Материал: искусственный интеллект
suai.ru/our-contacts |
quantum machine learning |
42 P. D. Bruza and L. Fell
making. For example, if the visual fluency is broken, then p(T = y|ρ) would be much higher than p(T = y|γ), reflecting that representational aspects of the image dominate decision making of image trustworthiness.
In addition, the following probabilistic relationships are a consequence of the decision model:
p(R1 = y) = p(R1 = y, C1 = y) + p(R1 = y, C1 = n) = p(R1 = y, C2 = y) + p(R1 = y, C2 = n) p(R2 = y) = p(R2 = y, C1 = y) + p(R2 = y, C1 = n) = p(R2 = y, C2 = y) + p(R2 = y, C2 = n)
and the converse
p(C1 = y) = p(C1 = y, R1 = y) + p(C1 = y, R1 = n) = p(C1 = y, R2 = y) + p(C1 = y, R2 = n) p(C2 = y) = p(C2 = y, R1 = y) + p(C2 = y, R1 = n) = p(C2 = y, R2 = y) + p(C2 = y, R2 = n)
The preceding probabilistic relationships express that decision making around content and representation do not influence each other. For example, the probability of a decision that a subject trusts Putin (the person), denoted p(C1 = y), does not vary according to whether subject decides that image has been manipulated, say, denoted p(C1 = y, R1 = y) + p(C1 = y, R1 = y) or whether they detect something unexpected in the image, denoted p(C1 = y, R2 = y) + p(C1 = y, R2 = y).
S
C1 |
C2 |
R1 |
R2 |
γ ρ
T
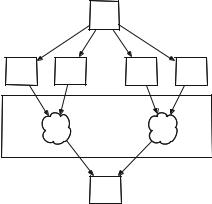
Fig. 1. Probabilistic fusion model of trust

suai.ru/our-contacts |
quantum machine learning |
Are Decisions of Image Trustworthiness Contextual? A Pilot Study |
43 |
3 Contextuality
A Bell scenario experiment involves two systems C (content) and R (representation). The content system C is probed with two questions modeled by bivalent variables C1 and C2 both of which range over the outcomes {y, n}. Similarly for system R with variables R1 and R2. Four measurement contexts are defined by jointly measuring one variable from each system:
|
|
|
|
|
R |
|
|
||
|
|
|
|
R1 |
|
R2 |
|
|
|
|
|
|
|
y n |
|
y n |
|
|
|
C1 |
y p1 p2 |
|
p5 p6 |
|
|
||||
|
|
||||||||
C |
|
n p3 |
p4 |
|
p7 p8 |
|
(1) |
||
|
|
|
|
|
|
|
|
|
|
|
2 y |
p9 |
p10 |
|
p13 p14 |
|
|
||
C |
|
n |
p11 |
p12 |
|
p15 p16 |
|
|
|
According to the first principle of Contextuality-by-Default, random variables should be indexed according to the experimental conditions in which they are measured [5]. For example, variable C1 is jointly measured with R1 in one experimental condition as well as being jointly measured with a variable R2 in another experimental condition. For this reason, two variables C11 and C12 are introduced. The same holds for the other three random variables resulting in eight random variables. Their expectations are computed as follows [4]:
C11 = 2(p1 + p2) − 1 |
(2) |
||
C12 = 2(p5 + p6) − 1 |
(3) |
||
C21 = 2(p9 |
+ p10) − 1 |
(4) |
|
C22 = 2(p13 + p14) − 1 |
(5) |
||
R11 |
= 2(p1 |
+ p3) − 1 |
(6) |
R12 |
= 2(p9 |
+ p11) − 1 |
(7) |
R21 |
= 2(p5 |
+ p7) − 1 |
(8) |
R22 |
= 2(p13 + p15) − 1 |
(9) |
|
Analysis of contextuality in Bell scenario experiments relies on the no-signalling condition. The experience so far in quantum cognition is that it is challenging to design experiments where this condition holds [6]. Moreover, the question that this challenge poses is whether any meaningful conception of contextuality exists when signalling is present. [4] have presented theory that specifies a threshold for signalling below which meaningful contextuality analysis can be performed. Using their approach, the degree of signalling 0 between the content and representation systems is computed as follows:
1
0 = 2 (|C11 − C12| + |C21 − C22| + |R11 − R12| + |R21 − R22|) (10)
suai.ru/our-contacts |
quantum machine learning |
44 P. D. Bruza and L. Fell
This sum is essentially based on the sum of di erences between marginal prob-
abilities. If |
0 ≥ 1, |
then the di erences between the marginal probabilities |
is deemed |
too great |
for any meaningful conception of contextuality. When |
0 ≤ 0 < 1, then failure of any of the four inequalities signifies the presence of contextuality. Note that these inequalities revert to the standard CHSH inequal-
ities when signalling is not present ( 0 = 0). |
|
|
|
|C11R11 |
+ C12R12 + C21R21 − C22R22| ≤ 2(1 + |
0) |
(11) |
|C11R11 |
+ C12R12 − C21R21 + C22R22| ≤ 2(1 + |
0) |
(12) |
|C11R11 |
− C12R12 + C21R21 + C22R22| ≤ 2(1 + |
0) |
(13) |
| − C11R11 |
+ C12R12 − C21R21 + C22R22| ≤ 2(1 + |
0) |
(14) |
where |
|
|
|
C11R11 = (p1 |
+ p4) − (p2 + p3) |
(15) |
|
C12R12 |
= (p5 |
+ p8) − (p6 + p7) |
(16) |
C21R21 |
= (p9 |
+ p12) − (p10 + p11) |
(17) |
C22R22 |
= (p13 + p16) − (p14 + p15) |
(18) |
|
4 Experiment
4.1Subjects
Participants consisted of 34 workers using the online crowdsourcing platform, Amazon Mechanical Turk (AMT), and 85 workers using the online crowdsourcing platform, Prolific. Both platforms are used by researchers, amongst others, to post experiments and surveys to a wide audience of thousands of potential participants to view and complete. Participants involved in the present study were able to view any project before agreeing to participate, and were paid a small but standard amount ($1.50 for AMT participants, £1.00 for Prolific participants) per HIT. Both AMT and Prolific platforms allow workers of certain skill, ability or reputation to be specified for a HIT. In this experiment, workers of at least 96% or greater approval rating were selected to balance worker quality with the need to attract a su cient number of participants. De-identified worker IDs were used to ensure participants did not participate in more than one condition. Participants were sourced from a wide variety of countries, including the US, UK, France, Italy, Australia, New Zealand, and South Africa. A test question was first presented to participants to ensure they could properly view the experiment on their browsers. Data collected from participants who could not correctly answer this test question, did not respond to written segments of the experiment in English, or who were deemed not to have understood instructions based on the relevancy/quality of their responses, were excluded from the study. In total, 3 workers were excluded.

suai.ru/our-contacts |
quantum machine learning |
Are Decisions of Image Trustworthiness Contextual? A Pilot Study |
45 |
4.2Design and Materials
Images were selected to fall into two subject categories: untrustworthy subjects and neutral subjects. The first two images depicted infamously untrustworthy subjects: an image of Vladimir Putin2, and an image of a shark3. Figure 2 depicts the images of the neutral subjects: an unknown woman4, and an antelope with her calf 5. All images were manipulated in a detectable way. Image presentation was counter-balanced, and each image was accompanied by three responses: A question-pair, a confidence rating, and a reasoning explanation. The question pairs consisted of combinations of the following four questions:
Fig. 2. Image stimuli
–Do you think the person in this image is honest? (for a human image subject)/ Do you think the animal in this image is safe? (for an animal image subject) (Honest/Safe)
–Do think this image has been altered? (Altered)
–Do you think the person in this image is dishonest? (for a human image subject)/ Do you think the animal in this image is unsafe? (for an animal image subject) (Dishonest/Unsafe)
–Do think this image has been unaltered? (Unaltered)
The questions were intended to capture a decision about the subject of the image (human or animal) as well as the features of the image itself (the representation of the subject). The first two questions are the opposite counterparts of the second two. Responses to opposing questions were expected to be unique to each other, based on research showing asymmetry between positive and negatively worded questions [14]. The pairs were combined in the following four ways to form the 4 measurement contexts in a Bell scenario design where two variables (H and D) are related to the content of the image and two variables (A and U ) are related to its representation.
2https://www.iol.co.za/news/world/us-releases-putin-list-13013292.
3https://www.complex.com/life/2017/11/scientists-discover-ancient-shark-with-300- teeth-and-people-want-no-part-of-it.
4Sourced from Pixabay.
5Sourced from Flickr (Igor Shpilenok) under the following license: https:// creativecommons.org/licenses/by/2.0/.
suai.ru/our-contacts |
quantum machine learning |
46 P. D. Bruza and L. Fell
–Honest/Safe (H ) and Altered (A)
–Honest/Safe (H ) and Unaltered (U )
–Dishonest/Unsafe (D) and Altered (A)
–Dishonest/Unsafe (D) and Unaltered (U )
Each image was displayed for 1 s. Placed in a Dual Process context, decisions of trust are assumed to be based on a ective characteristics (the ‘Hot’ system) as well as more rational characteristics (the ‘Cold’ system). The time pressure was designed to access the ‘Hot’ system.
4.3Procedure
Participants were instructed to peruse the task (one condition of the experiment) before agreeing to participate. They were given a test question to ensure they understood instructions and could properly view the images displayed in the task before continuing. This was done by presenting an image of a cat, along with a question asking what animal featured in the image. If the participant could correctly answer this, they were asked to continue to the rest of the task.
Following this question were instructions aimed at introducing the question pair as well as preparing users for the shortness of the image display time. Once understood, users were asked to scroll to the first image. Each image and question group was structured in the following way:
1.A short repeat of image reveal instructions
2.A blank image with the text ‘Click to show image’ Once clicked, this changed to one of the images outlined earlier, with a number beneath counting down from 1 s. Once 1 s had elapsed, the image disappeared.
3.First response: The full question pair is displayed again (the same question pair as in the instructions and accompanying each image of the HIT), as well as a short version (e.g., Safe/Altered). Beneath this was a multiple choice format with the answers:
(a)Yes, Yes
(b)Yes, No
(c)No, Yes
(d)No, No
These were aligned to the short version of the questions to avoid confusion about what each answer referred to.
4.Second response: Participants were then asked to rate, on a slider with a scale from 1 to 7, their confidence in the answers they gave.
5.Third response: Lastly, participants were asked to provide reasoning for the answers they gave in written form. This was to gather further insight into the first response, as well as to determine whether participants correctly understood the questions being asked.
This was repeated for all 4 images, and was followed by a question asking for the country the participants resided in, and a ‘Submit’ button.