100 C. Moreira and A. Wichert
mapping between this joint probability distribution over an utility function into a quantum-like scenario.
We propose to split Eq. 16 into two factors: one containing a classical probability and another containing the utility function. This procedure is inspired the Quantum Decision Theory model of Yukalov and Sornette (2015). In their model, a prospect πa is a composite event represented in the Hilbert space by an eigenstate |a . The probability of the prospect is composed of two factors: an utility factor, f (πa) (a factor containing the classical utility of a lottery) and an attraction factor, q(πa) (a probabilistic factor that results from the quantum interference e ect). More specifically, for a lottery La, the utility factor f (πa) corresponds to minimizing the Kullback-Leibler information functional, which in the simple case of uncertainty yields (Yukalov and Sornette 2015):
f (πa) = |
U (La ) |
. The attraction factor, on the other hand, represents the |
a U (La ) |
behavioural biases, which are expressed through quantum interference, and is a value between −1 < q(πa) < 1. The final probability of the prospect is then given by P r(πa) = f (πa) + q(πa).
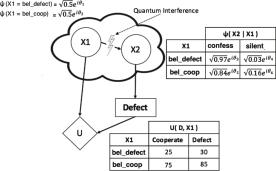
In this work, considering P r(πa) the classical probability distribution of the factor μ (X2, A) and f (πa) the classical utility corresponding to the choice of some action A of the same factor μ (X2, A), then we obtain
P r(πa) = P r (X1 = t) P r (X2|X1 = t) + P r (X1 = f ) P r (X2|X1 = f )
f (πa) = U (X1 = t, A) + U (X1 = f, A)
We can get the attraction factor, q(πa), by replacing the classical real numbers in P r(πa) by quantum-like amplitudes. The quantum interference e ects emerge by applying Born’s rule,
q(πa) = |ψ(X1 = t)ψ(X2|X1 = t) + ψ(X1 = f )ψ(X2|X1 = f )|2
q(πa) = |ψ(X1 = t)ψ(X2|X1 = t)|2 + |ψ(X1 = f )ψ(X2|X1 = f )|2 + 2Interf,
(17)
where the quantum interference term is given by
Interf = |ψ(X1 = t)ψ(X2|X1 = t)| |ψ(X1 = f )ψ(X2|X1 = f )| cos (θ1 − θ2) .
(18) Since the factor μ (X2, A) represented a probability distribution over the utility functions, we need to update the utility factor f (πa) in order to also represent this distribution over the quantum interference term. The quantum
interference term, for N random variables grows (Moreira and Wichert 2016)
N −1 N
2 |ψ(Xi = t)ψ(Xj |Xi = t)| |ψ(Xi = f )ψ(Xj |Xi = f )| cos (θi − θj ) .
i=1 j=i+1
The utility factor μ (X2, A) already specifies the utility function expressed in terms of the distribution of X2. When we consider X2 a quantum random variable, then this probability distribution is extended to incorporate the quantum