Материал: Обоснование оценок искомых параметров и их ошибок
Обоснование оценок искомых параметров и их ошибок
Реферат
Обоснование
оценок искомых параметров и их ошибок
1. Оценки искомых параметров и их ошибок. Прямые
измерения
Обратимся к обоснованию оценок измерений и их погрешностей. Подчеркнем, что определение систематических ошибок не является задачей статистики. Это инструментальная проблема. Поэтому в дальнейшем систематическую ошибку мы исключаем. Впрочем, мы все-таки будем ее вкратце касаться.
Пусть проводятся измерения какой-то
величины ![]() . В
результате N экспериментов имеем выборку N измеренных величин
. В
результате N экспериментов имеем выборку N измеренных величин ![]() , и нам
нужно определить какие-то параметры на основе этих измерений. Будучи некоторой
функцией
, и нам
нужно определить какие-то параметры на основе этих измерений. Будучи некоторой
функцией ![]() , искомые
параметры, в свою очередь, будут некоторыми случайными величинами. Очевидно, их
закон распределения будет как-то зависеть от закона распределения
, искомые
параметры, в свою очередь, будут некоторыми случайными величинами. Очевидно, их
закон распределения будет как-то зависеть от закона распределения ![]() . Будем
считать, что оценка соответствующих параметров является «хорошей», если она
удовлетворяет следующим условиям.
. Будем
считать, что оценка соответствующих параметров является «хорошей», если она
удовлетворяет следующим условиям.
. Является состоятельной, т.е. при ![]() оценка
сходится к самому параметру (который, вообще говоря, неизвестен).
оценка
сходится к самому параметру (который, вообще говоря, неизвестен).
. Является несмещенной, т.е. поскольку мы используем не сам искомый параметр, а его оценку, то мы не должны делать систематической ошибки в сторону его завышения или занижения, иными словами математическое ожидание этого параметра должно равняться ему самому.
Является эффективной, в том смысле, что несмещенная оценка обладала бы наименьшей дисперсией.
Пусть мы имеем N измерений некоторой
величины ![]() , которую
представим в виде:
, которую
представим в виде:
![]() (1)
(1)
где, как и раньше, Q есть
математическое ожидание, ![]() есть
случайная величина - погрешность. Закон распределения случайной величины нам
неизвестен. Известно лишь, что
есть
случайная величина - погрешность. Закон распределения случайной величины нам
неизвестен. Известно лишь, что ![]() . Наша задача - оценить среднее
значение Q и ошибку этого среднего. В качестве математического ожидания
естественно взять среднее арифметическое
. Наша задача - оценить среднее
значение Q и ошибку этого среднего. В качестве математического ожидания
естественно взять среднее арифметическое
![]() (2)
(2)
т.к. согласно закону больших чисел эта оценка будет состоятельной и несмещенной.
Дисперсия Q (т.е. разброс в
определении истинного значения, обозначим дисперсию ![]() ) согласно
центральной предельной теореме (см. 2.8) равна:
) согласно
центральной предельной теореме (см. 2.8) равна:
![]() (3)
(3)
где у2 есть дисперсия ![]() . Если нам
как-то определить у2, то мы могли бы найти дисперсию среднего
значения, т.е. его разброс. Тогда среднее значение искомой величины мы
представили бы в виде:
. Если нам
как-то определить у2, то мы могли бы найти дисперсию среднего
значения, т.е. его разброс. Тогда среднее значение искомой величины мы
представили бы в виде: ![]() . Такая
запись означала бы, что с вероятностью примерно 68% среднее значение искомой
величины лежит в пределах
. Такая
запись означала бы, что с вероятностью примерно 68% среднее значение искомой
величины лежит в пределах ![]() относительно
найденного значения Q.
относительно
найденного значения Q.
Перейдем к определению у2.
На первый взгляд для нее представляется естественной взять следующую оценку :
![]() (4)
(4)
Можно показать, что эта оценка
состоятельна, а также для нормального закона распределения ![]() (3) будет
минимальной, т.е оценка разброса эффективная. Но расчеты (детали можно найти,
например, в книге Вентцель) показывают, что эта оценка является смещенной, а
именно, несмещенная оценка должна получаться путем замены (4) на следующее
выражение:
(3) будет
минимальной, т.е оценка разброса эффективная. Но расчеты (детали можно найти,
например, в книге Вентцель) показывают, что эта оценка является смещенной, а
именно, несмещенная оценка должна получаться путем замены (4) на следующее
выражение:
![]() (5)
(5)
Для больших выборок поправочный коэффициент стремится к единице. Его имеет смысл вводить для небольших выборок.
Обратим внимание на следующее обстоятельство. В нашей задаче мы имели один искомый параметр Q. И в (5) в знаменателе имеем величину N-1. Если бы мы решали задачу с несколькими искомыми параметрами, скажем, p, то, как показывают исследования, вместо N-1 мы бы имели N-p. Эта величина называется количеством степеней свободы. При большом числе определяемых параметров, очевидно, следует учитывать количество степеней свободы, особенно если число измерений невелико.
Резюмируем сказанное. Величина у,
которая характеризует разброс погрешности ![]() , еще называется погрешностью единичного
измерения. Погрешностью измерения среднего значения является
, еще называется погрешностью единичного
измерения. Погрешностью измерения среднего значения является ![]() . Она
оказывается существенно меньше, чем (1.4).
. Она
оказывается существенно меньше, чем (1.4).
Обоснование среднего как наилучшей оценки
Пусть на основании измерений мы
имеем выборку ![]() . Наша
задача - найти наилучшие оценки для Q и
. Наша
задача - найти наилучшие оценки для Q и ![]() . Если нам известно, что результаты
измерений описываются нормальным законом, то мы могли бы вычислить вероятность
получения значений
. Если нам известно, что результаты
измерений описываются нормальным законом, то мы могли бы вычислить вероятность
получения значений ![]() . Так,
вероятность того, что
. Так,
вероятность того, что ![]() заключена в
интервале
заключена в
интервале ![]() вблизи
фактически измеренного значения равна:
вблизи
фактически измеренного значения равна:
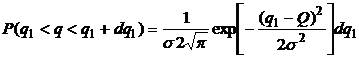
аналогично записываем для других ![]() .
Вероятность того, что в процессе N измерений мы будем иметь те
.
Вероятность того, что в процессе N измерений мы будем иметь те ![]() , которые и
были получены в эксперименте, равна:
, которые и
были получены в эксперименте, равна:
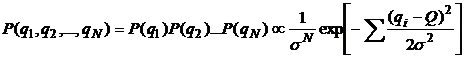 (6)
(6)
Очевидно, здесь делается
предположение о независимости измерений! Кроме того, мы сократили на ![]() .
.
Важно отметить, что величины ![]() - это
измеренные, т.е. известные нам значения. Неизвестны здесь среднее Q и дисперсия
- это
измеренные, т.е. известные нам значения. Неизвестны здесь среднее Q и дисперсия
![]() . Задача и
состоит в том, чтобы их найти. Решение, очевидно, состоит в следующем:
Наилучшей оценкой для искомых параметров будет оценка, при которой вероятность
их реализации будет максимальной. В статистике это называется принципом
максимального правдоподобия. Максимум достигается при минимуме показателя, т.е.
. Задача и
состоит в том, чтобы их найти. Решение, очевидно, состоит в следующем:
Наилучшей оценкой для искомых параметров будет оценка, при которой вероятность
их реализации будет максимальной. В статистике это называется принципом
максимального правдоподобия. Максимум достигается при минимуме показателя, т.е.
![]() . Дифференцируя,
получим:
. Дифференцируя,
получим: ![]() , или
, или ![]() . Для оценки
дисперсии, дифференцируем вероятность (6):
. Для оценки
дисперсии, дифференцируем вероятность (6):
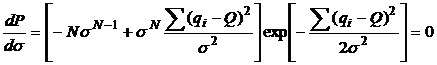
Отсюда:
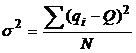
На первый взгляд, последняя оценка противоречит сказанному ранее, когда в знаменателе вместо N фигурировало количество степеней свободы N-1. В действительности должно фигурировать именно N-1, что можно доказать более точными расчетами (см. курс Вентцель). Качественная причина такой замены состоит в том, что в оценке дисперсии используется не истинное значение Q, а его оценка, которая заключает в себе уже некоторую погрешность.
На приведенном ниже рисунке 1 поясняется
процесс измерения, как реализация (красные точки) из возможного ряда значений,
имеющих соответствующий разброс. Этот разброс и есть разброс отдельного
измерения.
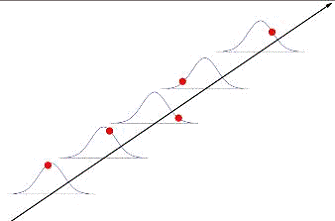
Рис. 1. Качественное пояснение
разброса отдельных измерений.
Здесь возникает такой вопрос:
увеличивая число измерений, мы можем определить искомую величину, казалось бы,
с какой угодно точностью. Этот абсурдный вывод можно опровергнуть следующим
образом. Во-первых, мы с самого начала не учитывали систематическую (т.е.
инструментальную) погрешность. Очевидно, если случайная погрешность сравнялась
с систематической, то дальше уже нет смысла ее уменьшать, накапливая число
измерений. Следует поработать над конструкцией приборов с целью уменьшения
систематической погрешности. Кроме того, в приведенных выше рассуждениях
принималось, что измерения независимые. Если измерения делаются на одном и том
же приборе, то абсолютной независимости гарантировать нельзя. В этом случае
возникает некоторая зависимость между измерениями, и это тоже налагает
определенный предел на количество измерительной информации. Наконец, любопытно
сделать следующую оценку. Предположим, что, тем не менее, путем увеличения
числа измерений, мы с помощью грубых приборов пытаемся выполнить тонкие
измерения, например, с помощью обычной линейки определить размер атома. Примем,
что для измерений с помощью линейки у = 1 мм. Т.к. размер атома порядка 10-7
мм, чтобы достичь нужной точности, нам следует выполнить порядка 1014
измерений. Если мы предположим, что одно измерение делается в течение 1
секунды, нам потребуется ![]() лет: три
миллиона лет!
лет: три
миллиона лет!
Итак, на грубых приборах невозможно
получить точных результатов. С помощью статистических методов можно лишь
улучшить наивные оценки статистических погрешностей типа (1.3).
. Обоснование оценок ошибок в
косвенных измерениях
Независимые измерения
Ниже мы дадим вероятностное
обоснование формуле (1.7). Итак, имеем измеряемые величины x и y. Нас
интересует наилучшая оценка величины z с ее ошибками, которая связана с
предыдущими соотношением ![]() . Представим
. Представим
![]() , где Х есть
среднее, а
, где Х есть
среднее, а ![]() есть
случайная добавка. Аналогично запишем для других величин. Будем считать, что
случайные добавки распределены по нормальному закону. Тогда вероятность
есть
случайная добавка. Аналогично запишем для других величин. Будем считать, что
случайные добавки распределены по нормальному закону. Тогда вероятность
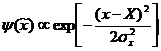
Аналогично для ![]() . Мы здесь
не выписываем нормировочных коэффициентов. Поскольку
. Мы здесь
не выписываем нормировочных коэффициентов. Поскольку ![]() и
и ![]() независимы,
то вероятность получения любых
независимы,
то вероятность получения любых ![]() и
и ![]() равна
равна
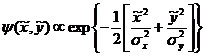 (7)
(7)
Сделаем в последнем выражении замену
переменных: от ![]() и
и ![]() вначале
перейдем к переменным
вначале
перейдем к переменным ![]() и
и ![]() (очевидно,
среднеквадратичные разбросы новых переменных:
(очевидно,
среднеквадратичные разбросы новых переменных: ![]() и
и ![]() ). Тогда
). Тогда ![]() . Теперь
сделаем замену в (7): от
. Теперь
сделаем замену в (7): от ![]() и
и ![]() перейдем к
переменным
перейдем к
переменным ![]() и
и ![]() . Путем
простых, но громоздких преобразований можно показать:
. Путем
простых, но громоздких преобразований можно показать:
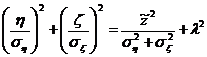 , где
, где 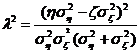 .
.
Плотность распределения их
вероятности будет:
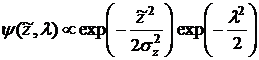 ,
,
где ![]() (8)
(8)
имеет смысл дисперсии ![]() . Поскольку
нас интересует вероятность появления некоторого
. Поскольку
нас интересует вероятность появления некоторого ![]() при любом
при любом ![]() (при этом
(при этом ![]() и
и ![]() независимы),
то плотность распределения вероятности
независимы),
то плотность распределения вероятности ![]()
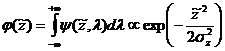 .
.
Таким образом, величина ![]() также
распределена по нормальному закону с разбросом
также
распределена по нормальному закону с разбросом ![]() , определяемым формулой (8).
, определяемым формулой (8).
Формула (8) легко обобщается на произвольную функциональную зависимость (см.1.8).
Еще раз напомним, что в этом разделе речь шла об оценке ошибок в случае, когда исходные величины независимые.
Выше речь шла о случайных погрешностях. Как в окончательном ответе учесть систематические ошибки? Суммарная ошибка, учитывающая как случайную, так и систематическую погрешность, может быть оценена либо как простая сумма ошибок (аналогично (1.3)), либо как корень квадратный из суммы квадратов (аналогично (8)). Обосновать ту или иную формулу, по крайней мере, в общем виде не представляется возможным. Очевидно, последняя оценка будет несколько меньше первой.
Доверительный интервал. Надежность оценок
Оценкой ошибок процесс обработки опытов еще не заканчивается. Необходимо еще выяснить надежность выполненных оценок. Это особенно важно в случае небольших выборок, но не только. Поясним сказанное. Как уже говорилось, в качестве оценки для математического ожидания принимается среднее арифметическое. Если число экспериментов велико, то с большой вероятностью среднее арифметическое будет близко к математическому ожиданию. Но при малом числе экспериментов, замена математического ожидания средним арифметическим может привести к некоторой погрешности, т.к. среднее арифметическое меняется в зависимости от числа элементов в выборке. Доверительный интервал и служит для целей оценки качества определения параметров.
Вначале рассмотрим введение
доверительного интервала в асимптотическом приближении бесконечно большого
числа экспериментов. Пусть для искомого параметра q в
результате серии экспериментов получена оценка ![]() . Мы хотим оценить возможную ошибку.
Назначим некоторую большую вероятность в, такую, что с этой вероятностью
событие можно было бы считать достоверным, и найдем такое значение е, для
которого вероятность отклонения оценки от искомого параметра в пределах этого
значения будет равна в, т.е.:
. Мы хотим оценить возможную ошибку.
Назначим некоторую большую вероятность в, такую, что с этой вероятностью
событие можно было бы считать достоверным, и найдем такое значение е, для
которого вероятность отклонения оценки от искомого параметра в пределах этого
значения будет равна в, т.е.:
![]() .
.
Это означает, что диапазон возможных
ошибок при замене q на Q с большой
вероятностью равен ![]() относительно
Q.
Вероятность попадания искомой величины вне этот диапазон, равная 1- в будет
мала. Вероятность в принято называть доверительной вероятностью, интервал от
относительно
Q.
Вероятность попадания искомой величины вне этот диапазон, равная 1- в будет
мала. Вероятность в принято называть доверительной вероятностью, интервал от ![]() до
до ![]() -
доверительным интервалом. Еще этот интервал понимают как интервал значений, не
противоречащих опыту. События, не попадающие в указанный интервал, имеют малую
вероятность и считаются противоречащими опыту.
-
доверительным интервалом. Еще этот интервал понимают как интервал значений, не
противоречащих опыту. События, не попадающие в указанный интервал, имеют малую
вероятность и считаются противоречащими опыту.
Как, задав в, найти доверительный
интервал? Для этого надо знать закон распределения величины ![]() . Как
правило, он не известен, но центральная предельная теорема дает основания
принять его нормальным. Тогда:
. Как
правило, он не известен, но центральная предельная теорема дает основания
принять его нормальным. Тогда:
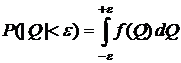 (9)
(9)
Здесь
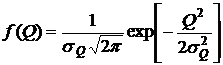
Сделав в интеграле замену: 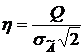 , его можно
привести к виду
, его можно
привести к виду
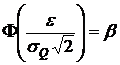 , (10)
, (10)
где использовано обозначение
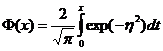 - эта функция называется функцией
Лапласа или функцией ошибок (в справочниках она может нормироваться
по-разному).
- эта функция называется функцией
Лапласа или функцией ошибок (в справочниках она может нормироваться
по-разному).
Т.о., решая трансцендентное уравнение (10), находим е для принятого в. В математических справочниках приводятся таблицы решений уравнения типа (10), записанного в виде: