Материал: Оптимизация систем массового обслуживания
Теперь рассмотрим две
независимые СМО, каждая из которых работает только с одним определенным типом
заявок. Интенсивность первого входящего потока равна ![]()
![]() , интенсивность второго
входящего потока равна
, интенсивность второго
входящего потока равна ![]()
![]() . Время обслуживания
заявок первого типа имеет экспоненциальное распределение с параметром
. Время обслуживания
заявок первого типа имеет экспоненциальное распределение с параметром ![]()
![]() , время обслуживания
заявок второго типа имеет экспоненциальное распределение с параметром
, время обслуживания
заявок второго типа имеет экспоненциальное распределение с параметром ![]()
![]() . Системы функционируют
независимо друг от друга, соответственно каждой системе присуще свое среднее
время ожидания в очереди EX1 и EX2.
. Системы функционируют
независимо друг от друга, соответственно каждой системе присуще свое среднее
время ожидания в очереди EX1 и EX2.
Постановка задачи
оптимизации среднего времени ожидания
) Необходимо выяснить, какой из способов организации СМО эффективнее с точки зрения оптимизации среднего времени ожидания. - среднее время ожидания в очереди, когда одна СМО обслуживает все поступающие заявки.
![]()
![]() - среднее время
ожидания в очереди, когда для обслуживания каждого типа заявок предназначена
своя СМО.
- среднее время
ожидания в очереди, когда для обслуживания каждого типа заявок предназначена
своя СМО.
![]()
![]()
) Найти условие, при
котором разделение системы будет выгодно.
Исследование зависимости
критерия эффективности от распределения заявок по обслуживающим приборам
Как уже было сказано выше, в своей работе в качестве критерия эффективности я решила выбрать среднее время ожидания в очереди. Выведем данную формулу для СМО с бесконечной очередью. Учитывая, что время обслуживания заявок - это случайные величины, распределенные по экспоненциальному закону с параметром µ, получим:
ς(t) - число заявок в СМО в момент времени t
![]()
![]() - предельное
распределение
- предельное
распределение
![]()
![]() =
= ![]()
![]()
= ![]()
![]() =
= ![]()
![]() =
=
![]()
![]() =
= ![]()
![]() =
=
![]()
![]() =
= ![]()
![]() =
=
= ![]()
![]() = {j-n = k} =
= {j-n = k} = ![]()
![]() =
=
= ![]()
![]() =
= ![]()
![]()
где ![]()
![]() - средняя длина
очереди,
- средняя длина
очереди,
![]()
![]() =
= ![]()
![]()
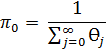
![]()
![]() =
=
![]()
![]() при
1 ≤ j ≤ n
при
1 ≤ j ≤ n
![]()
![]() =
= 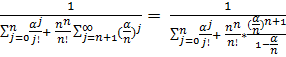
![]()
![]() =
= ![]()
![]()
![]()
![]() =
= ![]()
![]()
![]()
![]() =
= ![]()
![]() =
= ![]()
![]() =
=
![]()
![]() =
=
= ![]()
![]() =
= ![]()
![]() =
= ![]()
![]()
Таким образом получаем:
= ![]()
![]()
В случае, когда под
каждый тип заявок мы выделяем отдельную очередь, получим:
α1 = ![]()
![]() α2
=
α2
= ![]()
![]() =
= ![]()
![]() =
= ![]()
![]()
где ![]()
![]()
Не забудем поставить ограничение:
![]()
![]() < 1
< 1
![]()
![]() < 1
< 1
![]()
![]() < 1
< 1
Данные ограничения означают, что мы исключаем из рассмотрения случаи, когда СМО будет не в состоянии обслужить входящий поток.
Анализ полученных результатов
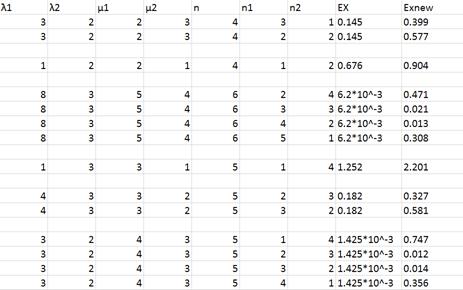
В приведенной выше таблице приведены результаты, полученные при помощи аналитических вычислений, которые в свою очередь были проверены и подтверждены при помощи имитационного моделирования (на этом этапе был разработан алгоритм, реализованный в mathcad). Как мы видим, вне зависимости от параметров входящего потока и способа распределения заявок по обслуживающим приборам, ни в одном из описанных случаев разделение не имеет смысла, что вполне логично, так как при разбиении очередей может возникнуть ситуация, при которой одна система простаивает, а вторая, наоборот, не успевает справляться с поступающим потоком требований. Правильность данных выводов подтверждается работой [2], в которой Е.С. Вентцель вывела ту же парадоксальную закономерность на примере работы железнодорожных касс.
Но как такое возможно? Не случайно ведь в тех же отделениях банков вас направляют в разные окна в зависимости от услуги, которая вам необходима. Вероятнее всего, такие результаты связаны с тем, что в реальной жизни, при разделении потоков идет расчет на то, что система, которая специализируется на определенном типе заявок, будет функционировать быстрее. Тогда поставим следующую задачу: Какие параметры, и как, должны измениться, чтобы функционирование систем, каждая из которых специализируется на обслуживании только одного типа заявок, привело к уменьшению среднего времени ожидания в очереди?
Рассмотрим следующий пример: в банк приходят клиенты за одним из двух типов услуг: обмен валюты и оформление кредитов. При обмене валют, необходимо лишь внести паспортные данные клиента и распечатать квитанцию, в то время как оформление кредита - это весьма трудоемкий процесс, состоящий из большого числа этапов:
клиент оформляет заявку, прилагая справки, подтверждающие его платежеспособность
по специальной базе оператор проверяет ‘надежность’ клиента (оформлялись ли кредиты ранее, возникали ли какие-то проблемы с выплатами и т.д.)
если было решено, что клиент ‘надежный’, оформляется договор в нескольких экземплярах
данные по клиенту вносятся в базу
клиенту выдают необходимую сумму денег
С учетом изложенной выше ситуации, было предложено рассмотреть следующую задачу:
Допустим, второй тип заявок (оформление кредита) практически невозможно оптимизировать, однако мы можем изменить среднее время обслуживания у заявок первого типа. Если разделить входящий поток на две отдельные очереди, больше не придется затрачивать время на:
переключение программ, в которых осуществляется обработка той или иной заявки
оператор, который натренирован на обработку определенного типа заявок, производит обслуживание быстрее (работа автоматизирована)
Так на сколько же должна измениться интенсивность обслуживания заявок первого типа, чтобы разбиение стало актуальным?
Рассмотри график
зависимости EXnew от ![]()
![]() для следующего
входящего потока:
для следующего
входящего потока:
![]()
![]() = 2
= 2
![]()
![]() = 3
= 3
![]()
![]() = 3
= 3
![]()
![]() = 2= 1= 4
= 2= 1= 4
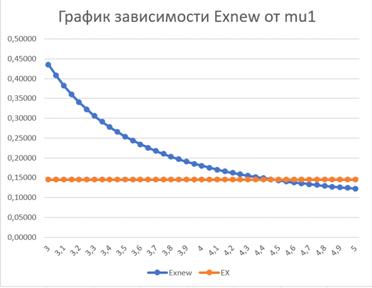
На данном графике видно,
что в тот момент, когда ![]()
![]() приняло значение 4.5,
разбиение наконец-то привело к уменьшению среднего времени ожидания в очереди.
приняло значение 4.5,
разбиение наконец-то привело к уменьшению среднего времени ожидания в очереди.
Решение задачи
оптимизации. Разработка программного кода для оптимизации системы
Выше было доказано, что разделение очередей в случае, если работу хотя бы одной из них можно оптимизировать, рационально с точки зрения оптимизации общего среднего времени ожидания обслуживания. Однако, важно уметь точно определить, на сколько нужно изменить интенсивность обслуживания на одном из приборов, чтобы разбиение имело смысл, в противном случае, деньги будут вложены в оптимизацию, которая так и не произойдет.
При помощи языка Python
была разработана программа, которая определяет, на сколько нужно изменить значение
![]()
![]() для конкретного
входящего потока, чтобы разбиение очередей привело к оптимизации среднего
времени ожидания.
для конкретного
входящего потока, чтобы разбиение очередей привело к оптимизации среднего
времени ожидания.
*Данные о входящем потоке вводятся вручную
# M|M|n|∞= 2
#интенсивность 1-го входящего потока= 3 #интенсивность 2-го входящего потока= 3
#интенсивность обслуживания заявок первого типа= 2 #интенсивность обслуживания
заявок второго типа=4 #число обслуживающих приборов в случае, когда у нас общая
очередь для всех типов заявок=1 #число обслуживающих приборов для заявок 1-го
типа=n-n1 #число обслуживающих приборов для заявок 2-го типа
l = l1 + l2= l1 / ((l1+l2) * mu1) + l2 / ((l1+l2) * mu2)= 1 / T= l1 / mu1= l2 / mu2= l / mu'Input data:''l1: ' 'l2: ' 'mu1: ' 'mu2: ' 'n: ' 'n1: '
#проверка на допустимость значений(l1 / (n1*mu1)) >= 1: "Error(1), these values are not available"(l2 / (n2*mu2)) >= 1: "Error(2), these values are not available"(l / (n*mu)) >= 1: "Error, these values are not available"
#Функция для вычисления факториалаfac(n):n == 0:1fac(n-1) * n= (n1 ** n1) / fac(n1) * ((alpha1 / n1) ** (n1 + 1)) / (1 - (alpha1 / n1))= 0j in range(0, n1+1):+= (alpha1 ** j) / fac(j)= 1 / (b1 + sumpk1)= (1 / (n1 * mu1)) * ((p10 / fac(n1-1)) * (alpha1 ** (n1+1)) * (1 / ((n1 - alpha1) ** 2)) + sumpk1)= (n2 ** n2) / fac(n2) * ((alpha2 / n2) ** (n2 + 1)) / (1 - (alpha2 / n2))= 0j in range(0, n2+1):+= (alpha2 ** j) / fac(j)= 1 / (b2 + sumpk2)= (1 / (n2 * mu2)) * ((p20 / fac(n2-1)) * (alpha2 ** (n2+1)) * (1 / ((n2 - alpha2) ** 2)) + sumpk2)= (n ** n) / fac(n) * ((alpha / n) ** (n + 1)) / (1 - (alpha / n))= 0j in range(0, n+1):+= (alpha ** j) / fac(j)= 1 / (b + sumpk)= (1 / (n * mu)) * ((p0 / fac(n-1)) * (alpha ** (n+1)) * (1 / ((n - alpha) ** 2)) + sumpk)= EX1 * (l1 / (l1 +l2)) + EX2 * (l2 / (l1 +l2))'EX1:' 'EX2:' 'EX:' 'EXnew:'
#Каким должно стать mu1, чтобы разбиение стало актуальным?new = mu1= EXnewEXnew1 > EX:new += 0.05= l1 / mu1new= (n1 ** n1) / fac(n1) * ((alpha1 / n1) ** (n1 + 1)) / (1 - (alpha1 / n1))= 0j in range(0, n1+1):+= (alpha1 ** j) / fac(j)= 1 / (b1 + sumpk1)= (1 / (n1 * mu1new)) * ((p10 / fac(n1-1)) * (alpha1 ** (n1+1)) * (1 / ((n1 - alpha1) ** 2)) + sumpk1)= EX1 * (l1 / (l1 +l2)) + EX2 * (l2 / (l1 +l2))'Initial mu1: ''Optimized mu1:'new'Optimized EX'
Численные примеры
Пример1:
Возьмем те же входящие данные, что были использованы при построении графика:

Полученные результаты:
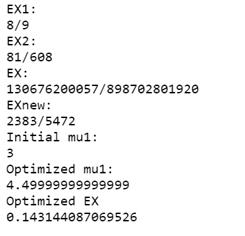
Вывод: результат, полученный на графике, подтвержден. При данном входящем потоке, среднее время ожидания в очереди начнет уменьшаться, если интенсивность обслуживания заявок первого типа станет ≥ 4.5
Пример 2:

Полученные результаты:
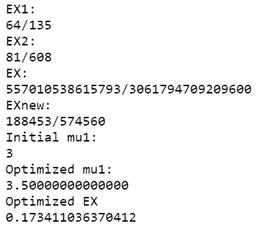
Вывод: При данном входящем потоке, среднее время ожидания в очереди начнет уменьшаться, если интенсивность обслуживания заявок первого типа будет ≥ 3.5
Теперь посмотрим, как будет меняться среднее время ожидания в очереди для одинаковых входящих потоков при различных разбиениях обслуживающих приборов.
В примере 3 рассмотрим случай, когда из 7 обслуживающих приборов, 2 задействованы для обработки заявок первого типа. Далее, в примере 3.1. берем тот же входящий поток, но на этот раз на обслуживание заявок первого типа выделим уже 3 прибора.