Материал: Автоматизация работы SEO-специалиста
Поисковая система в целом состоит из пяти основных программных компонентов:
. «Паук» (англ. Spider) - модуль, скачивающий страницы из сети Интернет. Он воспринимает информацию страницы в режиме исходного кода и именно в таком виде сохраняет её в базе данных.
. «Краулер» (англ. Crawler), что в переводе с английского означает «ползающий». Этот модуль ответственен за просматривание всех ссылок, имеющихся на странице и занесение их в базу данных. На основе этой информации он формирует путь, по которому будет двигаться «Паук».
. Индексатор (англ. Indexer) - данный модуль разделяет страницу на составные элементы, такие как: заголовки, подзаголовки, основной текст, жирный и курсивный шрифт, а также прочие информативные элементы. Разделив, таким образом, страницу, он проводит её анализ в зависимости от текущего алгоритма поисковой системы.
. База данных (англ. Database) - фактическое место хранения всей накопленной информации о веб-сайтах, собранной как «краулером», так и «пауком», а также результатов работы индексатора и прочей информации, необходимой для работы системы.
. Система выдачи результатов (англ. Search engine results engine) - это программный модуль, просматривающий базу данных и выбирающий наиболее релевантные запросу пользователя страницы.
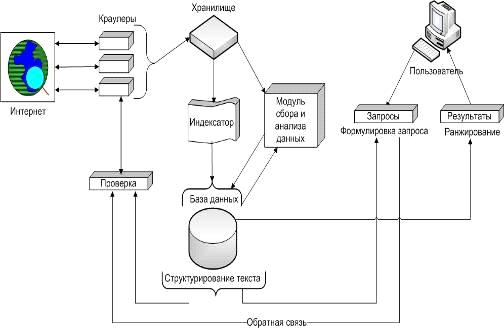
Рисунок
4 - Схема работы поисковой машины
На заре своего существования работу поисковой машины выполняли живые люди. Они просматривали все найденные ими сайты и сортировали их по каталогам. Позднее, опираясь на эту базу каталогов, поисковые машины стали осуществлять самостоятельный поиск новых страниц. Это происходит следующим образом.
Вначале «краулер» просматривает известные ему ресурсы в поиске новых ссылок. Он совершает регулярные проходы всех известных ему ссылок разыскивая при этом новые. Находя их, он выполняет по ним переход. Стоит отметить, что на каждое доменное имя «краулером» выделяется определённое время для поиска ссылок. После истечения этого времени, «краулер» отправляется дальше по сети, возвращаясь в следующем проходе.
Далее начинает свою работу модуль, называемый «пауком». Он пользуется
найденными «краулером» ссылками, как картой, и скачивает содержимое страниц в
режиме исходного кода и передаёт её для обработки индексатору. Этот модуль
разделяет текст страницы на составные элементы: заголовки, жирный и
подчёркнутый текст, выделение абзацев и прочее. Это делается для удобства
поиска по проиндексированным документам. Обработанные страницы поступают в базу
данных поисковой системы. Следует отметить, что на данный момент поисковые
роботы проводят индексацию мультимедийных данных (таких, как аудио- и
видеофайлы, флеш-анимация и прочие крайне неэффективно. Этот факт оказывает
существенное влияние на выбор методов поисковой оптимизации сайта. Ввиду этого
многие SEO-специалисты рекомендуют закрывать
программный код внутри страницы специальными HTML-тегами для предотвращения индексации.
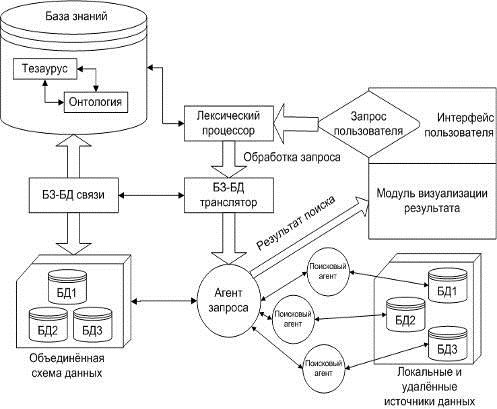
Рисунок
5 - Схема извлечения данных из поисковой машины
Неверно считать, будто поисковая машина производит поиск заданной пользователем фразы по всей сети Интернет. Скачанные в режиме исходного кода страницы хранятся в базе данных поисковой системы, а затем извлекаются, когда пользователь вводит свой запрос в поисковую строку. Работая с таким огромным объёмом информации, необходимо применять особые алгоритмы, сортирующие результаты поиска. Данные алгоритмы, постоянно обновляющиеся и дорабатывающиеся, составляют основу работы поисковой системы. Именно они определяют, какие страницы попадут на первые страницы поисковой выдачи, какие будут отображаться после десятой страницы, а какие вовсе не отобразятся для пользователя.
Не смотря на то, что поисковые системы стараются как можно чаще обновлять свои базы данных, существует множество сайтов, которые никогда не попадут в поисковую выдачу, будь то:
· ресурсы, доступ к которым защищён паролем;
· не связанные с другими сайтами ресурсы;
· сайты, представляющие из себя так называемый «информационный шум»: брошенные, незавершённые сайты;
1.2 История развития поисковой оптимизации
Период с 1997 по 1999 годы можно считать временем зарождения поисковых систем. Новые сайты добавлялись в базу данных поисковой машины вручную и сортировались по специальным тематическим каталогам. Программы индексации на тот момент были не столь совершенны и применяли лишь малое количество низкоэффективных алгоритмов ранжирования. В таких условиях недобросовестные оптимизаторы пользовались массой различных уловок и ухищрений, чтобы добиться неправомерно высокого рейтинга в глазах поисковой машины. Работа по оптимизации внутреннего содержания страниц сайта практически не проводилась, а мета-информация, заголовки, комментарии страниц, ключевые слова и множество другой служебной информации было переполнено нерелевантными, но пользовавшимися популярностью словами. Сотрудники поисковых компаний были не в силах уследить за безмерным множеством страниц и лишь со временем поисковые машины научились фильтровать недобросовестные методы держателей сайтов.
Так, к середине 1999 года, поисковые машины прибегли к технологиям поискового серфинга. Впервые была представлены технологии, позволяющие отслеживать переходы пользователей по определённым поисковым запросам, а также стало возможным отслеживать количество ресурсов, ссылающихся на ту или иную страницу в сети Интернет. Оставаясь и поныне одним из самых популярных, данный метод был назван ссылочной популярностью.
После спама мета-данных многие оптимизаторы обратились к такому сервису,
как ссылочные фермы (англ. link farm). Ввиду того,
что поисковая машина оценивает качество и количество ссылок на тот или иной
сайт, данные ресурсы предоставляли сайтам большое количество ссылок на
требуемые страницы, создавая тем самым ссылочную сеть. Не смотря на заявления,
будто данные ресурсы призваны для создания единого ссылочного пространства,
настоящая их цель была получить верхние позиции в поисковой выдаче для
определённый сайтов. В конечном итоге, поисковики научились объективно
оценивать сайт и с учётом этих методов.
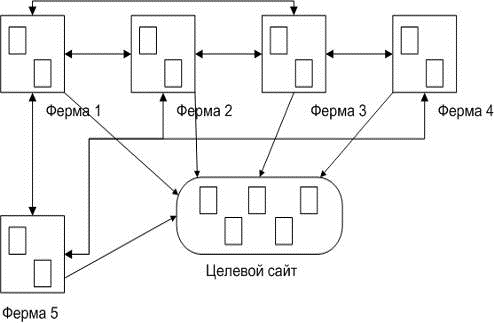
Рисунок
6 - Пример ссылочной фермы
К началу 2000-х появляется большое количество редактируемых вручную каталогов сайтов, издаваемых сообществами редакторов и собранных по различным тематикам. Данные каталоги, образовали довольно обширную ссылочную сеть с большим множеством качественных ресурсов, которые позволяют добиться довольно релевантных результатов поиска. С этого момента начинается смещение фокуса в оптимизации сайтов в сторону более качественной работы как над его внутренним содержанием, так и внешними факторами.
В настоящее время алгоритмы работы поисковых систем настолько усложнились, что они способны учитывать многие сотни факторов, влияющих на качество сайта. Если в период 1998 - 99 г. многие оптимизаторы прибегали к таким методам, как большое количество не связанных с темой сайта ключевых слов, что повышало вероятность попадания на первые страницы поисковой выдачи, то сейчас такие манипуляции невозможны. Многие поисковые системы, в том числе Google и Yandex, научились распознавать и пресекать такого рода оптимизацию. Помимо прочего, был введён лимит на длину читаемых мета-тегов и начался их анализ качества и благодаря этому верхние позиции поисковой выдачи стали более релевантными запросам пользователей. Также свою роль сыграл анализ факторов, не связанных с контентом страницы, такие как ссылочная популярность.
Следует помнить, занимаясь оптимизацией страниц сайта, что ресурсы поисковика ограничены. Поисковая система обладает своим внутренним временем, отводящимся на обработку каждой страницы, пределом глубины поиска по сайту, а также рядом других ограничений, накладываемых фактическими аппаратно-программными ресурсами. Также следует помнить, что каждая поисковая машина обладает определённым сводом правил, по которым проводится индексация. Эти правила могут иметь отличия в различных версиях поисковых алгоритмов, а также у различных поисковых систем. В зависимости от текущей версии, поисковая машина проводит индексацию и ранжирование страниц с различными результатами. Но вне зависимости от версий и самих поисковиков, все они стремятся повысить качество и разнообразие предоставляемой пользователям информации. Учитывая данную их особенность, необходимо строить собственную деятельность таким образом, чтобы повысить качество как технической, так и информационной стороны оптимизируемого сайта.
Один
из важных аспектов, на которые следует обратить внимание перед тем, как
приступить к оптимизации, - это структура сайта. Поисковые машины обрабатывают
многие миллионы веб-страниц в день, так что просматривать большое количество
вложенных страниц у них просто нет времени. Это означает, что сайты со слишком
сложной структурой будут либо индексироваться довольно долго, либо
игнорироваться поисковиком вообще. Для того, чтобы этого не произошло, следует
прибегать к вложенности не выше трёх. Например: «![]()
![]() ».
».
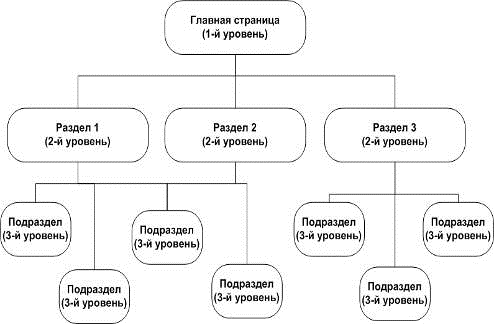
Рисунок
7 - Пример трёхуровневой структуры сайта
Другой аспект - это написание грамотного кода HTML-страниц. Это также довольно важно, так как экономит время чтения страницы для поисковика. При этом следует учитывать несколько факторов:
· все парные теги должны быть закрыты (например: <head></head>)
· не следует использовать html-теги, не поддерживаемые популярными браузерами
· не следует использовать устаревших тегов (например: <frame> или <bgsound>)
· также не стоит использовать элементы кода, которые поисковая машина ещё не умеет обрабатывать (например: некоторые теги XML)
Для того чтобы быть уверенным в качестве своего кода, необходимо следовать стандартам Консорциума Всемирной паутины (Wide Web Consortium, W3C) [10]. Приведение страницы к стандартам Консорциума не повлияет на позицию в поисковой выдаче, но облегчит работу непосредственно поисковой машины с сайтом.
.3. Основные элементы оптимизации
· Тег <title> веб-страницы. Является заголовком всей страницы и появляется в поисковой выдаче и заголовке окна браузера.
· Тег <description> веб-страницы. Отображается в результатах поиска под заголовком как краткое описание страницы. Имеет фиксированную длину, различную у разных поисковых машин и их версий.
· Тег <keywords> веб-страницы. Отвечает за то, какие ключевые запросы будут присвоены странице. По этим ключевым словам пользователями производится поиск, а поисковиками - ранжирование страниц. В настоящее время считается необязательным, так как многие поисковики научились более тщательно анализировать содержимое страницы.
· Основной текст. При этом важно учитывать плотность ключевых фраз непосредственно в тексте. Также важно, чтобы ключевые слова располагались ближе к началу текста и соответствовали его содержанию.
· Расположение текста. Важно учитывать особенности дизайна сайта и психологические аспекты пользователей для грамотного расположения текста на странице.
· Заголовки h1, h2, h3 и прочие. Указывать правильные заголовки критично, так как современные поисковые машины принимают этот аспект как важный при сканировании и ранжировании страниц.
· Различное выделение текста (полужирный, курсив, подчёркнутый текст и прочее). Данное выделение воспринимается поисковиками как важная информация. Ввиду этого рекомендуется уместное выделение текста без излишнего злоупотребления.
· Понятный URL. Для того, чтобы посетителям было комфортнее ориентироваться на сайте и для лучшего запоминания адресов, следует применять понятные человеку адреса. Например: #"791934.files/image009.jpg">
Рисунок
8 - Примеры презентации
Одним из главных условий притока посетителей на сайт в последние годы
стало использование так называемой презентации. Она являет собой теги <title> страницы и <meta> описания. Приемлемой с точки
зрения, как поисковой машины, так и человека считается презентация, несущая
информативность и соответствующая содержанию страницы. Именно основываясь на
этих факторах пользователь, вводивший запрос, обратит внимание на определённый
ресурс [8].
2. Виды работ SEO-специалиста
Деятельность SEO-специалиста в общем виде можно разделить на два вида: внешняя оптимизация и внутренняя оптимизация.
К внешней оптимизации относится работа со всевозможными ссылками, как по направлению из страницы, так и направленными на страницу.
Внутренняя оптимизация состоит из работы непосредственно со страницей, начиная от технической работы и заканчивая информационным наполнением. Можно выделить следующие направления внутренней оптимизации:
· работа над ключевыми словами;
· работа над контентом сайта;
· работа с мета-тегами страниц;
· технические работы над сайтом.
.1 Работа над ключевыми словами
Ключевым словом является слово или фраза, которую вводит в строку запроса поисковой машины пользователь. От этой фразы, помимо прочих факторов, зависит, какой набор страниц выдаст поисковик после ранжирования результатов. На данный момент ведущие поисковые системы, такие, как Google или Яндекс, учитывают в своих алгоритмах ранжирования ключевые фразы не только в соответствующих тегах веб-страницы, но и непосредственно в тексте [9].
При этом, подбирая ключевые фразы, необходимо помнить простые правила:
· Ключевая фраза должна быть точной. Пользователь, зачастую, проводя поиск в сети Интернет, ищет вполне специализированную информацию. К примеру, запрос «утюги» является слишком общим. Пользователь, скорее всего, введёт запрос «утюги с отпаривателем» или название определённой модели утюга.
· Ключевая фраза должна быть релевантной. Если на странице представлена информация о кипятильниках, а ключевые слова утверждают, что страница об утюгах, то пользователь будет введён в заблуждение и, скорее всего, покинет эту страницу почти сразу. Также это влечёт за собой санкции со стороны поисковой системы.
· Ключевая фраза должна обладать определённой плотностью. Рекомендуемая плотность является эмпирической величиной и составляет около 3-5% от общего количества слов в тексте.
Плотность ключевых слов являют собой величину, определяющую отношение ключевых слов к общему количеству текста.
Существует множество эмпирических формул для определения плотности
ключевых слов на странице. Вот некоторые из них:
![]()
![]() (1)
(1)
где P - искомая величина плотности, W - общее количество слов в тексте, K - количество ключевых слов.
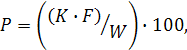 (2)
(2)
где P - искомая величина плотности, K - количество ключевых слов, F - количество ключевых фраз, W - общее количество слов в тексте.
При тексте в 700 слов рекомендуемый диапазон будет достигнут при наличии в тексте 15 ключевых фраз, состоящих из двух слов.