Материал: Обоснование оценок искомых параметров и их ошибок
где минус первая степень означает
функцию, обратную к ![]() . Через эту
величину доверительный интервал выражается следующим образом:
. Через эту
величину доверительный интервал выражается следующим образом:
![]() (11)
(11)
Перейдем к рассмотрению точной
теории, учитывающей число экспериментов. Здесь принимается, что изучаемая
величина описывается точно нормальным распределением. В этом случае доказана
теорема, что величина 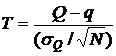 подчиняется
т.н. t - распределению Стьюдента с N-1 степенями свободы, обозначим это
распределение
подчиняется
т.н. t - распределению Стьюдента с N-1 степенями свободы, обозначим это
распределение ![]() (соответствующее
выражение можно найти в книгах по теории вероятности и статистике). Далее
рассуждения повторяются, только вместо функции (10) в уравнении, аналогичном
(10), будет присутствовать функция
(соответствующее
выражение можно найти в книгах по теории вероятности и статистике). Далее
рассуждения повторяются, только вместо функции (10) в уравнении, аналогичном
(10), будет присутствовать функция ![]() . Из соответствующего уравнения
опять находится коэффициент
. Из соответствующего уравнения
опять находится коэффициент ![]() , который теперь будет функцией не
только принятого уровня вероятности в, но и от количества степеней свободы
N-1(если искомых параметров р штук, то количество степеней свободы равно N-p).
Доверительный интервал снова оценивается по формуле (11).
, который теперь будет функцией не
только принятого уровня вероятности в, но и от количества степеней свободы
N-1(если искомых параметров р штук, то количество степеней свободы равно N-p).
Доверительный интервал снова оценивается по формуле (11).
Аналогично можно рассчитать доверительный интервал и для дисперсии.
В практических применениях часто
используют решение уравнения (9) с функцией Стьюдента. Соответствующие таблицы ![]() в
зависимости от в и N-p (p - число
определяемых параметров) приводятся в руководствах по статистике и теории
вероятностей. С их помощью можно оценить надежность статистических оценок. Так
поступают часто даже в тех случаях, если закон распределения искомой величины
неизвестен.
в
зависимости от в и N-p (p - число
определяемых параметров) приводятся в руководствах по статистике и теории
вероятностей. С их помощью можно оценить надежность статистических оценок. Так
поступают часто даже в тех случаях, если закон распределения искомой величины
неизвестен.
Каким принять уровень надежности? Не
существует математических методов расчета уровня надежности. Это зависит от
конкретной ситуации. Ранее было введено понятие стандартной ошибки. Это
означает, что вероятностью 68% ожидаемая величина попадает в интервал ![]() и с
вероятностью 32% не попадает. 32% - это почти половина от 68%. Надежность
оценки в этом случае невелика. Общепринятым считается, что во многих случаях
можно считать оценку надежной, если искомая величина попадает в доверительный
интервал с вероятностью 95% и лишь с вероятностью 5% оказывается вне его. Для
N-1=10 этому уровню надежности соответствует
и с
вероятностью 32% не попадает. 32% - это почти половина от 68%. Надежность
оценки в этом случае невелика. Общепринятым считается, что во многих случаях
можно считать оценку надежной, если искомая величина попадает в доверительный
интервал с вероятностью 95% и лишь с вероятностью 5% оказывается вне его. Для
N-1=10 этому уровню надежности соответствует ![]() (для
(для ![]()
![]() ). Таким образом, доверительный
интервал примерно в
). Таким образом, доверительный
интервал примерно в ![]() (так и
говорят: «две сигмы») соответствует примерно 95%-ому уровню надежности. В
некоторых случаях требуется более высокий уровень надежности, скажем, 99% (в
качестве примеров приведем следующие ситуации: ответственные или дорогостоящие
- космические - эксперименты, или когда вероятность гибели людей отлична от
нуля). Тогда доверительный интервал выбирают существенно больше, например, три
сигмы.
(так и
говорят: «две сигмы») соответствует примерно 95%-ому уровню надежности. В
некоторых случаях требуется более высокий уровень надежности, скажем, 99% (в
качестве примеров приведем следующие ситуации: ответственные или дорогостоящие
- космические - эксперименты, или когда вероятность гибели людей отлична от
нуля). Тогда доверительный интервал выбирают существенно больше, например, три
сигмы.
Из понятия доверительного интервала вытекают несколько важных следствий.
. Основываясь на этих
представлениях, мы можем принять, что те измерения, которые сильно отклоняются
от среднего значения, ошибочны. В качестве границы, отделяющей сильные
отклонения от приемлемых, часто принимают ![]() - «правило трех сигм». Это правило
используется для отбрасывания «подозрительных» данных.
- «правило трех сигм». Это правило
используется для отбрасывания «подозрительных» данных.
. Пусть оцененное в результате
экспериментов значение какой-то величины есть ![]() , тогда как ожидаемое значение есть
, тогда как ожидаемое значение есть ![]() (частным
значением может быть
(частным
значением может быть ![]() . С помощью
t - распределения Стьюдента мы можем ответить на такой вопрос: приемлемо ли
полученное значение
. С помощью
t - распределения Стьюдента мы можем ответить на такой вопрос: приемлемо ли
полученное значение ![]() ? Еще
говорят так: можем проверить нуль гипотезу о том, что
? Еще
говорят так: можем проверить нуль гипотезу о том, что ![]() . Сокращенно
пишут так: «
. Сокращенно
пишут так: «![]() против
против ![]() » (здесь
буква Н от английского слова гипотеза - hypothesis). Для проверки
гипотезы, во-первых, задается уровень надежности
» (здесь
буква Н от английского слова гипотеза - hypothesis). Для проверки
гипотезы, во-первых, задается уровень надежности ![]() , скажем, 95%; во-вторых,
вычисляется отношение
, скажем, 95%; во-вторых,
вычисляется отношение ![]() . Далее, по
таблицам находится
. Далее, по
таблицам находится ![]() (это
значение коэффициента Стьюдента называют еще критическим). Если оцененное
значение
(это
значение коэффициента Стьюдента называют еще критическим). Если оцененное
значение ![]() окажется
больше критического
окажется
больше критического ![]() , то
гипотеза, что
, то
гипотеза, что ![]() отвергается
(в статистических исследованиях обычно избегают выражения «принять гипотезу» и
предпочитают обсуждать вопрос отвергнуть или не отвергнуть).
отвергается
(в статистических исследованиях обычно избегают выражения «принять гипотезу» и
предпочитают обсуждать вопрос отвергнуть или не отвергнуть).
Изложенная методика количественной
оценки качества измерений будет использована далее.
. Коэффициент корреляции
Выше, при выводе формул для ошибок в косвенных измерениях, мы предполагали, что соответствующие непосредственно измеряемые (случайные) величины являются независимыми. Здесь мы дадим количественную меру для оценки зависимости случайных величин.
Пусть мы имеем две случайные величины
![]() и
и ![]() . Для систем
случайных величин, так же как и для одной, вводятся числовые характеристики -
моменты. Обозначим плотность распределения вероятностей этих величин через
. Для систем
случайных величин, так же как и для одной, вводятся числовые характеристики -
моменты. Обозначим плотность распределения вероятностей этих величин через ![]() . Смысл ее
понятен:
. Смысл ее
понятен: ![]() есть
вероятность одновременного попадания
есть
вероятность одновременного попадания ![]() и
и ![]() в соответствующие интервалы.
в соответствующие интервалы.
Начальными моментами порядка ![]() называется
математическое ожидание:
называется
математическое ожидание:
![]() (12)
(12)
Отсюда математическим ожиданием для
величин ![]() и
и ![]() является:
является: ![]() ;
; ![]() .
.
Центральным моментом порядка ![]() называется
математическое ожидание:
называется
математическое ожидание:
![]() (13)
(13)
Отсюда дисперсии ![]() ;
; ![]() . Они
характеризуют рассеивание случайной точки (с координатами
. Они
характеризуют рассеивание случайной точки (с координатами ![]() ) в
направлении соответствующих осей.
) в
направлении соответствующих осей.
Помимо приведенных моментов из
формулы (13) вытекает существование еще одного момента второго порядка
![]() , (14)
, (14)
который называется смешанным или
корреляционным моментом случайных величин ![]() , который описывает связь между
случайными величинами. Для того, чтобы в этом убедиться, покажем, что для
независимых случайных величин он равен нулю. Действительно, для независимых
случайных величин функция плотности распределения вероятностей есть
произведение вероятностей для каждой величины, т.е.
, который описывает связь между
случайными величинами. Для того, чтобы в этом убедиться, покажем, что для
независимых случайных величин он равен нулю. Действительно, для независимых
случайных величин функция плотности распределения вероятностей есть
произведение вероятностей для каждой величины, т.е. ![]() . Тогда
. Тогда
![]() (15)
(15)
Напоминаем, что угловые скобки здесь
означают усреднение. Поскольку ![]() и
и![]() , то из (4.4) следует, что в этом
случае
, то из (4.4) следует, что в этом
случае ![]() .
.
Итак, для независимых случайных величин корреляционный момент равен нулю. Обратное, вообще говоря, неверно. Равенство нулю корреляционного момента еще не означает, что величины независимые.
Рассмотрим другой предельный случай
зависимых величин. Пусть ![]() . Для этого
случая для вычисления корреляционного момента вместо двойного интеграла будет
простой интеграл:
. Для этого
случая для вычисления корреляционного момента вместо двойного интеграла будет
простой интеграл:
![]() (16)
(16)
Это выражение можно симметризовать
следующим образом. Из (13) в случае зависимых величин имеем: ![]() . Отсюда:
. Отсюда: ![]() . Подставляя
его в (16), имеем:
. Подставляя
его в (16), имеем:
![]() . (17)
. (17)
В практических расчетах вместо
корреляционного момента часто используют коэффициент корреляции ![]() , который
определяется следующим образом:
, который
определяется следующим образом:
![]() (18).
(18).
Очевидно, в случае независимых
величин вслед за корреляционным моментом коэффициент корреляции равен нулю. В
случае линейно зависимых величин с помощью (4.5, 4.6) получим:
![]() (19).
(19).
Отсюда видно, что коэффициент корреляции равен единице, если у растет вместе с х, и минус единице, если убывает.
В общем случае, т.е. произвольной
вероятностной зависимости между величинами, коэффициент корреляции оказывается
заключен в пределах: ![]() . Если
коэффициент корреляции положителен, то говорят о положительной корреляции,
отрицателен - об отрицательной.
. Если
коэффициент корреляции положителен, то говорят о положительной корреляции,
отрицателен - об отрицательной.
. Оценка погрешности в косвенных
измерениях. Зависимые величины
Теперь мы можем дать формулу оценки
погрешности в случае косвенных измерений, когда измеряемые величины являются
зависимыми (точнее, коррелированными), т.е. обобщить формулу (19). Напомним,
пусть мы измеряем величины x и y, а нас интересует величина ![]() . Мы хотим
получить рецепт расчета погрешности
. Мы хотим
получить рецепт расчета погрешности ![]() , если известны погрешности x и y и
известно, что они не являются независимыми. Как и в Теме 1 разложим
, если известны погрешности x и y и
известно, что они не являются независимыми. Как и в Теме 1 разложим ![]() , здесь
использовано представление
, здесь
использовано представление ![]() и
и ![]() , где
, где ![]() и
и ![]() - случайные величины,
характеризующие разброс измеряемых величин вокруг истинных значений X и Y. Используя
это представление, вычислим дисперсию
- случайные величины,
характеризующие разброс измеряемых величин вокруг истинных значений X и Y. Используя
это представление, вычислим дисперсию ![]() :
:
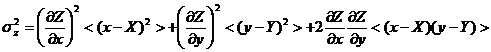
Как и выше здесь использованы
обозначения ![]() . Очевидно,
. Очевидно, ![]() .
Окончательно,
.
Окончательно,
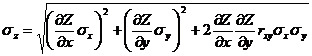 (20)
(20)
Эта формула обобщает расчет ошибок в косвенных измерениях, если непосредственно измеряемые величины являются коррелированными.
Лишние данные
В разделе 1 было показано, что
погрешность измерения среднего равна ![]() , где
, где ![]() есть дисперсия ошибок,
есть дисперсия ошибок, ![]() есть число
измерений. Там же был сформулирован парадокс: поскольку при
есть число
измерений. Там же был сформулирован парадокс: поскольку при ![]() мы можем
сделать ошибку сколь угодно малой, то можно ожидать, что с помощью грубых
приборов можно производить измерения со сколь угодно большой точностью. Один из
ответов был такой: в этих рассуждениях предполагалось, что инструментальной
ошибкой мы можем пренебречь. Очевидно, если случайная ошибка сравнивается с
инструментальной (систематической), то дальше накапливать измерения просто нет
смысла. Оказывается, что корреляции между ошибками в процессе измерений также
накладывают ограничение на число измерений.
мы можем
сделать ошибку сколь угодно малой, то можно ожидать, что с помощью грубых
приборов можно производить измерения со сколь угодно большой точностью. Один из
ответов был такой: в этих рассуждениях предполагалось, что инструментальной
ошибкой мы можем пренебречь. Очевидно, если случайная ошибка сравнивается с
инструментальной (систематической), то дальше накапливать измерения просто нет
смысла. Оказывается, что корреляции между ошибками в процессе измерений также
накладывают ограничение на число измерений.
С этой целью рассмотрим такую
демонстрационную задачу. Пусть нас интересует некоторая случайная величина
![]() (21)
(21)
Обратим внимание на то, что индексом i отмечается i-я случайная величина x.
Далее как обычно большими буквами будем обозначать средние соответствующих величин. Тогда
![]()
Дисперсия
![]() (22)
(22)
![]()
Обозначим стоящее под знаком суммы
выражение: ![]() . Эту
величину называют ковариационной матрицей. В частном случае
. Эту
величину называют ковариационной матрицей. В частном случае ![]() она будет
равна ковариационному коэффициенту.
она будет
равна ковариационному коэффициенту.
Допустим, что
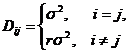 (23)
(23)
Где ![]() есть дисперсия х (в нашем
демонстрационном расчете принимаем ее постоянной), r есть
коэффициент корреляции между различными х (его тоже принимаем постоянным). Из
приведенного выражения видно, что ковариационная матрица имеет
есть дисперсия х (в нашем
демонстрационном расчете принимаем ее постоянной), r есть
коэффициент корреляции между различными х (его тоже принимаем постоянным). Из
приведенного выражения видно, что ковариационная матрица имеет ![]() одинаковых
значений, равных
одинаковых
значений, равных ![]() (они
располагаются на диагонали), и, соответственно
(они
располагаются на диагонали), и, соответственно ![]() значений, равных
значений, равных ![]() . Таким
образом:
. Таким
образом:
![]() (24)
(24)
Рассмотрим следствие из формулы
(24). Предположим, что ![]() - некоторые
измеряемы величины. Как правило, для их случайной составляющей предполагается
некоторый закон распределения, при этом для простоты полагают, что они
независимые, т.е.
- некоторые
измеряемы величины. Как правило, для их случайной составляющей предполагается
некоторый закон распределения, при этом для простоты полагают, что они
независимые, т.е. ![]() (некоррелированные
величины). Отсюда дисперсия интересующей нас величины равна:
(некоррелированные
величины). Отсюда дисперсия интересующей нас величины равна: ![]() . Но если
коэффициент парной корреляции отличен от нуля, то стандартное отклонение
интересующей нас величины растет с
. Но если
коэффициент парной корреляции отличен от нуля, то стандартное отклонение
интересующей нас величины растет с ![]() гораздо быстрее. Отсюда вытекает
ограничение на нужное количество измерений:
гораздо быстрее. Отсюда вытекает
ограничение на нужное количество измерений:
![]() (25)
(25)
Аналогично можно показать
(Эльясберг), что при наличии корреляций между ошибками в различных измерения
одной и той же величины среднее значение интересующей нас величины имеет
стандартное отклонение:
![]() ; при
; при ![]() . (26)
. (26)
В настоящее время нередко проводятся эксперименты с большим количеством измерений. Особенно это стало возможно в компьютерную эру. При этом, в процессе обработке молчаливо предполагается, что различные измерения являются независимыми. Из последней формулы видно, к каким ошибкам это может привести. Очевидно, оптимальное значение измерений получается согласно (25).