96 C. Moreira and A. Wichert
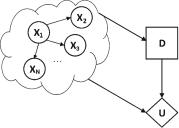
An example of a quantum-like influence diagram is presented in Fig. 2. One can notice the three di erent types of nodes: (1) random variable nodes (circleshape), denoted by X1, · · · , XN , of some Quantum-Like Bayesian Network, (2) a decision node (rectangle-shape), denoted by D, which corresponds to the decision that we want to make, and (3) an Utility node (diamond-shape), denoted by U , which in the scope of this paper, will represent the payo s in the Prisoner’s Dilemma Game.
The goal is to maximise the expected utility by taking into consideration the probabilistic inferences of the quantum-like Bayesian Network, which makes use of the quantum interference e ects to accommodate and predict violations to the Sure Thing Principle.
In the next sections, we will address each of these three components separately.
4 Quantum-Like Bayesian Networks
Quantum-like Bayesian Network have been initially proposed by Moreira and Wichert (2014, 2016) and they can be defined by a directed acyclic graph structure in which each node represents a di erent quantum random variable and each edge represents a direct influence from the source node to the target node. The graph can represent independence relationships between variables, and each node is associated with a conditional probability table that specifies a distribution of quantum complex probability amplitudes over the values of a node given each possible joint assignment of values of its parents. In other words, a quantum-like Bayesian Network is defined in the same way as classical network with the di erence that real probability values are replaced by complex probability amplitudes.
In order to perform exact inferences in a quantum-like Bayesian network, one needs to compute the:
–Quantum-Like full join probability distribution. The quantum-like full joint complex probability amplitude distribution over a set of N random variables ψ(X1, X2, ..., XN ) corresponds to the probability distribution assigned to all of these random variables occurring together in a Hilbert space. Then, the full joint complex probability amplitude distribution of a quantum-like Bayesian Network is given by:
N |
|
ψ(X1, . . . , XN ) = ψ(Xj |P arents(Xj )) |
(2) |
j=1 |
|
Note that, in Eq. 2, Xi is the list of random variables (or nodes of the network), P arents(Xi) corresponds to all parent nodes of Xi and ψ (Xi) is the complex probability amplitude associated with the random variable Xi. The probability value is extracted by applying Born’s rule, that is, by making the squared magnitude of the joint probability amplitude, ψ (X1, . . . , XN ):
P r(X1, . . . , XN ) = |ψ(X1, . . . , XN )|2 |
(3) |