быть построен несколько по-другому, и вот в октябре 2008 года, после более 10 месяцев закрытой разработки, вышла первая альфа-версия. 3 декабря 2008 был выпущен Yii 1.0.. В данный момент доступна beta версия Yii 2.[10]
Фреймворк Yii обладает следующими возможностями:
высокая производительность относительно других фреймворков написанных на PHP
парадигма Модель-вид-контроллер;
интерфейсы DAO и ActiveRecord для работы с базами данных (PDO);
поддержка интернационализации;
кэширование страниц и отдельных фрагментов;
перехват и обработка ошибок;
ввод и валидация форм;
аутентификация и авторизация;
использование AJAX и интеграция с jQuery;
генерация базового PHP-кода для CRUD-операций;
поддержка тем оформления для их лёгкой смены;
возможность подключения сторонних библиотек;
миграции базы данных;
автоматическое тестирование;
поддержка REST.
По результатам тестов phpmark Yii показал самую лучшую производительность.
Справедливости ради, необходимо отметить, что производительность фреймворков в этих тестах оценивалась на искусственных примерах типа Hello world. Тесты показывают время инициализации фреймворков, и на основании их можно лишь сделать вывод, что Yii имеет качественную подсистему отложенной инициализации (то есть, код загружается только тогда, когда он необходим). Подтвержденной информации о том, что Yii в «боевых условиях» работает быстрее, чем другие фреймворки, нет.
В блогосфере можно найти массу статей со сравнительным анализом фреймворков. В целом, прослеживаются следующие тенденции:
Yii активно развивается.
Yii не выглядит «монстром» по сравнению с фреймворками symfony и Zend Framework (у которых число строк кода соизмеримо с числом строк кода операционных систем).
В некоторых сравнительных работах отмечается высокая скорость изучения фреймворка, получения результатов и прототипирования по сравнении с Zend Framework и Symfony. Также отмечается его стабильность и безопасность.
2.2 Паттерн MVC
Model-view-controller - схема использования нескольких шаблонов проектирования, с помощью которых модель данных приложения, пользовательский интерфейс и взаимодействие с пользователем разделены на три отдельных компонента таким образом, чтобы модификация одного из компонентов оказывала минимальное воздействие на остальные. Данная схема проектирования часто используется для построения архитектурного каркаса, когда переходят от теории к реализации в конкретной предметной области.
Концепция MVC была описана Трюгве Реенскаугом в 1979 году, работавшим в то время над языком программирования Smalltalk в Xerox PARC. Оригинальная реализация описана в статье «Applications Programming in Smalltalk-80: How to use Model-View-Controller». Затем Джим Алтофф с командой разработчиков реализовали версию MVC для библиотеки классов Smalltalk-80.
В оригинальной концепции была описана сама идея и роль каждого из элементов: модели, представления и контроллера. Но связи между ними были описаны без конкретизации. Кроме того, различали две основные модификации: