Материал: Факторы, влияющие на среднемесячную номинальную заработную плату населения по регионам Российской Федерации
Для изучения влияния фактора X4 на результирующий
признак Y сначала нужно построить поле корреляции (рис. 4).
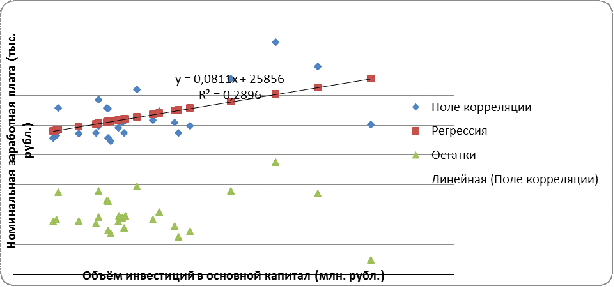
Рис. 4 «Поле корреляции»
При рассмотрении графика сложно точно предположить, какой вид зависимости существует между переменными. Однако мы можем проанализировать следующие виды зависимостей:
Линейная зависимость;
Квадратичная зависимость;
Гиперболическая зависимость;
Степенная зависимость;
Показательная зависимость;
Экспоненциальная зависимость;
Логарифмическая зависимость.
Каждая из рассмотреннчых моделей получилась значимой по критерию Фишера, поскольку Fстат>Fкр. Для того, чтобы выбрать качественную модель, необходимо использовать следующие критерии:
Коэффициент детерминации R^2. С помощью него можно оценить тесноту связи, и чем R^2 ближе к единице, тем лучше регрессия описывает зависимость между зависимой и объясняющими переменными;
Средняя ошибка аппроксимации А. Лучше та модель, у которой наименьшая ошибка аппроксимации. На практике значение этой ошибки в пределах 5-7 % говорит о хорошем соответствии модели выбранным данным;
Стандартная ошибка регрессии Sост. Чем меньше этот показатель, тем лучше построенная модель;
Метод абсолютных отклонений. Лучшая модель та, которая имеет наименьший показатель МАD.
Для выбора лучшей модели рассмотрим таблицу
сравнения критериев:
Таблица 11
Таблица сравнения критериев
|
Тип модели |
R^2 |
A |
Sost |
MAD |
|
1. Линейная |
0,290 |
15,00% |
6886,262 |
5133,171311 |
|
2. Квадратичная |
0,314352636 |
14,86% |
6910,837742 |
5103,553931 |
|
3. Гиперболическая |
0,177 |
16,49% |
7413,272 |
5682,178706 |
|
4. Степенная |
0,262 |
14,50% |
0,188 |
5112,279771 |
|
5. Показательная |
0,2709444 |
14,46% |
0,1866305 |
5057,083385 |
|
6. Экспоненциальная |
0,2709444 |
14,46% |
0,1866305 |
5057,083385 |
|
7. Логарифмическая |
0,2686112 |
15,46% |
6987,3537596 |
5314,151177 |
В результате сравнения полученных критериев наилучшей моделью является показательная и/или экспоненциальная. Она лучше аппроксимирует выборочные данные и имеет более точный прогноз. Однако для исследования факторов X3 и Y была выбрана линейная модель из-за ее простоты. Поэтому построим модель парно-линейной регрессии и исследуем её качество.
С помощью функции ЛИНЕЙН из категории
«Статистические» строим модель парной линейной регрессии (см. табл. 12).
Таблица 12 инвестиция регрессия заработный капитал
Модель парной линейной регрессии
|
|
b |
a |
|
|
|
0,081 |
25855,921 |
|
|
mb - стандартная ошибка коэфф., b |
0,026 |
2695,486 |
mа - стандартная ошибка коэфф., а |
|
R^2 - коэфф., детерминации |
0,290 |
6886,262 |
Sост. - оценка стандартного отклонения остатков |
|
F статистика |
9,785 |
24,000 |
Число степеней свободы n-2 |
|
Регрессионная сумма квадратов |
464001142,5 |
1138094422 |
Остаточная сумма квадратов |
По найденной таблице было записано уравнение выборочной регрессии (y^=25855,921+0,081x) и экономическая интерпретация коэффициентов линейной регрессии:
Коэффициент b=0,081 показывает, что при увеличении объёма инвестиций в основной капитал на 1 млн. рубл., среднемесячная заработная плата увеличивается на 8,1 коп.
Коэффициент a=25855,921 показывает, что при отсутствии инвестиций в основной капитал (X4=0), среднемесячная заработная плата равна 25855,921 рубл.
Также, были вычислены остатки по
формуле (![]() ) и построен
график остатков (см. рис. 4).
) и построен
график остатков (см. рис. 4).
Из вида поля корреляции можно сделать предположение, что гомоскедастичность отсутствует, а присутствует гетероскедастичность. Проверим наше предположение по двум тестам: по тесту Голдфелда-Квандта и тесту Спирмена. По тесту Голдфелда-Квандта наше предположение подтвердилось. В модели действительно присутствует гетероскедастичность, так как Fg= 4,1 > Fkp= 3,4. Однако тест Спирмена показал противоположный результат, поскольку tr=1,95<tкрит=2,06 в модели присутствует гомоскедастичность. Такое разногласие, скорее всего, связано с небольшим объемом выборки. Наличие гетероскедастичности приводит к тому, что возникают большие остатки, что приводит к высоким ошибкам прогнозирования.
Кроме того, из вида поля корреляции можно предположить, что в модели присутствует положительная автокорреляция. Используя критерий Дарбина-Уотсона мы выяснили, DW=1,39 принадлежит интервалу [dl=1,3;du=1,46], следовательно гипотеза о положительной автокорреляции отвергается, автокорреляция находится в зоне неопределенности. Это означает, что у нас нет достаточных оснований для принятия решения.
Мною была найдена величина средней ошибки аппроксимации =15,00% и был сделан следующий вывод: поскольку средняя ошибка аппроксимации больше 10%,то построенная модель плохо аппроксимирует выборочные данные. Незначительно превышает 7 %, поэтому можно считать, что построенная модель является удовлетворительной.
Для более уточненного анализа производим проверку значимости регрессии в целом (по критерию Фишера). Находим F-статистика и F-критическое.
Значение F-статистика берем из таблицы (F-статистика), а F-критическое находим при помощи функции FРАСПОБР(5%;1;24).
В результате получаем: статистика= 9,784; F-критическое=4,259.
Так как Fстат.>Fкр., то модель значима в целом.
Говоря о значимости коэффициентов
регрессии (по критерию Стьюдента), нужно отметить, что коэффициенты а, b и r
являются значимыми, т.к tа> tкр; tb>tкр и tr>tкр. (см. табл. 13).
Таблица 13
Показатели значимости коэффициентов
|
ta |
9,592303964 |
> |
|
2,063898547 |
коэффициент а значим |
|
tb |
3,128066653 |
> |
tкр |
2,063898547 |
коэффициент b значим |
|
tr |
3,128066653 |
> |
|
2,063898547 |
коэффициент r значим |
Значение параметра а показывает, что при отсутствии инвестиций в основной капитал с вероятностью 0,95 среднемесячная заработная плата принимает значение в диапазоне [20292,7113; 31419,13052].
Значение параметра β показывает, что при увеличении инвестиций в основной капитал на 1 млн. рубл. с вероятностью 0,95 среднемесячная заработная плата увеличивается на значение в диапазоне [0,027606745; 0,134690429].
Далее был построен точечный прогноз значения Y при значении X в 3 раза больше, чем среднее значение X. Прогнозное значение фактора равно 269765,61. А прогнозное значение показателя у^р равно 47747,01. Стандартная ошибка прогноза функции регрессии получилась равной 4857,05, а ошибка индивидуального значения - 8426,83. Так же вычислен доверительный интервал параметр для условного математического ожидания: [37722,55356; 57771,48587] и доверительный интервал для индивидуального значения [30354,88429; 48968,49727].
Оценим тесноту связи с помощью показателей корреляции и детерминации.
Коэффициент корреляции rxy =0,53. Следовательно по шкале Чеддока между Х и У наблюдается заметная прямо-линейная зависимость.
Коэффициент детерминации R2=0,289, говорит о том, что 28,9% вариации (дисперсии, разброса) среднемесячной заработной платы. объясняется изменением численности населения, а остальные 71,1% факторами, не включёнными в модель.
Отсюда можно сделать вывод, что математическая
модель, выражающая данную зависимость объясняющей переменной, подходит для
описания зависимой переменной. Поэтому данный фактор будет включён в модель
множественной регрессии.
Глава 3 Исследование влияния совокупности факторов
3.1 Процедура отбора переменных в множественной
линейной регрессии
Для того чтобы построить качественную модель
множественной регрессии, необходимо провести пошаговую процедуру включения
существенных переменных в анализируемую модель. Для этого вначале построим
корреляционную матрицу, найдём коэффициенты корреляции между всеми парами
объясняющих переменных и сделаем предположение о наличии или отсутствии
мультиколлинеарности (см. табл. 14).
Таблица 14
Корреляционная матрица
|
|
rx1x2 |
rx1x3 |
rx1x4 |
|
1 |
0,99178466 |
0,796576625 |
|
|
0,99178466 |
1 |
0,822579317 |
0,393064873 |
|
0,796576625 |
0,822579317 |
1 |
0,594123616 |
|
0,380174721 |
0,393064873 |
0,594123616 |
1 |
Можно сделать предположение о наличие мультколлиниарности, поскольку между факторами x1 и x2, x1 и x3, x2 и x3 высокая взаимная зависимость(rxixj>0,7). Значит, не следует включать одновременно факторы в модель.
Для того, чтобы определить, какой из факторов
связан с Y в большей степени и в какой последовательности следует включать
факторы в модель, необходимо построить скорректированную корреляционную матрицу
(см. табл. 15)
Таблица 15
Скорректированная корреляционная матрица
|
|
y |
ryx1 |
ryx2 |
ryx3 |
ryx4 |
|
y |
1 |
-0,194114115 |
-0,121934895 |
0,245807435 |
0,538164834 |
|
x1 |
-0,194114115 |
1 |
0,99178466 |
0,796576625 |
0,380174721 |
|
x2 |
-0,121934895 |
0,99178466 |
1 |
0,822579317 |
0,393064873 |
|
x3 |
0,245807435 |
0,796576625 |
0,822579317 |
1 |
0,594123616 |
|
x4 |
0,538164834 |
0,380174721 |
0,393064873 |
0,594123616 |
1 |
Исходя из полученных данных мы можем сделать вывод, что первым в модель следует включать фактор х4 (объём инвестиций в основной капитал), так как он имеет самый высокий коэффициент корреляции с признаком у, затем фактор х3,х1,х2.
Следующим шагом необходимо проверить целесообразность включения фактора х3 (валовый региональный продукт) в модель ух4, используя частный критерий Фишера.
Так как частный критерий Фишера равен 0,28, а табличное значение 4,28, то включение данного фактора в модель yx4 нецелесообразно.
Аналогично с фактором х1 (численность населения), где Fч=8,15 > Fкр=4,28. Из этого следует, что фактор х1 целесообразно включать в модель ух4.
Последний фактор х2 (численность экономически активного населения) включать в модель целесообразно, т.к. Fч=5,23> Fкр=4,28.
Поскольку факторы х1 и х2 в модель yx4 включать целесообразно, проверим целесообразность включения фактора х1 в модель ух2х4.
Получилось следующее: Fч=19,49>Fкр=4,3, значит включение переменной х1 оправдано.
Таким образом, исключив нецелесообразный фактор
х3, можно приступить к построению множественной линейной регрессии х1, х2, x4.
3.2 Построение множественной регрессии
Для построения множественной регрессии нужно исследовать влияние таких факторов, как:- численность населения за 2014 г;- численность экономически активного населения в 2014 г., тыс. человек;- объём инвестиций в основной капитал в 2014 г., млн. руб.
Объясняемым фактором по-прежнему является Y - среднемесячная заработная плата работников за 2014 год. Исходные данные представлены выборкой объема n=26.
С помощью функции ЛИНЕЙН из категории
«Статистические» построим модель множественной регрессии (см. табл. 16):
Таблица 16
Модель множественной регрессии
|
b4 |
b2 |
b1 |
a |
|
0,097476688 |
131,4519007 |
-0,074594338 |
30395,69181 |
|
0,019434042 |
33,27883906 |
0,016894172 |
2698,538067 |
|
0,693103801 |
4727,468281 |
#Н/Д |
#Н/Д |
|
16,56182519 |
22 |
#Н/Д |
#Н/Д |
|
1110418525 |
491677039,6 |
#Н/Д |
#Н/Д |
Получим уравнение регрессии: y^=a+b1x1+b2x2 +b4x4, то есть y^= 30395-0,07х1+131,45х2+0,09х4
Дадим экономическую интерпретацию коэффициентов множественной регрессии:
а - показывает, что если не будет численности населения (х1=0), экономически активного населения (х2=0) и объёма инвестиций в основной капитал (х4=0), то среднемесячная зарплата составит 30 395 руб.;- показывает, что при увеличении численности населения на 1 человека, средняя заработная плата уменьшается на 0,07 рублей, при неизменных остальных факторах.- показывает, что при увеличении численности экономически активного населения на 1 человека, средняя заработная плата увеличивается на 131 рубль, при неизменных остальных факторах.- показывает, что при увеличении объёма инвестиций в основной капитал на 1 млн. рубл., средняя заработная плата увеличивается на 0,09 рублей, при неизменных остальных факторах.
Проверим значимость уравнения множественной
линейной регрессии в целом по критерию Фишера:
Fстатистика
16,56182519
>
Fкрит
3,049125006
Поскольку Fстат.>Fкрит., значит уравнение
регрессии значимо в целом.
Проверим значимость коэффициентов множественной
линейной регрессии по критерию Стьюдента при уровне значимости 5% (см. табл.
17):
Таблица 17
Показатели значимости коэффициентов
множественной регрессии
ta
11,26376247
>
а
значим
tb2
-4,415388812
>
tкр
2,073873058
b1
значим
tb3
3,950014616
>
b2
значим
tb4
5,015770066
>
b3
значим
Все факторы значимы, из этого следует, что их
можно использовать для дальнейшего исследования.
Для статистически значимых коэффициентов были
построены доверительные интервалы (см. табл. 18):
Таблица 18
Доверительные интервалы
α
24799,26641
35992,1172
β1
-0,109630706
-0,03955797
β2
62,43581295
200,4679884
β4
0,057172951
0,137780424
Дадим их экономическую интерпретацию:
α - показывает, что
если не будет численности населения (х1=0), экономически активного населения
(х2=0) и объёма инвестиций в основной капитал (х4=0), то среднемесячная зарплата
изменяется в пределах [24799,3; 35992,1] с вероятностью 95%.
β1 - показывает, что при
увеличении численности населения на 1 человека, средняя заработная плата
изменяется в пределах [-0,109; -0,039] с вероятностью 95%
β2 - показывает, что при
увеличении численности экономически активного населения на 1 человека, средняя
заработная плата изменяется в пределах [62,435; 200,467] с вероятностью 95%
β4 - показывает, что при
увеличении объёма инвестиций в основной капитал на 1 млн. рубл., средняя
заработная плата изменяется в пределах [0,057; 0,137] с вероятностью 95%
Говоря о качестве построенной регрессии следует
отметить, что модель имеет неплохую объясняющую способность, поскольку
коэффициент детерминации R^2= 0,69 показывает, что 69% изменения средней заработной
платы объясняется изменениями факторов, включенных в модель, а остальные 31% не
включенными факторами.
Так как R² близок
к 1, уравнение регрессии неплохо аппроксимирует эмпирические данные.
Средняя ошибка аппроксимации (A=11,10% > 10%)
незначительно превышает 10%, поэтому можем считать, что построенная модель
является удовлетворительной.
Был вычислен скорректированный коэффициент
детерминации: R^2adj=0,65.
В ходе исследования были найдены
стандартизованные коэффициенты регрессии b'i и частные средние коэффициенты
эластичности Эi. '=-4,09;'=3,68;'=0,64.
Поскольку b1' больше, чем все остальные
стандартизированные коэффициенты, можем считать, что фактор x1 (численность
населения) больше влияет на y (среднемесячная заработная плата), чем другие
факторы (x2,х4)
Средней коэффициент эластичности Эср1=-2,44
показывает, что при увеличении x1 (численности населения) на 1 %, у
(среднемесячная заработная плата) уменьшается на 244%. Средней коэффициент
эластичности Эср2=2,26 показывает, что при увеличении х2 (численности
экономически активного населения) на 1%, у (среднемесячная заработная плата)
увеличивается на 226%. Средней коэффициент эластичности Эср4=0,26 показывает,
что при увеличении x4 (объёма инвестиций в основной капитал ) на 1 %, y
(среднемесячная заработная плата ) увеличивается на 26%.
Чтобы определить наличие мультиколлинеарности в
данной модели, необходимо построить матрицу выборочных коэффициентов корреляции
Q с помощью функции КОРЕЛЛ (см. табл. 19).
Таблица 19
Матрица выборочных коэффициентов корреляции Q
rx1х2
rx1х4
1
0,99178466
0,380174721
rx1х2
0,99178466
1
0,393064873
rx2х4
0,380174721
0,393064873
1
rx1х4
rx2х4
Проанализировав полученную матрицу, можно
предположить, что между факторами х1 и х2 существует мультиколлинеарность, так как
rx1x2 больше 0,7.
Необходимо проанализировать частные коэффициенты
детерминации, которые были получены в результате возведения в квадрат частных
коэффициентов корреляции:^2yx1 = 0,47 показывает, что на 47 % изменение средней
заработной платы объясняется изменением численности населения, а оставшиеся 53
% - факторами, не включёнными в модель.^2yx2 =0,41 показывает, что на 41 %
изменение средней заработной платы объясняется изменением численности
экономически активного населения, а оставшиеся 59 % - факторами, не включёнными
в модель.^2yx4 =0,53 показывает, что на 53% изменение средней заработной платы
объясняется изменением объёма инвестиций в основной капитал, а оставшиеся 47 %
- факторами, не включёнными в модель.
В результате проверки значимости частных
коэффициентов корреляции было выявлено, что все коэффициенты значимы, так как
tr>tкр по модулю.
tryx1/x2x4
-4,415388812
tryx2/x1x4
3,950014616
tryx4/x1x2
5,015770066
tкр(5%,
22)=
2,073873058
Чтобы убедиться в наличии
мультиколлинеарности вычислим определитель матрицы Таким образом, при построении
множественной модели не удалось полностью избежать мультиколенниарность ,
поскольку между факторами х1 и х2 она существует, так как rx1x2 больше 0,7.
Поэтому, необходимо построить модель, состоящую из двух факторов, х2 и х4. О
том, какая модель является лучшей будет сказано в заключение.
Заключение
Во время проведения исследования
была выявлена и изучена зависимость каждого фактора на результирующий признак
как в отдельности, так и в совокупности. Для этого были построены четыре парные
линейные регрессии и две модели множественной регрессии.
Проведённое исследование показало,
что значимыми можно признать не все построенные модели. Модель, отражающая
зависимость среднемесячной номинальной заработной платы от численности
населения, а также модель, отражающая зависимость среднемесячной номинальной
заработной платы от численности экономически активного населения и модель,
отражающая зависимость среднемесячной номинальной заработной платы от валового
регионального продукта являются незначимыми. Модель, отражающая зависимость
среднемесячной номинальной заработной платы от объёма инвестиций в основной
капитал значима.
Для того чтобы построить
качественную множественную регрессию, необходимо, во-первых, проверить
отсутствие или присутствие мультиколлинеарности в модели, во-вторых проверить
целесообразность включения фактора хi в модель, используя частный критерий
Фишера. Построив корреляционную матрицу, обнаружилось, что между факторами
x1x2, x1x3, x2x3 высокая взаимная зависимость, а значит можно сделать
предположение о наличие мультколлиниарности. Это говорит о том, что не следует
включать одновременно факторы в модель. Поскольку фактор х4 имеет самый высокий
коэффициент корреляции с признаком у, значит его следует включить в модель
первым, а затем фактор х3,х1,х2. Как оказалось не все факторы можно включать в
модель множественной регрессии. Включение фактора х3 в модель ух4
нецелесообразно, поскольку Fч=0,27<Fкр=4,27. Поэтому фактор х3 был исключён
из модели. Сделав проверку включения факторов х1 в модель ух4, а также х2 в
модель ух4, а затем х1 в модель ух2х4, оказалось, что включение всех этих
факторов целесообразно. Поэтому для исследования была построена модель
множественной регрессии y^=a+b1x1+b2x2+b4x4 или
y^=30395-0,07х1+131,45х2+0,09х4.
Полученной модели можно дать
экономическую интерпретацию: при увеличении численности населения на 1
человека, средняя заработная плата уменьшается на 0,07 рублей, при неизменных
остальных факторах; при увеличении численности экономически активного населения
на 1 человека, средняя заработная плата увеличивается на 131 рубль, при неизменных
остальных факторах; при увеличении объёма инвестиций в основной капитал на 1
млн. рубл., средняя заработная плата увеличивается на 0,09 рублей, при
неизменных остальных факторах. Коэффициент а интерпретировать невозможно, так
как тяжело представить регион, где не существует людей, способных и желающих
работать и где нет инвестиций в основной капитал.
Анализ данной модели установил, что
69% изменения средней заработной платы в 2014 году объясняется изменением
численности населения, численности экономически активного населения и объёма
инвестиций в основной капитал. При увеличении x1 (численности населения) на 1
%, у (среднемесячная заработная плата) уменьшается на 244%. При увеличении х2
(численности экономически активного населения) на 1%, у (среднемесячная
заработная плата) увеличивается на 226%. При увеличении x4 (объёма инвестиций в
основной капитал ) на 1 %, y (среднемесячная заработная плата ) увеличивается
на 26%.
Данная модель значима в целом по
критерию Фишера, с удовлетворительной ошибкой аппроксимации и достаточно
большим коэффициентов детерминации, т.е. в целом пригодной для прогнозирования.
Однако между факторами х1 и х2 существует мультиколлинеарность в стохастической
форме. Определитель матрицы Но следует иметь в виду, что у
нескольких факторов, а именно х2 и х4, нельзя точно определить присутствует
гомоскедастичность или гетероскедастичность, так как результаты тестов
Голдфелда-Квандта и Спирмена противоречат друг другу. Скорее всего, неточность
связана с небольшим объёмом выборки. Кроме того, у факторов х1 и х4
автокорреляция находится в зоне неопределенности. Это означает, что у нас нет
достаточных оснований для принятия решения. Все этого говорит о том, что в
построенной модели возможны ошибки, которые следует принять к сведению при
построении прогнозов.
Чтобы уменьшить наличие
мультиколлинеарности было решено исключить из модели y^=a+b1x1+b2x2+b4x4
переменную х1.
Была построена множественная
регрессия y^=a+b2x2+b4x4 или y^=31806-14,08х2+0,104х4.
Несмотря на отсутствие
мультиколлинеарности данная модель, по -моему мнению, получилась хуже.
Сделаем сводную таблицу и сравним
модель парной регрессии, которая значима, и модели множественной регрессии по
наиболее существенным критериям (см. табл. 20):
Таблица 20
Сравнение моделей
Тип
модели
R^2
R^2adj
Sост
MAD
A
Парная
y^=a+bx4
0,289621389
0,26002228
6886,261751
5133,171311
15,00%
y^=a+b1x1+b2x2+b4x4
0,693103801
0,651254319
4727,468281
3603,473623
11,10%
y^=a+b2x2+b4x4
0,421142735
0,37080732
6349,887562
4626,062355
13,89%
Как мы видим, по большинству критериев лучшая
модель - множественная модель с тремя факторами y^=a+b1x1+b2x2+b4x4. Данная
модель в большей степени влияет на величину заработной платы, чем остальные.
Скорее всего это связано с тем, что сами работники, их количество и инвестиции
в основной капитал заставляют работодателей изменять величину заработной платы.
В заключении хотелось бы отметить, что данный
вопрос требует особого внимания и дальнейшего изучения, так как заработная
плата играет значительную роль в развитии экономики, государства и жизни
каждого человека. Дальнейшее изучение данного вопроса поможет в построении
прогнозов и принятии целесообразных решений, а возможно приведёт к более
качественной модели.
Список использованных источников
Евсеев
Е.А., Буре В.М., Эконометрика: Учебник, Изд-во МБИ, 2007 г.
Тарашнина
С. И., Панкратова Я.Б., Выполнение курсовой работы по эконометрике:
учебно-методическое пособие, 2007 г.
Курс
эконометрика: электронный ресурс URL:
http://eos.ibi.spb.ru/course/view.php?id=608
Сайт
федеральной статистики: электронный ресурс URL: <http://www.gks.ru/>
Федеральная
служба государственной статистики (Росстат): электронный ресурс URL:
http://government.ru/department/250/events/
![]() =1,52374E+29.
По этому критерию мультиколлиниарность отсутствует, поскольку определитель
матрицы не равен нулю.
=1,52374E+29.
По этому критерию мультиколлиниарность отсутствует, поскольку определитель
матрицы не равен нулю.
![]() хоть и отличен от нуля, но очень
мал. Однако стандартные ошибки коэффициентов регрессии получились небольшими, и
коэффициенты получились значимы по t-критерию. Несмотря на то, что свойства
несмещённости и эффективности оценок остаются в силе, мультиколлинеарность в
любом случае затрудняет разделение влияния объясняющих переменных на поведение
зависимой переменной и делает оценки коэффициентов регрессии ненадёжными.
хоть и отличен от нуля, но очень
мал. Однако стандартные ошибки коэффициентов регрессии получились небольшими, и
коэффициенты получились значимы по t-критерию. Несмотря на то, что свойства
несмещённости и эффективности оценок остаются в силе, мультиколлинеарность в
любом случае затрудняет разделение влияния объясняющих переменных на поведение
зависимой переменной и делает оценки коэффициентов регрессии ненадёжными.