Материал: лекция 5 ММОСУ
ЛЕКЦИЯ 5. СТОХАСТИЧЕСКИЕ, НЕЧЕТКИЕ И ХАОТИЧЕСКИЕ МОДЕЛИ
5.1 Детерминированные и стохастические модели Модели систем, о которых мы говорили до сих пор, были
детерминированными (определенными), т.е. задание входного воздействия определяло выход системы однозначно. Однако на практике так бывает редко: описанию реальных систем обычно присуща неопределенность. Например, для статической модели неопределенность можно учесть, записывал вместо (4.1) соотношение
y t F u t t , |
(5.1) |
где t - погрешность, приведенная к выходу системы. Причины неопределенности разнообразны:
–погрешности и помехи измерений входов и выходов системы (естественные погрешности);
–неточность самой модели системы, учитываемая путем искусственного введения в модель погрешности;
–неполнота информации о параметрах системы и т.д.
Среди различных способов уточнения и формализации неопределенности наибольшее распространение получил стохастический (вероятностный) подход, при котором неопределенные величины считаются случайными. Развитый понятийный и вычислительный аппараты теории вероятностей и математической статистики позволяют дать конкретные рекомендации по выбору структуры системы и оценке ее параметров. Классификация стохастических моделей систем и методов их исследования представлена в таблице 5.1.
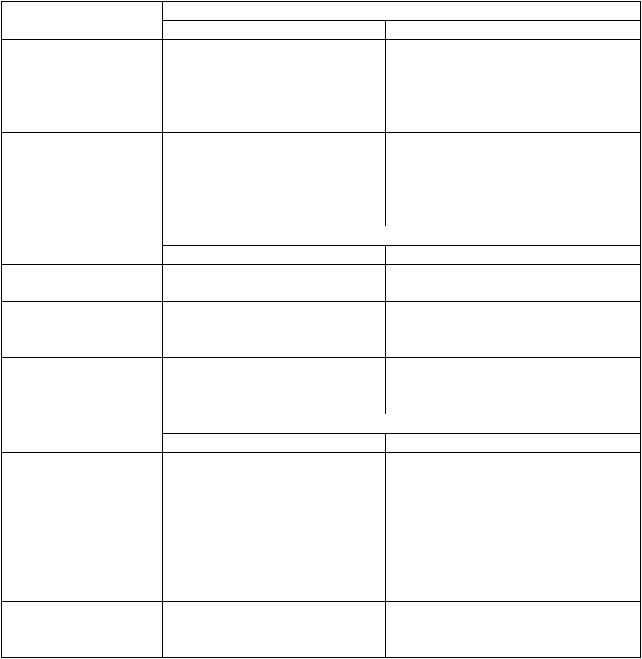
Таблица 5.1 – Стохастические модели систем
|
|
Статические |
|
|
|
|
Дискретные по U, Y |
Непрерывные по U, Y |
|||
Математический |
Схема |
независимых |
Регрессионные модели |
||
аппарат описания |
испытаний |
|
|
|
|
Методы оценки |
Статистические |
оценки |
Регрессионный анализ |
||
параметров и |
вероятности, дисперсионный |
|
|
|
|
анализа |
анализ |
|
|
|
|
Методы синтеза |
Стохастическое |
|
Планирование |
|
эксперимента, |
|
программирование |
стохастическое программирование |
|||
Области применения |
Задачи выбора |
из конечного |
Обработка результатов измерений |
||
|
числа вариантов (испытания, |
и испытаний |
|
|
|
|
управление) |
|
|
|
|
|
|
Динамические, дискретные по T |
|
|
|
|
Дискретные по U, Y |
Непрерывные по U, Y |
|||
Математический |
Марковские |
цепи, |
Стохастические |
|
разностные |
аппарат описания |
стохастические автоматы |
уравнения |
|
|
|
Методы оценки |
Стохастическое |
|
Статистическое |
|
оценивание |
параметров и |
моделирование, |
оценка |
состояний и параметров, анализ |
||
анализа |
переходных вероятностей |
стохастической устойчивости |
|||
Методы синтеза |
Динамическое |
|
Динамическое программирование |
||
|
программирование |
|
|
|
|
Области применения |
Компьютеры |
|
Импульсные и цифровые САУ |
||
|
|
Динамические, непрерывные по T |
|
||
|
Дискретные по U, Y |
Непрерывные по U, Y |
|||
Математический |
Системы |
массового |
Стохастические |
|
|
аппарат описания |
обслуживания, |
|
дифференциальные уравнения |
||
|
полумарковские процессы |
|
|
|
|
Методы оценки |
Теория |
массового |
Теория устойчивости |
||
параметров и |
обслуживания, |
имитационное |
|
|
|
анализа |
моделирование |
|
|
|
|
Методы синтеза |
Перебор, |
методы |
Оптимальное |
и |
адаптивное |
|
оптимального управления |
управление |
|
|
|
Области применения |
Системы |
обслуживания |
САУ, механические, тепловые, |
||
|
(вычислительные, |
электронные и другие процессы |
|||
|
производственные) |
|
|
|
|
Выводы и рекомендации основаны на эффекте усреднения: случайные отклонения результатов измерения некоторой величины от ее ожидаемого значения при суммировании взаимно уничтожаются и среднее арифметическое большого числа измерений оказывается близким к ожидаемому значению. Математические формулировки этого эффекта даются законом больших чисел и центральной предельной теоремой. Закон
больших чисел гласит, что если – случайные величины с
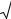
математическим ожиданием (среднее |
значение) |
M i |
|
a и дисперсией |
|||||||||||
M 1 a 2 2, то |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
a 0, |
|
|
|
|
|
(5.2) |
|||||
|
|
N |
|
|
|
|
|
||||||||
|
N |
1 |
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
при достаточно больших N. Это говорит о принципиальной возможности |
|||||||||||||||
сколь угодно точной оценки M i по измерениям. |
|
|
|
|
|
|
|||||||||
Центральная предельная теорема, уточняя (5.2)‚ утверждает, что |
|
||||||||||||||
|
|
|
1 |
|
|
a |
|
|
|
|
, |
(5.3) |
|||
|
|
|
|
N |
|
|
|
||||||||
|
|
|
N |
1 |
|
|
|
|
|
|
N |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
где – стандартная (M 0, M 2 1) нормально распределенная случайная величина.
Функция распределения нормальной случайной величины хорошо известна и детально затабулирована. Имеются в книгах по статистике и таблицы функций распределения других часто встречающихся случайных величин, например стьюдентовой. Однако нет необходимости добывать статистические таблицы, если под рукой есть компьютер с установленной системой MATLAB. В составе тулбокса STATISTICS есть модули, вычисляющие функции распределения и другие характеристики более двадцати распространенных типов случайных величин. Проиллюстрируем применение MATLAB на простой статистической задаче.
Формулировкам (5.2), (5.3) можно придать более строгий вид и это легко достижимо с помощью понятий вероятностной сходимости. Однако при попытке проверить условия этих строгих утверждений могут возникнуть трудности. В частности, в законе больших чисел и центральной предельной теореме требуется независимость отдельных измерений (реализаций) случайной величины и конечность ее дисперсии. Если эти условия нарушаются, то могут нарушаться и выводы. Например, если все измерения совпадают: 1 N , то, хотя все остальные условия выполняются, об усреднении не может быть и речи. Другой пример: закон больших чисел
несправедлив, если случайные величины 1, 2, N распределены по закону Коши (с плотностью распределения p x 1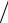 1 x2 ), не обладающему конечным математическим ожиданием и дисперсией. А ведь такой закон встречается в жизни! Например, по Коши распределена интегральная освещенность точек прямолинейного берега равномерно вращающимся прожектором, находящимся в море (на корабле) и включающимся в случайные моменты времени.
1 x2 ), не обладающему конечным математическим ожиданием и дисперсией. А ведь такой закон встречается в жизни! Например, по Коши распределена интегральная освещенность точек прямолинейного берега равномерно вращающимся прожектором, находящимся в море (на корабле) и включающимся в случайные моменты времени.
Но еще большие трудности вызывает проверка обоснованности самого употребления термина «случайный». Что такое случайная величина, случайное событие и т.д.? Часто говорят, что событие A случайно, если в результате эксперимента оно может наступить (с вероятностью p) или не наступить (с вероятностью 1 p). Все, однако, не так просто. Сама вероятность события может быть связана с результатами экспериментов лишь через частоту наступления события в некотором ряде (серии)
экспериментов: N NA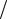 N , где NA – число экспериментов, в которых событие наступило; N – общее число экспериментов. Если числа N при достаточно большом N приближаются к некоторому постоянному числу pA :
N , где NA – число экспериментов, в которых событие наступило; N – общее число экспериментов. Если числа N при достаточно большом N приближаются к некоторому постоянному числу pA :
N pA, |
(5.4) |
то событие A можно назвать случайным, а число pA – его вероятностью. При этом частоты, наблюдавшиеся в различных сериях экспериментов, должны быть близки между собой (это свойство называется статистической устойчивостью, или однородностью). Сказанное относится и к понятию случайной величины, поскольку величина является случайной, если
случайными являются события для любых чисел a, b. Частоты наступления таких событий в длинных сериях экспериментов должны группироваться около некоторых постоянных значений.
Итак, для применимости стохастического подхода должны выполняться следующие требования:
1)массовость проводимых экспериментов, т.е. достаточно большое их
число;
2)повторяемость условий экспериментов, оправдывающая сравнение результатов различных экспериментов;
3)статистическая устойчивость.
Стохастический подход заведомо нельзя применять к единичным экспериментам: бессмысленны выражения типа “Вероятность того, что завтра будет дождь”, “с вероятностью 0.8 «Зенит» выиграет кубок” и т.п. Но даже если массовость и повторяемость экспериментов имеются, статистической устойчивости может и не быть, а проверить это - непростое дело. Известные оценки допустимого отклонения частоты от вероятности основаны на центральной предельной теореме или неравенстве Чебышева и требуют дополнительных гипотез о независимости или слабой зависимости измерений.
Опытная же проверка условия независимости еще сложнее, так как требует дополнительных экспериментов.
Как же построить модель системы, если неопределенность в задаче есть, но стохастический подход неприменим? Далее кратко излагается один из альтернативных подходов, основанный на теории нечетких множеств.
5.2 Нечеткие модели 5.2.1. Нечеткие множества и лингвистические переменные
В 1965 г. американский математик П. Заде опубликовал статью под названием “Fuzzy sets”, что можно перевести как «нечеткие множества». В статье было дано новое определение понятия множества, предназначенное для описания и исследования сложных, «плохо определенных» систем. К ним, в частности, относятся гуманистические системы, на поведение которых существенное влияние оказывают знания, суждения и эмоции человека. В таких системах наряду со строгими, объективными, количественными данными и результатами присутствуют неоднозначные, субъективные, качественные данные и результаты, что требует новых подходов.